Pandas 秘籍 - 第一章
import pandas as pdpd.set_option('display.mpl_style', 'default') # 使图表漂亮一些figsize(15, 5)
1.1 从 CSV 文件中读取数据
您可以使用read_csv函数从CSV文件读取数据。 默认情况下,它假定字段以逗号分隔。
我们将从蒙特利尔(Montréal)寻找一些骑自行车的数据。 这是原始页面(法语),但它已经包含在此仓库中。 我们使用的是 2012 年的数据。
这个数据集是一个列表,蒙特利尔的 7 个不同的自行车道上每天有多少人。
broken_df = pd.read_csv('../data/bikes.csv')In [3]:# 查看前三行broken_df[:3]
| Date;Berri 1;Br?beuf (donn?es non disponibles);C?te-Sainte-Catherine;Maisonneuve 1;Maisonneuve 2;du Parc;Pierre-Dupuy;Rachel1;St-Urbain (donn?es non disponibles) | |
|---|---|
| 0 | 01/01/2012;35;;0;38;51;26;10;16; |
| 1 | 02/01/2012;83;;1;68;153;53;6;43; |
| 2 | 03/01/2012;135;;2;104;248;89;3;58; |
你可以看到这完全损坏了。read_csv拥有一堆选项能够让我们修复它,在这里我们:
- 将列分隔符改成
; - 将编码改为
latin1(默认为utf-8) - 解析
Date列中的日期 - 告诉它我们的日期将日放在前面,而不是月
- 将索引设置为
Date
fixed_df = pd.read_csv('../data/bikes.csv', sep=';', encoding='latin1', parse_dates=['Date'], dayfirst=True, index_col='Date')fixed_df[:3]
| Berri 1 | Brébeuf (données non disponibles) | C?te-Sainte-Catherine | Maisonneuve 1 | Maisonneuve 2 | du Parc | Pierre-Dupuy | Rachel1 | St-Urbain (données non disponibles) | |
|---|---|---|---|---|---|---|---|---|---|
| Date | |||||||||
| 2012-01-01 | 35 | NaN | 0 | 38 | 51 | 26 | 10 | 16 | NaN |
| 2012-01-02 | 83 | NaN | 1 | 68 | 153 | 53 | 6 | 43 | NaN |
| 2012-01-03 | 135 | NaN | 2 | 104 | 248 | 89 | 3 | 58 | NaN |
1.2 选择一列
当你读取 CSV 时,你会得到一种称为DataFrame的对象,它由行和列组成。 您从数据框架中获取列的方式与从字典中获取元素的方式相同。
这里有一个例子:
fixed_df['Berri 1']
Date2012-01-01 352012-01-02 832012-01-03 1352012-01-04 1442012-01-05 1972012-01-06 1462012-01-07 982012-01-08 952012-01-09 2442012-01-10 3972012-01-11 2732012-01-12 1572012-01-13 752012-01-14 322012-01-15 54...2012-10-22 36502012-10-23 41772012-10-24 37442012-10-25 37352012-10-26 42902012-10-27 18572012-10-28 13102012-10-29 29192012-10-30 28872012-10-31 26342012-11-01 24052012-11-02 15822012-11-03 8442012-11-04 9662012-11-05 2247Name: Berri 1, Length: 310, dtype: int64
1.3 绘制一列
只需要在末尾添加.plot(),再容易不过了。
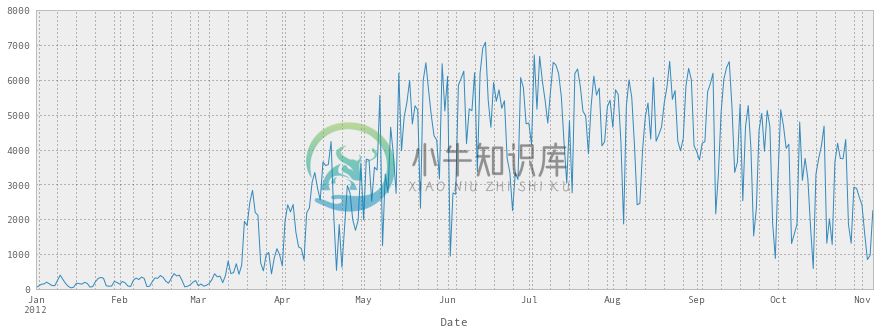
我们可以看到,没有什么意外,一月、二月和三月没有什么人骑自行车。
fixed_df['Berri 1'].plot()
<matplotlib.axes.AxesSubplot at 0x3ea1490>
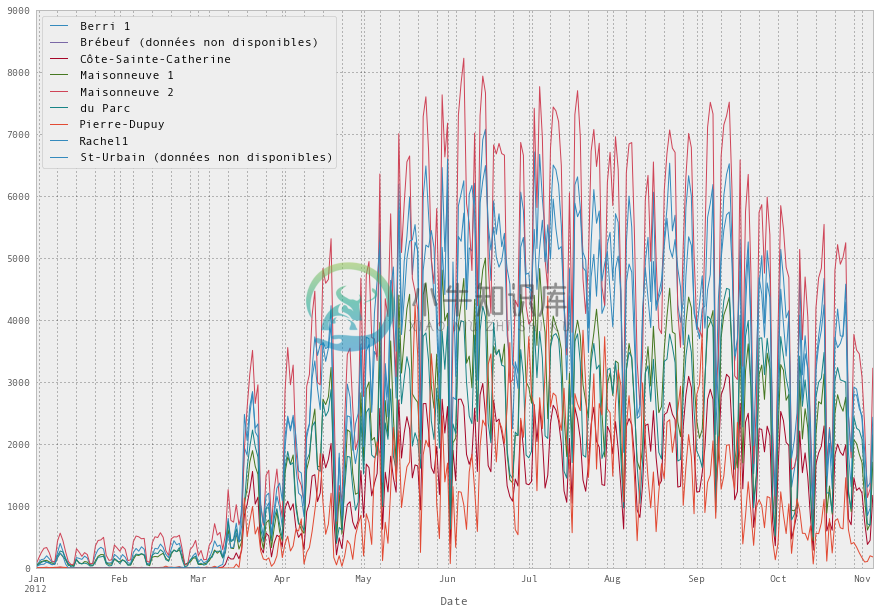
我们也可以很容易地绘制所有的列。 我们会让它更大一点。 你可以看到它挤在一起,但所有的自行车道基本表现相同 - 如果对骑自行车的人来说是一个糟糕的一天,任意地方都是糟糕的一天。
fixed_df.plot(figsize=(15, 10))
<matplotlib.axes.AxesSubplot at 0x3fc2110>
1.4 将它们放到一起
下面是我们的所有代码,我们编写它来绘制图表:
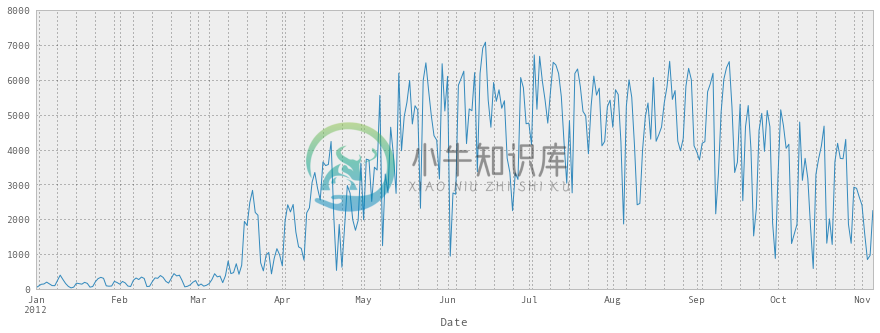
df = pd.read_csv('../data/bikes.csv', sep=';', encoding='latin1', parse_dates=['Date'], dayfirst=True, index_col='Date')df['Berri 1'].plot()
<matplotlib.axes.AxesSubplot at 0x4751750>