
第 22 章 高可用性模式
| 注意 | |
The High Availability features are only available in the Neo4j Enterprise Edition. | ||
Neo4j High Availability or “Neo4j HA” provides the following two main features:
1.It enables a fault-tolerant database architecture, where several Neo4j slave databases can be configured to be exact replicas of a single Neo4j master database. This allows the end-user system to be fully functional and both read and write to the database in the event of hardware failure.
2.It enables a horizontally scaling read-mostly architecturethat enables the system to handle more read load than a single Neo4j database instance can handle.
22.1. 架构
Neo4j HA has been designed to make the transition from single machine to multi machine operation simple, by not having to change the already existing application.
Consider an existing application with Neo4j embedded and running on a single machine. To deploy such an application in a multi machine setup the only required change is to switch the creation of the GraphDatabaseServicefrom EmbeddedGraphDatabaseto HighlyAvailableGraphDatabase. Since both implement the same interface, no additional changes are required.
图 22.1. Typical setup when running multiple Neo4j instances in HA mode
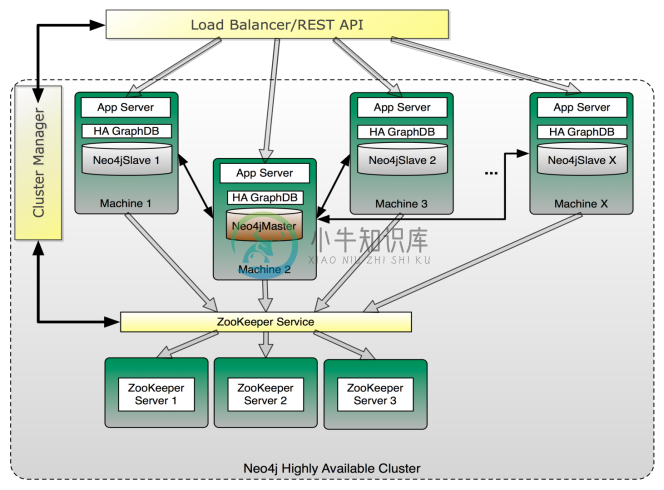
When running Neo4j in HA mode there is always a single master and zero or more slaves. Compared to other master-slave replication setups Neo4j HA can handle writes on a slave so there is no need to redirect writes to the master.
A slave will handle writes by synchronizing with the master to preserve consistency. Writes to master can be configured to be optimistically pushed to 0 or more slaves. By optimistically we mean the master will try to push to slaves before the transaction completes but if it fails the transaction will still be successful (different from normal replication factor). All updates will however propagate from the master to other slaves eventually so a write from one slave may not be immediately visible on all other slaves. This is the only difference between multiple machines running in HA mode compared to single machine operation. All other ACID characteristics are the same.
22.2. 安装和配置
Neo4j HA can be set up to accommodate differing requirements for load, fault tolerance and available hardware.
Within a cluster, Neo4j HA uses Apache ZooKeeper [2]for master election and propagation of general cluster and machine status information. ZooKeeper can be seen as a distributed coordination service. Neo4j HA requires a coordinator service for initial master election, new master election (current master failing) and to publish general status information about the current Neo4j HA cluster (for example when a server joined or left the cluster). Read operations through the GraphDatabaseServiceAPI will always work and even writes can survive coordinator failures if a master is present.
ZooKeeper requires a majority of the ZooKeeper instances to be available to operate properly. This means that the number of ZooKeeper instances should always be an odd number since that will make best use of available hardware.
To further clarify the fault tolerance characteristics of Neo4j HA here are a few example setups:
22.2.1. Small
- 3 physical (or virtual) machines
- 1 Coordinator running on each machine
- 1 Neo4j HA instance running on each machine
This setup is conservative in the use of hardware while being able to handle moderate read load. It can fully operate when at least 2 of the coordinator instances are running. Since the coordinator and Neo4j HA are running together on each machine this will in most scenarios mean that only one server is allowed to go down.
22.2.2. Medium
- 5-7+ machines
- Coordinator running on 3, 5 or 7 machines
- Neo4j HA can run on 5+ machines
This setup may mean that two different machine setups have to be managed (some machines run both coordinator and Neo4j HA). The fault tolerance will depend on how many machines there are that are running coordinators. With 3 coordinators the cluster can survive one coordinator going down, with 5 it can survive 2 and with 7 it can handle 3 coordinators failing. The number of Neo4j HA instances that can fail for normal operations is theoretically all but 1 (but for each required master election the coordinator must be available).
22.2.3. Large
- 8+ total machines
- 3+ Neo4j HA machines
- 5+ Coordinators, on separate dedicated machines
In this setup all coordinators are running on separate machines as a dedicated service. The dedicated coordinator cluster can handle half of the instances, minus 1, going down. The Neo4j HA cluster will be able to operate with at least a single live machine. Adding more Neo4j HA instances is very easy in this setup since the coordinator cluster is operating as a separate service.
22.2.4. Installation Notes
For installation instructions of a High Availability cluster see 第 22.5 节 “HA安装向导”.
Note that while the HighlyAvailableGraphDatabasesupports the same API as the EmbeddedGraphDatabase, it does have additional configuration parameters.
表 22.1. HighlyAvailableGraphDatabase configuration parameters
Parameter Name | Description | Example value | Required? |
ha.server_id | integer >= 0 and has to be unique | 1 | yes |
ha.server | (auto-discovered) host & port to bind when acting as master | my-domain.com:6001 | no |
ha.coordinators | comma delimited coordinator connections | localhost:2181,localhost:2182,localhost:2183 | yes |
ha.cluster_name | name of the cluster to participate in | neo4j.ha | no |
ha.pull_interval | interval for polling master from a slave, in seconds | 30 | no |
ha.slave_coordinator_update_mode | creates a slave-only instance that will never become a master (sync,async,none) | none | no |
ha.read_timeout | how long a slave will wait for response from master before giving up (default 20) | 20 | no |
ha.lock_read_timeout | how long a slave lock acquisition request will wait for response from master before giving up (defaults to what ha.read_timeout is, or its default if absent) | 40 | no |
ha.max_concurrent_channels_per_slave | max number of concurrent communication channels each slave has to its master. Increase if there’s high contention on few nodes | 100 | no |
ha.branched_data_policy | what to do with the db that is considered branched and will be replaced with a fresh copy from the master {keep_all(default),keep_last,keep_none,shutdown} | keep_none | no |
ha.zk_session_timeout | how long (in milliseconds) before a non reachable instance has its session expired from the ZooKeeper cluster and its ephemeral nodes removed, probably leading to a master election | 5000 | no |
ha.tx_push_factor | amount of slaves a tx will be pushed to whenever the master commits a transaction | 1 (default) | no |
ha.tx_push_strategy | either "fixed" (default) or "round_robin", fixed will push to the slaves with highest server id | fixed | no |
| 小心 | ||
Neo4j’s HA setup depends on ZooKeeper a.k.a. Coordinator which makes certain assumptions about the state of the underlying operating system. In particular ZooKeeper expects that the system time on each machine is set correctly, synchronized with respect to each other. If this is not true, then Neo4j HA will appear to misbehave, caused by seemingly random ZooKeeper hiccups. | |||
| 小心 | ||
Neo4j uses the Coordinator cluster to store information representative of the deployment’s state, including key fields of the database itself. Since that information is permanently stored in the cluster, you cannot reuse it for multiple deployments of different databases. In particular, removing the Neo4j servers, replacing the database and restarting them using the same coordinator instances will result in errors mentioning the existing HA deployment. To reset the Coordinator cluster to a clean state, you have to shutdown all instances, remove the data/coordinator/version-2/*data files and restart the Coordinators. | |||
22.3. How Neo4j HA operates
A Neo4j HA cluster operates cooperatively, coordinating activity through Zookeeper.
On startup a Neo4j HA instance will connect to the coordinator service (ZooKeeper) to register itself and ask, "who is master?" If some other machine is master, the new instance will start as slave and connect to that master. If the machine starting up was the first to register — or should become master according to the master election algorithm — it will start as master.
When performing a write transaction on a slave each write operation will be synchronized with the master (locks will be acquired on both master and slave). When the transaction commits it will first occur on the master. If the master commit is successful the transaction will be committed on the slave as well. To ensure consistency, a slave has to be up to date with the master before performing a write operation. This is built into the communication protocol between the slave and master, so that updates will happen automatically if needed.
You can make a database instance permanently slave-only by including the ha.slave_coordinator_update_mode=noneconfiguration parameter in its configuration.
Such instances will never become a master during fail-over elections though otherwise they behave identically to any other slaves, including the ability to write-through permanent slaves to the master.
When performing a write on the master it will execute in the same way as running in normal embedded mode. Currently the master will by default try to push the transaction to one slave. This is done optimistically meaning if the push fails the transaction will still be successful. This push is not like replication factor that would cause the transaction to fail. The push factor (amount of slaves to try push a transaction to) can be configured to 0 (higher write performance) and up to amount of machines available in the cluster minus one.
Slaves can also be configured to update asynchronously by setting a pull interval.
Whenever a server running a neo4j database becomes unavailable the coordinator service will detect that and remove it from the cluster. If the master goes down a new master will automatically be elected. Normally a new master is elected and started within just a few seconds and during this time no writes can take place (the write will throw an exception). A machine that becomes available after being unavailable will automatically reconnect to the cluster. The only time this is not true is when an old master had changes that did not get replicated to any other machine. If the new master is elected and performs changes before the old master recovers, there will be two different versions of the data. The old master will move away the branched database and download a full copy from the new master.
All this can be summarized as:
- Slaves can handle write transactions.
- Updates to slaves are eventual consistent but can be configured to optimistically be pushed from master during commit.
- Neo4j HA is fault tolerant and (depending on ZooKeeper setup) can continue to operate from X machines down to a single machine.
- Slaves will be automatically synchronized with the master on a write operation.
- If the master fails a new master will be elected automatically.
- Machines will be reconnected automatically to the cluster whenever the issue that caused the outage (network, maintenance) is resolved.
- Transactions are atomic, consistent and durable but eventually propagated out to other slaves.
- If the master goes down any running write transaction will be rolled back and during master election no write can take place.
- Reads are highly available.
22.4. Upgrading a Neo4j HA Cluster
22.4.2. Step 1: On each slave perform the upgrade
22.4.3. Step 2: Upgrade the master, complete the procedure
This document describes the steps required to upgrade a Neo4j cluster from a previous version to 1.8 without disrupting its operation, a process referred to as a rolling upgrade. The starting assumptions are that there exists a cluster running Neo4j version 1.5.3 or newer with the corresponding ZooKeeper instances and that the machine which is currently the master is known. It is also assumed that on each machine the Neo4j service and the neo4j coordinator service is installed under a directory which from here on is assumed to be /opt/old-neo4j
22.4.1. Overview
The process consists of upgrading each machine in turn by removing it from the cluster, moving over the database and starting it back up again. Configuration settings also have to be transferred. It is important to note that the last machine to be upgraded must be the master. In general, the "cluster version" is defined by the version of the master, providing the master is of the older version the cluster as a whole can operate (the 1.8 instances running in compatibility mode). When a 1.8 instance is elected master however, the older instances are not capable of communicating with it, so we have to make sure that the last machine upgraded is the old master. The upgrade process is detected automatically from the joining 1.8 instances and they will not participate in a master election while even a single old instance is part of the cluster.
22.4.2. Step 1: On each slave perform the upgrade
Download and unpack the new version. Copy over any configuration settings you run your instances with, taking care for deprecated settings and API changes that can occur between versions. Also, ensure that newly introduced settings have proper values (see 第 22.2 节 “安装和配置”). Apart from the files under conf/ you should also set proper values in data/coordinator/myid (copying over the file from the old instance is sufficient) The most important thing about the settings setup is the allow_store_upgrade setting in neo4j.properties which must be set to true, otherwise the instance will be unable to start. Finally, don’t forget to copy over any server plugins you may have. Shutdown first the neo4j instance and then the coordinator with
1 2 | service neo4j-service stop service neo4j-coordinator stop |
Next, uninstall both services
1 2 | service neo4j-service remove service neo4j-coordinator remove |
Now you can copy over the database. Assuming the old instance is at /opt/old-neo4j and the newly unpacked under /opt/neo4j-enterprise-1.8 the proper command would be
1 | cp -R /opt/old-neo4j/data/graph.db /opt/neo4j-enterprise-1.8/data/ |
Next install neo4j and the coordinator services, which also starts them
1 2 | /opt/neo4j-enterprise-1.8/bin/neo4j-coordinator install /opt/neo4j-enterprise-1.8/bin/neo4j install |
Done. Now check that the services are running and that webadmin reports the version 1.8. Transactions should also be applied from the master as usual.
22.4.3. Step 2: Upgrade the master, complete the procedure
Go to the current master and execute step 1 The moment it will be stopped another instance will take over, transitioning the cluster to 1.8. Finish Step 1 on this machine as well and you will have completed the process.
22.5. HA安装向导
22.5.2. Setup and start the Coordinator cluster
22.5.3. Start the Neo4j Servers in HA mode
22.5.4. Start Neo4j Embedded in HA mode
This is a guide to set up a Neo4j HA cluster and run embedded Neo4j or Neo4j Server instances participating as cluster nodes.
22.5.1. Background
The members of the HA cluster (see 第 22 章 高可用性模式) use a Coordinator cluster to manage themselves and coordinate lifecycle activity like electing a master. When running an Neo4j HA cluster, a Coordinator cluster is used for cluster collaboration and must be installed and configured before working with the Neo4j database HA instances.
| 提示 | |
Neo4j Server (see 第 17 章 Neo4j服务器) and Neo4j Embedded (see 第 21.1 节 “介绍”) can both be used as nodes in the same HA cluster. This opens for scenarios where one application can insert and update data via a Java or JVM language based application, and other instances can run Neo4j Server and expose the data via the REST API (rest-api). | ||
Below, there will be 3 coordinator instances set up on one local machine.
Download and unpack Neoj4 Enterprise
Download and unpack three installations of Neo4j Enterprise (called $NEO4J_HOME1, $NEO4J_HOME2, $NEO4J_HOME3) from the Neo4j download site.
22.5.2. Setup and start the Coordinator cluster
Now, in the NEO4J_HOME1/conf/coord.cfgfile, adjust the coordinator clientPortand let the coordinator search for other coordinator cluster members at the localhost port ranges:
1 2 3 4 5 6 7 | #$NEO4J_HOME1/conf/coord.cfg server.1=localhost:2888:3888 server.2=localhost:2889:3889 server.3=localhost:2890:3890 clientPort=2181 |
The other two config files in $NEO4J_HOME2and $NEO4J_HOME3will have a different clienttPortset but the other parameters identical to the first one:
1 2 3 4 5 6 7 | #$NEO4J_HOME2/conf/coord.cfg ... server.1=localhost:2888:3888 server.2=localhost:2889:3889 server.3=localhost:2890:3890 ... clientPort=2182 |
1 2 3 4 5 6 7 | #$NEO4J_HOME2/conf/coord.cfg ... server.1=localhost:2888:3888 server.2=localhost:2889:3889 server.3=localhost:2890:3890 ... clientPort=2183 |
Next we need to create a file in each data directory called "myid" that contains an id for each server equal to the number in server.1, server.2and server.3from the configuration files.
1 2 3 | neo4j_home1$ echo'1'> data/coordinator/myid neo4j_home2$ echo'2'> data/coordinator/myid neo4j_home3$ echo'3'> data/coordinator/myid |
We are now ready to start the Coordinator instances:
1 2 3 | neo4j_home1$ ./bin/neo4j-coordinatorstart neo4j_home2$ ./bin/neo4j-coordinatorstart neo4j_home3$ ./bin/neo4j-coordinatorstart |
22.5.3. Start the Neo4j Servers in HA mode
In your conf/neo4j.propertiesfile, enable HA by setting the necessary parameters for all 3 installations, adjusting the ha.server_idfor all instances:
1 2 3 4 5 6 7 8 9 10 | #$NEO4J_HOME1/conf/neo4j.properties #unique server id forthisgraph database #can not be negative id and must be unique ha.server_id = 1 #ip and port forthisinstance to bind to ha.server = localhost:6001 #connection information to the coordinator cluster client ports ha.coordinators = localhost:2181,localhost:2182,localhost:2183 |
1 2 3 4 5 6 7 8 9 10 | #$NEO4J_HOME2/conf/neo4j.properties #unique server id forthisgraph database #can not be negative id and must be unique ha.server_id = 2 #ip and port forthisinstance to bind to ha.server = localhost:6002 #connection information to the coordinator cluster client ports ha.coordinators = localhost:2181,localhost:2182,localhost:2183 |
1 2 3 4 5 6 7 8 9 10 | #$NEO4J_HOME3/conf/neo4j.properties #unique server id forthisgraph database #can not be negative id and must be unique ha.server_id = 3 #ip and port forthisinstance to bind to ha.server = localhost:6003 #connection information to the coordinator cluster client ports ha.coordinators = localhost:2181,localhost:2182,localhost:2183 |
To avoid port clashes when starting the servers, adjust the ports for the REST endpoints in all instances under conf/neo4j-server.propertiesand enable HA mode:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | #$NEO4J_HOME1/conf/neo4j-server.properties ... # http port (forall data, administrative, and UI access) org.neo4j.server.webserver.port=7474 ... # https port (forall data, administrative, and UI access) org.neo4j.server.webserver.https.port=7473 ... # Allowed values: # HA - High Availability # SINGLE - Single mode, default. # To run in High Availability mode, configure the coord.cfg file, and the # neo4j.properties config file, then uncomment thisline: org.neo4j.server.database.mode=HA |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | #$NEO4J_HOME2/conf/neo4j-server.properties ... # http port (forall data, administrative, and UI access) org.neo4j.server.webserver.port=7475 ... # https port (forall data, administrative, and UI access) org.neo4j.server.webserver.https.port=7472 ... # Allowed values: # HA - High Availability # SINGLE - Single mode, default. # To run in High Availability mode, configure the coord.cfg file, and the # neo4j.properties config file, then uncomment thisline: org.neo4j.server.database.mode=HA |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | #$NEO4J_HOME3/conf/neo4j-server.properties ... # http port (forall data, administrative, and UI access) org.neo4j.server.webserver.port=7476 ... # https port (forall data, administrative, and UI access) org.neo4j.server.webserver.https.port=7471 ... # Allowed values: # HA - High Availability # SINGLE - Single mode, default. # To run in High Availability mode, configure the coord.cfg file, and the # neo4j.properties config file, then uncomment thisline: org.neo4j.server.database.mode=HA |
To avoid JMX port clashes adjust the assigned ports for all instances under conf/neo4j-wrapper.properties:
1 2 3 4 5 6 7 8 | #$NEO4J_HOME1/conf/neo4j-wrapper.properties ... # Remote JMX monitoring, adjust the following lines ifneeded. # Also make sure to update the jmx.access and jmx.password files with appropriate permission roles and passwords, # the shipped configuration contains only a read only role called 'monitor'with password 'Neo4j'. # For more details, see: http://download.oracle.com/javase/6/docs/technotes/guides/management/agent.html wrapper.java.additional.4=-Dcom.sun.management.jmxremote.port=3637 ... |
1 2 3 4 5 6 7 8 | #$NEO4J_HOME2/conf/neo4j-wrapper.properties ... # Remote JMX monitoring, adjust the following lines ifneeded. # Also make sure to update the jmx.access and jmx.password files with appropriate permission roles and passwords, # the shipped configuration contains only a read only role called 'monitor'with password 'Neo4j'. # For more details, see: http://download.oracle.com/javase/6/docs/technotes/guides/management/agent.html wrapper.java.additional.4=-Dcom.sun.management.jmxremote.port=3638 ... |
1 2 3 4 5 6 7 8 | #$NEO4J_HOME3/conf/neo4j-server.properties ... # Remote JMX monitoring, adjust the following lines ifneeded. # Also make sure to update the jmx.access and jmx.password files with appropriate permission roles and passwords, # the shipped configuration contains only a read only role called 'monitor'with password 'Neo4j'. # For more details, see: http://download.oracle.com/javase/6/docs/technotes/guides/management/agent.html wrapper.java.additional.4=-Dcom.sun.management.jmxremote.port=3639 ... |
Now, start all three server instances.
1 2 3 | neo4j_home1$ ./bin/neo4jstart neo4j_home2$ ./bin/neo4jstart neo4j_home3$ ./bin/neo4jstart |
Now, you should be able to access the 3 servers (the first one being elected as master since it was started first) at http://localhost:7474/webadmin/#/info/org.neo4j/High%20Availability/, http://localhost:7475/webadmin/#/info/org.neo4j/High%20Availability/and http://localhost:7476/webadmin/#/info/org.neo4j/High%20Availability/and check the status of the HA configuration. Alternatively, the REST API is exposing JMX, so you can check the HA JMX bean with e.g.
1 | curl -H "Content-Type:application/json"-d '["org.neo4j:*"]'http://localhost:7474/db/manage/server/jmx/query |
And find in the response
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | "description": "Information about all instances in this cluster", "name": "InstancesInCluster", "value": [ { "description": "org.neo4j.management.InstanceInfo", "value": [ { "description": "address", "name": "address" }, { "description": "instanceId", "name": "instanceId" }, { "description": "lastCommittedTransactionId", "name": "lastCommittedTransactionId", "value": 1 }, { "description": "machineId", "name": "machineId", "value": 1 }, { "description": "master", "name": "master", "value": true } ], "type": "org.neo4j.management.InstanceInfo" } |
22.5.4. Start Neo4j Embedded in HA mode
If you are using Maven and Neo4j Embedded, simply add the following dependency to your project:
1 2 3 4 5 | <dependency> <groupId>org.neo4j</groupId> <artifactId>neo4j-ha</artifactId> <version>${neo4j-version}</version> </dependency> |
Where ${neo4j-version}is the Neo4j version used.
If you prefer to download the jar files manually, they are included in the Neo4j distribution.
The difference in code when using Neo4j-HA is the creation of the graph database service.
1 | GraphDatabaseService db = newHighlyAvailableGraphDatabase( path, config ); |
The configuration can contain the standard configuration parameters (provided as part of the configabove or in neo4j.propertiesbut will also have to contain:
1 2 3 4 5 6 7 8 9 10 11 12 | #HA instance1 #unique machine id forthisgraph database #can not be negative id and must be unique ha.server_id = 1 #ip and port forthisinstance to bind to ha.server = localhost:6001 #connection information to the coordinator cluster client ports ha.coordinators = localhost:2181,localhost:2182,localhost:2183 enable_remote_shell = port=1331 |
First we need to create a database that can be used for replication. This is easiest done by just starting a normal embedded graph database, pointing out a path and shutdown.
1 2 | Map<String,String> config = HighlyAvailableGraphDatabase.loadConfigurations( configFile ); GraphDatabaseService db = newHighlyAvailableGraphDatabase( path, config ); |
We created a config file with machine id=1 and enabled remote shell. The main method will expect the path to the db as first parameter and the configuration file as the second parameter.
It should now be possible to connect to the instance using 第 27 章 Neo4j命令行:
1 2 3 4 5 6 7 | neo4j_home1$ ./bin/neo4j-shell-port 1331 NOTE: Remote Neo4j graph database service 'shell'at port 1331 Welcome to the Neo4j Shell! Enter 'help'fora list of commands neo4j-sh (0)$ hainfo I'm currently master Connected slaves: |
Since it is the first instance to join the cluster it is elected master. Starting another instance would require a second configuration and another path to the db.
1 2 3 4 5 6 7 8 9 10 11 12 | #HA instance2 #unique machine id forthisgraph database #can not be negative id and must be unique ha.server_id = 2 #ip and port forthisinstance to bind to ha.server = localhost:6001 #connection information to the coordinator cluster client ports ha.coordinators = localhost:2181,localhost:2182,localhost:2183 enable_remote_shell = port=1332 |
Now start the shell connecting to port 1332:
1 2 3 4 5 6 | neo4j_home1$ ./bin/neo4j-shell-port 1332 NOTE: Remote Neo4j graph database service 'shell'at port 1332 Welcome to the Neo4j Shell! Enter 'help'fora list of commands neo4j-sh (0)$ hainfo I'm currently slave |
22.6. 安装HAProxy作为一个负载均衡器
22.6.3. Configuring separate sets for master and slaves
22.6.4. Cache-based sharding with HAProxy
In the Neo4j HA architecture, the cluster is typically fronted by a load balancer. In this section we will explore how to set up HAProxy to perform load balancing across the HA cluster.
22.6.1. Installing HAProxy
For this tutorial we will assume a Linux environment. We will also be installing HAProxy from source, and we’ll be using version 1.4.18. You need to ensure that your Linux server has a development environment set up. On Ubuntu/apt systems, simply do:
1 | aptitude installbuild-essential |
And on CentOS/yum systems do:
1 | yum -y groupinstall 'Development Tools' |
Then download the tarball from the HAProxy website. Once you’ve downloaded it, simply build and install HAProxy:
1 2 3 4 | tar-zvxf haproxy-1.4.18.tar.gz cdhaproxy-1.4.18 make cphaproxy /usr/sbin/haproxy |
Or specify a target for make (TARGET=linux26 for linux kernel 2.6 or above or linux24 for 2.4 kernel)
1 2 3 4 | tar-zvxf haproxy-1.4.18.tar.gz cdhaproxy-1.4.18 makeTARGET=linux26 cphaproxy /usr/sbin/haproxy |
22.6.2. Configuring HAProxy
HAProxy can be configured in many ways. The full documentation is available at their website.
For this example, we will configure HAProxy to load balance requests to three HA servers. Simply write the follow configuration to /etc/haproxy.cfg:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | global daemon maxconn 256 defaults mode http timeout connect 5000ms timeout client 50000ms timeout server 50000ms frontend http-in bind *:80 default_backend neo4j backend neo4j server s1 10.0.1.10:7474maxconn 32 server s2 10.0.1.11:7474maxconn 32 server s3 10.0.1.12:7474maxconn 32 listen admin bind *:8080 stats enable |
HAProxy can now be started by running:
1 | /usr/sbin/haproxy-f /etc/haproxy.cfg |
You can connect to <a href="http://:8080/haproxy?stats" >http://<ha-proxy-ip>:8080/haproxy?statsto view the status dashboard. This dashboard can be moved to run on port 80, and authentication can also be added. See the HAProxy documentation for details on this.
22.6.3. Configuring separate sets for master and slaves
It is possible to set HAProxy backends up to only include slaves or the master. For example, it may be desired to only write to slaves. To accomplish this, you need to have a small extension on the server than can report whether or not the machine is master via HTTP response codes. In this example, the extension exposes two URLs:
- /hastatus/master, which returns 200 if the machine is the master, and 404 if the machine is a slave
- /hastatus/slave, which returns 200 if the machine is a slave, and 404 if the machine is the master
The following example excludes the master from the set of machines. Request will only be sent to the slaves.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | global daemon maxconn 256 defaults mode http timeout connect 5000ms timeout client 50000ms timeout server 50000ms frontend http-in bind *:80 default_backend neo4j-slaves backend neo4j-slaves option httpchk GET /hastatus/slave server s1 10.0.1.10:7474maxconn 32check server s2 10.0.1.11:7474maxconn 32check server s3 10.0.1.12:7474maxconn 32check listen admin bind *:8080 stats enable |
22.6.4. Cache-based sharding with HAProxy
Neo4j HA enables what is called cache-based sharding. If the dataset is too big to fit into the cache of any single machine, then by applying a consistent routing algorithm to requests, the caches on each machine will actually cache different parts of the graph. A typical routing key could be user ID.
In this example, the user ID is a query parameter in the URL being requested. This will route the same user to the same machine for each request.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | global daemon maxconn 256 defaults mode http timeout connect 5000ms timeout client 50000ms timeout server 50000ms frontend http-in bind *:80 default_backend neo4j-slaves backend neo4j-slaves balance url_param user_id server s1 10.0.1.10:7474maxconn 32 server s2 10.0.1.11:7474maxconn 32 server s3 10.0.1.12:7474maxconn 32 listen admin bind *:8080 stats enable |
Naturally the health check and query parameter-based routing can be combined to only route requests to slaves by user ID. Other load balancing algorithms are also available, such as routing by source IP (source), the URI (uri) or HTTP headers(hdr()).