
Neo是一个网络——面向网络的数据库——也就是说,它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络上而不是表中。网络(从数学角度叫做图)是一个灵活的数据结构,可以应用更加敏捷和快速的开发模式。
你可以把Neo看作是一个高性能的图引擎,该引擎具有成熟和健壮的数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
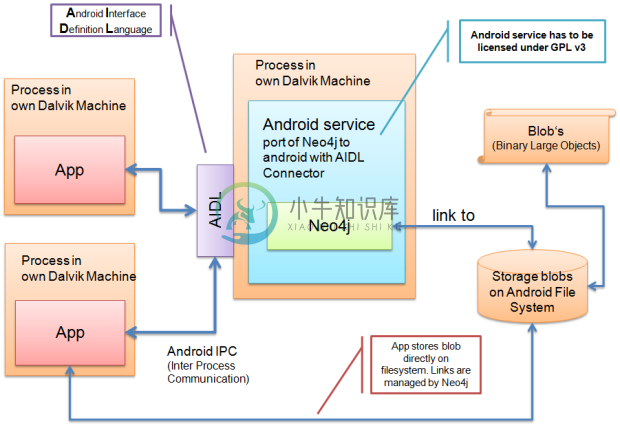
-
一、Neo4j和图数据库简介 neo4j是基于Java语言编写图形数据库。图是一组节点和连接这些节点的关系。图形数据库也被称为图形数据库管理系统或GDBMS。 Neo4j的是一种流行的图形数据库。 其他的图形数据库是Oracle NoSQL数据库,OrientDB,HypherGraphDB,GraphBase,InfiniteGraph,AllegroGraph。 Neo4j图形数据库的主要构建
-
在我的Neo4j/SDN 4应用程序中,我的所有密码查询都基于内部Neo4j ID。 这是一个问题,因为我不能在我的web应用程序URL上依赖这些ID。Neo4j可以重用这些ID,因此很有可能在将来的某个时候,在相同的ID下,我们可以找到另一个节点。 我尝试基于以下解决方案重新实现此逻辑:使用图控制唯一id的生成,但发现查询性能下降。 从理论上看,基于)属性的密码查询是否应该 例如: 与基于内部N
-
我有Neo4J3.3.5图形数据库:27GB,50KK节点,500KK关系。索引打开。模式。个人电脑:16GB内存,4个核心。 由于缺少后联合处理,我使用+来合并所有关系的分数。 不幸的是,性能较低。我在5-10秒内得到一个关系(如上)查询的响应。当我试图将结果与+组合时,查询“never”结束。 做这件事的更好/正确的方法是什么?也许我在图形设计上做错了什么?硬件配置到低?或者也许有一些算法可以
-
问题内容: 问候, 除了Neo4J之外 , 是否有任何可用的开源图形数据库? 注意: 为什么不选择Neo4J? Neo4J是开源的,但是可以计算基元(节点数,关系和属性)。如果您将其用于商业用途。并且在官方网站上没有任何直接的定价信息。因此可能存在潜在的供应商锁定(尽管我刚成立我的公司,而且没有预算在软件上花钱。)所以这是不可行的。 问候, 问题答案: 如RobV所说,如果您的图形几乎可以以任何自
-
有没有用Cypher编写递归查询的方法?我必须遍历从一组节点(带有标签)到另一组节点的所有路径。该图是定向的,并且有多个路径,如 递归查询必须概述此伪代码 这个问题的解决方案不一定是递归的。任何其他解决方案都将受到赞赏。 编辑:在查询开始之前,根据需要将设置为一些值。并且图中的所有其他节点(例如)都有它们的。 有多个定向路径,如。对于这些路径中的每个节点(m,n,o,..)-[*]->y-->x-
-
问题内容: 我需要一些想法来实现Java的(真正)高性能内存数据库/存储机制。在存储20,000+个Java对象的范围内,每5秒钟左右更新一次。 我愿意接受的一些选择: 纯JDBC /数据库组合 JDO JPA / ORM /数据库组合 对象数据库 其他存储机制 我最好的选择是什么?你有什么经验? 编辑:我还需要能够查询这些对象 问题答案: 您可以尝试使用Prevayler之类的工具(基本上是一个
-
我是Spring data neo4j的新手,我对GraphRepository有一些错误/问题。 我第一次有了这个: 但是阅读一些文档,存储库已经提供了这样的方法。我不需要写它们。 这是我的产品域名。 这是我的实验班 未检测到查找字节 Id 这正常吗? 这是我的pom.xml
-
问题内容: 我在公司中多次设计数据库。为了提高数据库的性能,我只寻找标准化和索引。 如果要求您提高数据库的性能,该数据库包含大约250个表以及一些具有数百万个记录的表,那么您将寻找什么不同的东西? 提前致谢。 问题答案: 优化逻辑设计 逻辑级别是关于查询和表本身的结构。首先尝试最大程度地发挥这一作用。目标是在逻辑级别上访问尽可能少的数据。 拥有最高效的SQL查询 设计支持应用程序需求的逻辑架构(例
-
本文向大家介绍NoSQL数据库,包括了NoSQL数据库的使用技巧和注意事项,需要的朋友参考一下 这些用于大型分布式数据集。关系数据库可以有效地处理一些大数据性能问题,而NoSQL数据库可以轻松解决此类问题。在分析可能存储在云的多个虚拟服务器上的大型非结构化数据时,非常有效。