
第 4 章 在 Java 应用中使用 Neo4j
在Java中采用嵌入方式使用Neo4j是非常方便的。在这个章节中,你将找到所有你想了解的 — 从基本环境的搭建到用你的数据做一些实际有用的事情。
在Java应用中使用Neo4j是非常容易的。正这个章节中你将找到你需要的一切 — 从开发环境的建立到用你的数据做一些有用的事情。
4.1. 将Neo4j引入到你的项目工程中
在选择了适合你的平台的editions,edition后,只需要引入Neo4j的jars 文件到你的工程的构造路径中,你就可以在你的工程中使用Neo4j数据库了。下面的章节将展示如何完成引入,要么通过直接改变构造路径,要么使用包依赖管理。
4.1.1. 增加Neo4j的库文件到构造路径中
可以通过下面任意一种方式得到需要的jar文件:
- 解压 Neo4j 下载的压缩包,我们需要使用的jars文件都包括在lib目录中。
- 直接使用Maven中心仓库的jars文件。
将jars引入到你的项目工程中:
JDK tools
增加到 -classpath中
Eclipse
- 右键点击工程然后选择 Build Path → Configure Build Path。在对话框中选择 Add External JARs,浏览到Neo4j的'lib/'目录并选择所有的jar文件。
- 另外一种方式是使用 User Libraries。
IntelliJ IDEA
看 Libraries, Global Libraries, and the Configure Library dialog了解详情。
NetBeans
- 在工程的 Libraries点击鼠标右键,选择 Add JAR/Folder,浏览到Neo4j的'lib/'目录选择里面的所有jar文件。
- 你也可以从工程节点来管理库文件。详细情况请查看管理一个工程的classpath。
4.1.2. 将Neo4j作为一个依赖添加
想总览一下主要的Neo4j构件,请查看editions。列在里面的构件都是包含实际Neo4j实现的顶级构件。
你既可以使用顶级构件也可以直接引入单个的组件。在这的范例使用的是顶级构件的方式。
Maven
Maven dependency.
1 2 3 4 5 6 7 8 9 10 11 12 | <project> ... <dependencies> <dependency> <groupId>org.neo4j</groupId> <artifactId>neo4j</artifactId> <version>1.8</version> </dependency> ... </dependencies> ... </project> |
参数 artifactId可以在 editions 找到。
Eclipse and Maven
在Eclipse中开发,推荐安装插件m2e plugin让Maven管理classpath来代替上面的方案。
这样的话,你既可以通过Maven命令行来编译你的工程,也可以通过Maven命令自动生成一个Eclipse工作环境以便进行开发。
Ivy
确保能解决来自Maven Central的依赖问题,比如我们在你的'ivysettings.xml'文件中使用下面的配置选项:
1 2 3 4 5 6 7 8 9 10 11 | <ivysettings> <settingsdefaultResolver="main"/> <resolvers> <chainname="main"> <filesystemname="local"> <artifactpattern="${ivy.settings.dir}/repository/[artifact]-[revision].[ext]"/> </filesystem> <ibiblioname="maven_central"root="http://repo1.maven.org/maven2/"m2compatible="true"/> </chain> </resolvers> </ivysettings> |
有了这个,你就可以通过增加下面这些内容到你的'ivy.xml'中来引入Neo4j:
1 2 3 4 5 6 7 | .. <dependencies> .. <dependencyorg="org.neo4j"name="neo4j"rev="1.8"/> .. </dependencies> .. |
参数 name可以在editions找到。
Gradle
下面的范例演示了用Gradle生成一个脚本来引入Neo4j库文件。
1 2 3 4 5 6 7 8 | defneo4jVersion = "1.8" apply plugin: 'java' repositories { mavenCentral() } dependencies { compile "org.neo4j:neo4j:${neo4jVersion}" } |
参数 coordinates(在范例中的 org.neo4j:neo4j) 可以在editions找到。
4.1.3. 启动和停止
为了创建一个新的数据库或者打开一个已经存在的,你需要实例化一个+EmbeddedGraphDatabase+对象。
1 2 | graphDb = newGraphDatabaseFactory().newEmbeddedDatabase( DB_PATH ); registerShutdownHook( graphDb ); | ||
| 注意 | ||
EmbeddedGraphDatabase实例可以在多个线程中共享。然而你不能创建多个实例来指向同一个数据库。 | |||
为了停止数据库,你需要调用方法 shutdown():
1 | graphDb.shutdown(); |
为了确保Neo4j被正确关闭,你可以为它增加一个关闭钩子方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | privatestaticvoidregisterShutdownHook( finalGraphDatabaseService graphDb ) { // Registers a shutdown hook for the Neo4j instance so that it // shuts down nicely when the VM exits (even if you "Ctrl-C" the // running example before it's completed) Runtime.getRuntime().addShutdownHook( newThread() { @Override publicvoidrun() { graphDb.shutdown(); } } ); } |
如果你只想通过 只读方式浏览数据库,请使用 EmbeddedReadOnlyGraphDatabase。
想通过配置设置来启动Neo4j,一个Neo4j属性文件可以像下面这样加载:
1 2 3 4 | GraphDatabaseService graphDb = newGraphDatabaseFactory(). newEmbeddedDatabaseBuilder( "target/database/location"). loadPropertiesFromFile( pathToConfig + "neo4j.properties"). newGraphDatabase(); |
或者你可以编程创建你自己的 Map<String, String>来代替。
想了解更多配置设置的细节,请参考:embedded-configuration。
4.2. 你好,世界
正这里可以学习如何创建和访问节点和关系。关于建立工程环境的信息,请参考:第 4.1 节 “将Neo4j引入到你的项目工程中”。
从第 2.1 节 “什么是图数据库?”中,我们还记得,一个Neo4j图数据库由以下几部分组成:
- 相互关联的节点
- 有一定的关系存在
- 在节点和关系上面有一些属性。
所有的关系都有一个类型。比如,如果一个图数据库实例表示一个社网络,那么一个关系类型可能叫 KNOWS。
如果一个类型叫 KNOWS的关系连接了两个节点,那么这可能表示这两个人呼吸认识。一个图数据库中大量的语义都被编码成关系的类型来使用。虽然关系是直接相连的,但他们也可以不用考虑他们遍历的方向而互相遍历对方。
| 提示 |
范例源代码下载地址: EmbeddedNeo4j.java |

4.2.1. 准备图数据库
关系类型可以通过 enum创建。正这个范例中我们之需要一个单独的关系类型。下面是我们的定义:
1 2 3 4 | privatestaticenumRelTypes implementsRelationshipType { KNOWS } |
我们页准备一些需要用到的参数:
1 2 3 4 | GraphDatabaseService graphDb; Node firstNode; Node secondNode; Relationship relationship; |
下一步将启动数据库服务器了。逐一如果给定的保持数据库的目录如果不存在,那么它会自动创建。
1 2 | graphDb = newGraphDatabaseFactory().newEmbeddedDatabase( DB_PATH ); registerShutdownHook( graphDb ); |
注意:启动一个图数据库是一个非常重(耗费资源)的操作,所以不要每次你需要与数据库进行交互操作时都去启动一个新的实例。这个实例可以被多个线程共享。事务是线程安全的。
就像你上面所看到的一样,我们注册了一个关闭数据库的钩子用来确保在JVM退出时数据库已经被关闭。现在是时候与数据库进行交互了。
4.2.2. 在一个事务中完成多次写数据库操作
所有的写操作(创建,删除以及更新)都是在一个事务中完成的。这是一个有意的设计,因为我们相信事务是使用一个企业级数据库中非常重要的一部分。现在,在Neo4j中的事务处理是非常容易的:
1 2 3 4 5 6 7 8 9 10 | Transaction tx = graphDb.beginTx(); try { // Updating operations go here tx.success(); } finally { tx.finish(); } |
要了解更多关于事务的细节,请参考:transactions 和 Java API中的事务接口。
4.2.3. 创建一个小型图数据库
现在,让我们来创建一些节点。 API是非常直观的。你也随意查看在 http://components.neo4j.org/neo4j/1.8/apidocs/的JavaDocs文档。它们也被包括正发行版中。这儿展示了如何创建一个小型图数据库,数据库中包括两个节点并用一个关系相连,节点和关系还包括一些属性:
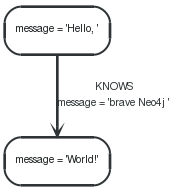
1 2 3 4 5 6 7 | firstNode = graphDb.createNode(); firstNode.setProperty( "message", "Hello, "); secondNode = graphDb.createNode(); secondNode.setProperty( "message", "World!"); relationship = firstNode.createRelationshipTo( secondNode, RelTypes.KNOWS ); relationship.setProperty( "message", "brave Neo4j "); |
现在我们有一个图数据库看起来像下面这样:
图 4.1. Hello World 图数据库
4.2.4. 打印结果
在我们创建我们的图数据库后,让我们从中读取数据并打印结果。
1 2 3 | System.out.print( firstNode.getProperty( "message") ); System.out.print( relationship.getProperty( "message") ); System.out.print( secondNode.getProperty( "message") ); |
输出结果:
Hello, brave Neo4j World!
4.2.5. 移除数据
在这种情况下我们将在提交之前移除数据:
1 2 3 4 | // let's remove the data firstNode.getSingleRelationship( RelTypes.KNOWS, Direction.OUTGOING ).delete(); firstNode.delete(); secondNode.delete(); |
注意删除一个仍然有关系的节点,当事务提交是会失败。这是为了确保关系始终有一个开始节点和结束节点。
4.2.6. 关闭图数据库
最后,当应用完成后关闭数据库:
1 | graphDb.shutdown(); |
4.3. 带索引的用户数据库
你有一个用户数据库,希望通过名称查找到用户。首先,下面这是我们想创建的数据库结构:
图 4.2. 用户节点空间预览
 其中,参考节点连接了一个用户参考节点,而真实的所有用户都连接在用户参考节点上面。
其中,参考节点连接了一个用户参考节点,而真实的所有用户都连接在用户参考节点上面。
| 提示 |
范例中的源代码下载地址: EmbeddedNeo4jWithIndexing.java |
首先,我们定义要用到的关系类型:
1 2 3 4 5 | privatestaticenumRelTypes implementsRelationshipType { USERS_REFERENCE, USER } |
然后,我们创建了两个辅助方法来处理用户名称以及往数据库新增用户:
1 2 3 4 5 6 7 8 9 10 11 12 | privatestaticString idToUserName( finalintid ) { return"user"+ id + "@neo4j.org"; } privatestaticNode createAndIndexUser( finalString username ) { Node node = graphDb.createNode(); node.setProperty( USERNAME_KEY, username ); nodeIndex.add( node, USERNAME_KEY, username ); returnnode; } |
下一步我们将启动数据库:
1 2 3 | graphDb = newGraphDatabaseFactory().newEmbeddedDatabase( DB_PATH ); nodeIndex = graphDb.index().forNodes( "nodes"); registerShutdownHook(); |
是时候新增用户了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | Transaction tx = graphDb.beginTx(); try { // Create users sub reference node Node usersReferenceNode = graphDb.createNode(); graphDb.getReferenceNode().createRelationshipTo( usersReferenceNode, RelTypes.USERS_REFERENCE ); // Create some users and index their names with the IndexService for( intid = 0; id < 100; id++ ) { Node userNode = createAndIndexUser( idToUserName( id ) ); usersReferenceNode.createRelationshipTo( userNode, RelTypes.USER ); } |
通过Id查找用户:
1 2 3 4 5 | intidToFind = 45; Node foundUser = nodeIndex.get( USERNAME_KEY, idToUserName( idToFind ) ).getSingle(); System.out.println( "The username of user "+ idToFind + " is " + foundUser.getProperty( USERNAME_KEY ) ); |
4.4. 基本的单元测试
Neo4j的单元测试的基本模式通过下面的范例来阐释。
要访问Neo4j测试功能,你应该把neo4j-kernel'tests.jar'新增到你的类路径中。你可以从Maven Central: org.neo4j:neo4j-kernel下载到需要的jars。
使用Maven作为一个依赖管理,你通常会正pom.xml中增加依赖配置:
Maven 依赖.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | <project> ... <dependencies> <dependency> <groupId>org.neo4j</groupId> <artifactId>neo4j-kernel</artifactId> <version>${neo4j-version}</version> <type>test-jar</type> <scope>test</scope> </dependency> ... </dependencies> ... </project> |
_ ${neo4j-version}是Neo4j的版本号。_
到此,我们已经准备好进行单元测试编码了。
| 提示 |
范例源代码下载地址: Neo4jBasicTest.java |
每一次开始单元测试之前,请创建一个干净的数据库:
1 2 3 4 5 | @Before publicvoidprepareTestDatabase() { graphDb = newTestGraphDatabaseFactory().newImpermanentDatabaseBuilder().newGraphDatabase(); } |
在测试完成之后,请关闭数据库:
1 2 3 4 5 | @After publicvoiddestroyTestDatabase() { graphDb.shutdown(); } |
在测试期间,创建节点并检查它们是否存在,并在一个事务中结束写操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | Transaction tx = graphDb.beginTx(); Node n = null; try { n = graphDb.createNode(); n.setProperty( "name", "Nancy"); tx.success(); } catch( Exception e ) { tx.failure(); } finally { tx.finish(); } // The node should have an id greater than 0, which is the id of the // reference node. assertThat( n.getId(), is( greaterThan( 0l ) ) ); // Retrieve a node by using the id of the created node. The id's and // property should match. Node foundNode = graphDb.getNodeById( n.getId() ); assertThat( foundNode.getId(), is( n.getId() ) ); assertThat( (String) foundNode.getProperty( "name"), is( "Nancy") ); |
如果你想查看创建数据库的参数配置,你可以这样:
1 2 3 4 5 | Map<String, String> config = newHashMap<String, String>(); config.put( "neostore.nodestore.db.mapped_memory", "10M"); config.put( "string_block_size", "60"); config.put( "array_block_size", "300"); GraphDatabaseService db = newImpermanentGraphDatabase( config ); |
4.5. 遍历查询
了解更多关于遍历查询的信息,请参考:tutorial-traversal。
了解更多关于遍历查询范例的信息,请参考:第 7 章 数据模型范例。
4.5.1. 黑客帝国
对于上面的黑客帝国范例的遍历查询,这次使用新的遍历API:
| 提示 |
范例源代码下载地址: NewMatrix.java |

朋友以及朋友的朋友.
1 2 3 4 5 6 7 8 9 | privatestaticTraverser getFriends( finalNode person ) { TraversalDescription td = Traversal.description() .breadthFirst() .relationships( RelTypes.KNOWS, Direction.OUTGOING ) .evaluator( Evaluators.excludeStartPosition() ); returntd.traverse( person ); } |
让我们只想一次真实的遍历查询并打印结果:
1 2 3 4 5 6 7 8 9 10 11 | intnumberOfFriends = 0; String output = neoNode.getProperty( "name") + "'s friends:\n"; Traverser friendsTraverser = getFriends( neoNode ); for( Path friendPath : friendsTraverser ) { output += "At depth "+ friendPath.length() + " => " + friendPath.endNode() .getProperty( "name") + "\n"; numberOfFriends++; } output += "Number of friends found: "+ numberOfFriends + "\n"; |
输出结果:
1 2 3 4 5 6 | Thomas Anderson's friends: At depth 1=> Trinity At depth 1=> Morpheus At depth 2=> Cypher At depth 3=> Agent Smith 找到朋友的数量: 4 |
谁编写了黑客帝国?.
1 2 3 4 5 6 7 8 9 10 | privatestaticTraverser findHackers( finalNode startNode ) { TraversalDescription td = Traversal.description() .breadthFirst() .relationships( RelTypes.CODED_BY, Direction.OUTGOING ) .relationships( RelTypes.KNOWS, Direction.OUTGOING ) .evaluator( Evaluators.includeWhereLastRelationshipTypeIs( RelTypes.CODED_BY ) ); returntd.traverse( startNode ); } |
打印输出结果:
1 2 3 4 5 6 7 8 9 10 11 | String output = "Hackers:\n"; intnumberOfHackers = 0; Traverser traverser = findHackers( getNeoNode() ); for( Path hackerPath : traverser ) { output += "At depth "+ hackerPath.length() + " => " + hackerPath.endNode() .getProperty( "name") + "\n"; numberOfHackers++; } output += "Number of hackers found: "+ numberOfHackers + "\n"; |
现在我们知道是谁编写了黑客帝国:
1 2 3 | Hackers: At depth 4=> The Architect 找到hackers的数量: 1 |
游走一个有序路径
这个范例展示了如何通过一个路径上下文控制一条路径的表现。
| 提示 | ||
范例源代码下载地址: OrderedPath.java |

创建一个图数据库.
1 2 3 4 5 6 7 8 | Node A = db.createNode(); Node B = db.createNode(); Node C = db.createNode(); Node D = db.createNode(); A.createRelationshipTo( B, REL1 ); B.createRelationshipTo( C, REL2 ); C.createRelationshipTo( D, REL3 ); A.createRelationshipTo( C, REL2 ); |

现在,关系 ( REL1→ REL2→ REL3) 的顺序保存在 一个 ArrayList对象中。当遍历的时候,Evaluator能针对它进行检查,确保只有拥有预定义关系顺序的路径才会被包括并返回:
定义如何游走这个路径.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | finalArrayList<RelationshipType> orderedPathContext = newArrayList<RelationshipType>(); orderedPathContext.add( REL1 ); orderedPathContext.add( withName( "REL2") ); orderedPathContext.add( withName( "REL3") ); TraversalDescription td = Traversal.description() .evaluator( newEvaluator() { @Override publicEvaluation evaluate( finalPath path ) { if( path.length() == 0) { returnEvaluation.EXCLUDE_AND_CONTINUE; } RelationshipType expectedType = orderedPathContext.get( path.length() - 1); booleanisExpectedType = path.lastRelationship() .isType( expectedType ); booleanincluded = path.length() == orderedPathContext.size() && isExpectedType; booleancontinued = path.length() < orderedPathContext.size() && isExpectedType; returnEvaluation.of( included, continued ); } } ); |
执行一次遍历查询并返回结果.
1 2 3 4 5 6 | Traverser traverser = td.traverse( A ); PathPrinter pathPrinter = newPathPrinter( "name"); for( Path path : traverser ) { output += Traversal.pathToString( path, pathPrinter ); } |
输出结果:
1 | (A)--[REL1]-->(B)--[REL2]-->(C)--[REL3]-->(D) |
在这种情况下我们使用一个自定义类来格式化路径输出。下面是它的具体实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | staticclassPathPrinter implementsTraversal.PathDescriptor<Path> { privatefinalString nodePropertyKey; publicPathPrinter( String nodePropertyKey ) { this.nodePropertyKey = nodePropertyKey; } @Override publicString nodeRepresentation( Path path, Node node ) { return"("+ node.getProperty( nodePropertyKey, "") + ")"; } @Override publicString relationshipRepresentation( Path path, Node from, Relationship relationship ) { String prefix = "--", suffix = "--"; if( from.equals( relationship.getEndNode() ) ) { prefix = "<--"; } else { suffix = "-->"; } returnprefix + "["+ relationship.getType().name() + "]"+ suffix; } } |
为了了解更多关于 Path的有选择的输出的细节,请参考:Traversal类。
| 注意 | |
下面的范例使用了一个已经废弃的遍历API。它与新的遍历查询API共享底层实现,所以它们的性能是一样的。比较起来它提供的功能非常有限。 | ||

4.5.2. 老的遍历查询 API
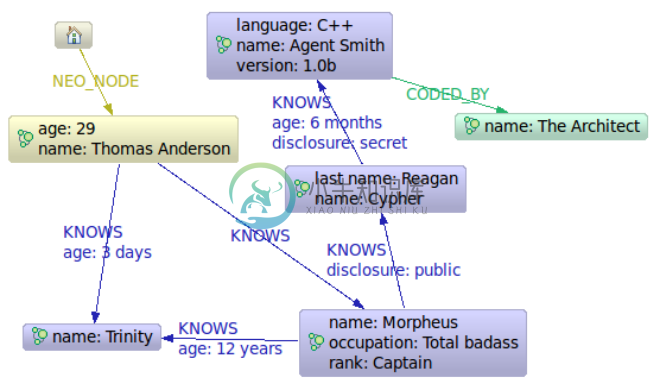
这是我们想遍历查询的第一个图数据库:
图 4.3. 黑客帝国节点空间预览
| 提示 |
范例源代码下载地址: Matrix.java |

朋友以及朋友的朋友.
1 2 3 4 5 6 7 | privatestaticTraverser getFriends( finalNode person ) { returnperson.traverse( Order.BREADTH_FIRST, StopEvaluator.END_OF_GRAPH, ReturnableEvaluator.ALL_BUT_START_NODE, RelTypes.KNOWS, Direction.OUTGOING ); } |
让我们执行一次真实的遍历查询并打印结果:
1 2 3 4 5 6 7 8 9 10 11 12 | intnumberOfFriends = 0; String output = neoNode.getProperty( "name") + "'s friends:\n"; Traverser friendsTraverser = getFriends( neoNode ); for( Node friendNode : friendsTraverser ) { output += "At depth "+ friendsTraverser.currentPosition().depth() + " => "+ friendNode.getProperty( "name") + "\n"; numberOfFriends++; } output += "Number of friends found: "+ numberOfFriends + "\n"; |
下面是输出结果:
1 2 3 4 5 6 | Thomas Anderson 的朋友们: At depth 1=> Trinity At depth 1=> Morpheus At depth 2=> Cypher At depth 3=> Agent Smith 一共找到朋友数量: 4 |
是谁编写了黑客帝国呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | privatestaticTraverser findHackers( finalNode startNode ) { returnstartNode.traverse( Order.BREADTH_FIRST, StopEvaluator.END_OF_GRAPH, newReturnableEvaluator() { @Override publicbooleanisReturnableNode( finalTraversalPosition currentPos ) { return!currentPos.isStartNode() && currentPos.lastRelationshipTraversed() .isType( RelTypes.CODED_BY ); } }, RelTypes.CODED_BY, Direction.OUTGOING, RelTypes.KNOWS, Direction.OUTGOING ); } |
输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 | String output = "Hackers:\n"; intnumberOfHackers = 0; Traverser traverser = findHackers( getNeoNode() ); for( Node hackerNode : traverser ) { output += "At depth "+ traverser.currentPosition().depth() + " => "+ hackerNode.getProperty( "name") + "\n"; numberOfHackers++; } output += "Number of hackers found: "+ numberOfHackers + "\n"; |
现在我们知道是谁编写了黑客帝国:
1 2 3 | Hackers: At depth 4=> The Architect 找到hackers的数量: 1 |
4.5.3. 在遍历查询中的唯一路径
这个范例演示了节点唯一性的使用。下面是一个想象的有多个负责人的领域图,这些负责人有它们增加的宠物,而这些宠物又生产了它的后代。
图 4.4. 后代范例图
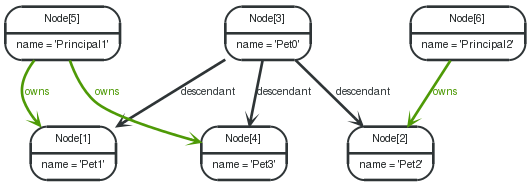
为了返回 Pet0的所有后代,要求与 Pet0必须有 owns和 Principal1关系(实际上只有 Pet1和 Pet3),遍历查询的 Uniqueness应该设置成 NODE_PATH来代替默认的 NODE_GLOBAL以至于节点可以被遍历不止一次,而且那些有不同节点但能有一些相同的路径(比如开始节点和结束节点)也能被返回。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | finalNode target = data.get().get( "Principal1"); TraversalDescription td = Traversal.description() .uniqueness( Uniqueness.NODE_PATH ) .evaluator( newEvaluator() { @Override publicEvaluation evaluate( Path path ) { if( path.endNode().equals( target ) ) { returnEvaluation.INCLUDE_AND_PRUNE; } returnEvaluation.EXCLUDE_AND_CONTINUE; } } ); Traverser results = td.traverse( start ); |
这将返回下面的路径:
1 2 | (3)--[descendant,0]-->(1)<--[owns,3]--(5) (3)--[descendant,2]-->(4)<--[owns,5]--(5) |
在 path.toString()的默认实现中,(1)--[knows,2]-->(4)表示一个ID=1的节点通过一个ID=2,关系类型为 knows的关系连接到了一个ID=4的节点上。
让我们从一个旧的中创建一个新的 TraversalDescription,并且设置uniqueness为 NODE_GLOBAL来查看它们之间的区别。
| 提示 | |
TraversalDescription对象是不变的,因此我们必须使用一个新的实例来返回新的uniqueness设置。 | ||
1 2 | TraversalDescription nodeGlobalTd = td.uniqueness( Uniqueness.NODE_GLOBAL ); results = nodeGlobalTd.traverse( start ); | |

现在只有一条路径返回:
1 | (3)--[descendant,0]-->(1)<--[owns,3]--(5) |
4.5.4. 社交网络
注意: 下面的范例使用了处于实验阶段的遍历查询API。
社交网络(在互联网上也被称为社交图)是天然的用图来表示的模型。下面的范例演示了一个非常简单的社交模型,它连接了朋友并关注了好友动态。
| 提示 |
范例源代码下载地址: socnet |

简单的社交模型
图 4.5. 社交网络数据模型
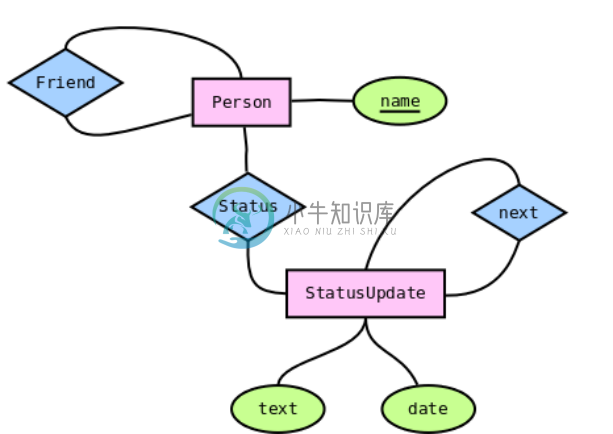
一个社交网络的数据模型是简漂亮的:有名称的 Persons和有时间戳文本的 StatusUpdates。这些实体然后通过特殊的关系连接在一起。
- Person
ofriend: 连接两个不同 Person实例的关系 (不能连接自己)
ostatus: 连接到最近的 StatusUpdate
- StatusUpdate
onext: 指向在主线上的下一个 StatusUpdate,是在当前这个状态更新之前发生的
状态图实例
一个 Person的 StatusUpdate列表 是一个链表。表头(最近动态)可以通过下一个 status找到。每一个随后的 StatusUpdate都通过关系 next相连。
这是一个 Andreas Kollegger 微博记录图早上走路上班的范例:
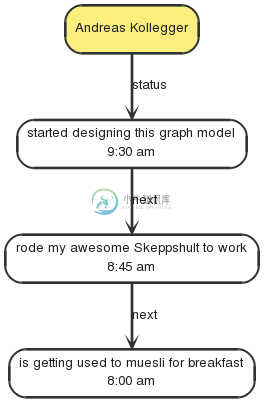
为了读取状态更新情况,我们可以创建一个遍历查询,比如:
1 2 3 | TraversalDescription traversal = Traversal.description(). depthFirst(). relationships( NEXT ); |
这给了我们一个遍历查询,它将从一个 StatusUpdate开始,并一直跟随状态的主线直到它们运行结束。遍历查询是懒加载模式所以当我们处理成千上万状态的时候性能一样很好 — 除非我们真实使用它们,否在它们不会被加载。
活动流
一旦我们有了朋友,而且它们有了状态消息,我们可能想读取我们的朋友的消息动态,按时间倒序排列 — 最新的动态在前面。为了实现这个,我们可以通过下面几个步骤:
1.抓取所有的好友动态放入一个列表 — 最新的排前面。
2.对列表进行排序。
3.返回列表中的第一个记录。
4.如果第一个迭代器为空,则把它从列表移除。否则,在这个迭代器中获取下一个记录。
5.跳转到步骤2直到在列表中没有任何记录。
这个队列看起来像这样。
代码实现像这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | PositionedIterator<StatusUpdate> first = statuses.get(0); StatusUpdate returnVal = first.current(); if( !first.hasNext() ) { statuses.remove( 0); } else { first.next(); sort(); } returnreturnVal; |
4.6. 领域实体
这个地方演示了当使用Neo4j时控制领域实体的一个方法。使用的原则是将实体封装到节点上(这个方法也可以用在关系上)。
| 提示 |
范例源代码下载地址: Person.java |
马上,保存节点并且让它在包里可以被访问:
1 2 3 4 5 6 7 8 9 10 11 | privatefinalNode underlyingNode; Person( Node personNode ) { this.underlyingNode = personNode; } protectedNode getUnderlyingNode() { returnunderlyingNode; } |
分配属性给节点:
1 2 3 4 | publicString getName() { return(String)underlyingNode.getProperty( NAME ); } |
确保重载这些方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | @Override publicinthashCode() { returnunderlyingNode.hashCode(); } @Override publicbooleanequals( Object o ) { returno instanceofPerson && underlyingNode.equals( ( (Person)o ).getUnderlyingNode() ); } @Override publicString toString() { return"Person["+ getName() + "]"; } | ||
4.7. 图算法范例
| 提示 |
范例源代码下载地址: PathFindingExamplesTest.java |

计算正连个节点之间的最短路径(最少数目的关系):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | Node startNode = graphDb.createNode(); Node middleNode1 = graphDb.createNode(); Node middleNode2 = graphDb.createNode(); Node middleNode3 = graphDb.createNode(); Node endNode = graphDb.createNode(); createRelationshipsBetween( startNode, middleNode1, endNode ); createRelationshipsBetween( startNode, middleNode2, middleNode3, endNode ); // Will find the shortest path between startNode and endNode via // "MY_TYPE" relationships (in OUTGOING direction), like f.ex: // // (startNode)-->(middleNode1)-->(endNode) // PathFinder<Path> finder = GraphAlgoFactory.shortestPath( Traversal.expanderForTypes( ExampleTypes.MY_TYPE, Direction.OUTGOING ), 15); Iterable<Path> paths = finder.findAllPaths( startNode, endNode ); |
使用 迪科斯彻(Dijkstra)算法解决有向图中任意两个顶点之间的最短路径问题。
1 2 3 4 5 6 7 | PathFinder<WeightedPath> finder = GraphAlgoFactory.dijkstra( Traversal.expanderForTypes( ExampleTypes.MY_TYPE, Direction.BOTH ), "cost"); WeightedPath path = finder.findSinglePath( nodeA, nodeB ); // Get the weight for the found path path.weight(); |
使用 A*算法是解决静态路网中求解最短路最有效的方法。
这儿是我们的范例图:
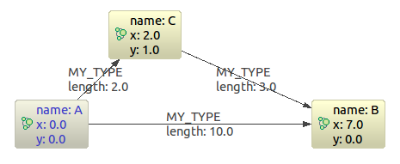
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | Node nodeA = createNode( "name", "A", "x", 0d, "y", 0d ); Node nodeB = createNode( "name", "B", "x", 7d, "y", 0d ); Node nodeC = createNode( "name", "C", "x", 2d, "y", 1d ); Relationship relAB = createRelationship( nodeA, nodeC, "length", 2d ); Relationship relBC = createRelationship( nodeC, nodeB, "length", 3d ); Relationship relAC = createRelationship( nodeA, nodeB, "length", 10d ); EstimateEvaluator<Double> estimateEvaluator = newEstimateEvaluator<Double>() { publicDouble getCost( finalNode node, finalNode goal ) { doubledx = (Double) node.getProperty( "x") - (Double) goal.getProperty( "x"); doubledy = (Double) node.getProperty( "y") - (Double) goal.getProperty( "y"); doubleresult = Math.sqrt( Math.pow( dx, 2) + Math.pow( dy, 2) ); returnresult; } }; PathFinder<WeightedPath> astar = GraphAlgoFactory.aStar( Traversal.expanderForAllTypes(), CommonEvaluators.doubleCostEvaluator( "length"), estimateEvaluator ); WeightedPath path = astar.findSinglePath( nodeA, nodeB ); |
4.8. 读取一个管理配置属性
EmbeddedGraphDatabase类包括了一个http://components.neo4j.org/neo4j/1.8/apidocs/org/neo4j/kernel/EmbeddedGraphDatabase.html#getManagementBean%28java.lang.Class%29[方便的方法]来获取Neo4j管理用的beans。
一般JMX服务也能使用,但比起你自己编码不如使用这概述的方法。
| 提示 |
范例源代码下载地址: JmxTest.java |
这个范例演示了如何得到一个图数据库的开始时间:
1 2 3 4 5 6 7 8 | privatestaticDate getStartTimeFromManagementBean( GraphDatabaseService graphDbService ) { GraphDatabaseAPI graphDb = (GraphDatabaseAPI) graphDbService; Kernel kernel = graphDb.getSingleManagementBean( Kernel.class); Date startTime = kernel.getKernelStartTime(); returnstartTime; } |
不同的Neo4j版本,你将使用不同的管理beans设置。
- 了解所有Neo4j版本的信息,请参考:org.neo4j.jmx。
- 了解Neo4j高级版和企业版的信息,请参考:org.neo4j.management。
4.9. OSGi配置
4.9.1. Simple OSGi Activator 脚本
在OSGi关联的上下文比如大量的应用服务器(e.g. Glassfish)和基于Eclipse的系统中,Neo4j能被明确地建立起来而不是通过Java服务加载机制来发现。
4.9.1. Simple OSGi Activator 脚本
如同在下面的范例中看到的一样,为了代替依赖Neo4j内核的类加载,Neo4j Bundle被作为库 bundles,而像 IndexProviders 和 CacheProviders 这样的服务被明确地实例化,配置和注册了秩序。只需要确保必要的jars,所以所有必须的类都被导出并且包括这Activator。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 4 | publicclassNeo4jActivator implementsBundleActivator { privatestaticGraphDatabaseService db; privateServiceRegistration serviceRegistration; privateServiceRegistration indexServiceRegistration; @Override publicvoidstart( BundleContext context ) throwsException { //the cache providers ArrayList<CacheProvider> cacheList = newArrayList<CacheProvider>(); cacheList.add( newSoftCacheProvider() ); //the index providers IndexProvider lucene = newLuceneIndexProvider(); ArrayList<IndexProvider> provs = newArrayList<IndexProvider>(); provs.add( lucene ); ListIndexIterable providers = newListIndexIterable(); providers.setIndexProviders( provs ); //the database setup GraphDatabaseFactory gdbf = newGraphDatabaseFactory(); gdbf.setIndexProviders( providers ); gdbf.setCacheProviders( cacheList ); db = gdbf.newEmbeddedDatabase( "target/db"); //the OSGi registration serviceRegistration = context.registerService( GraphDatabaseService.class.getName(), db, newHashtable<String,String>() ); System.out.println( "registered "+ serviceRegistration.getReference() ); indexServiceRegistration = context.registerService( Index.class.getName(), db.index().forNodes( "nodes"), newHashtable<String,String>() ); Transaction tx = db.beginTx(); try { Node firstNode = db.createNode(); Node secondNode = db.createNode(); Relationship relationship = firstNode.createRelationshipTo( secondNode, DynamicRelationshipType.withName( "KNOWS") ); firstNode.setProperty( "message", "Hello, "); secondNode.setProperty( "message", "world!"); relationship.setProperty( "message", "brave Neo4j "); db.index().forNodes( "nodes").add( firstNode, "message", "Hello"); tx.success(); } catch( Exception e ) { e.printStackTrace(); thrownewRuntimeException( e ); } finally { tx.finish(); } } @Override publicvoidstop( BundleContext context ) throwsException { serviceRegistration.unregister(); indexServiceRegistration.unregister(); db.shutdown(); } } |
4.10. 在Java中执行Cypher查询
| 提示 |
源代码下载地址: JavaQuery.java |
在Java中,你能使用cypher-query-lang,Cypher查询语言像下面这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | GraphDatabaseService db = newGraphDatabaseFactory().newEmbeddedDatabase( DB_PATH ); // add some data first Transaction tx = db.beginTx(); try { Node refNode = db.getReferenceNode(); refNode.setProperty( "name", "reference node"); tx.success(); } finally { tx.finish(); } // let's execute a query now ExecutionEngine engine = newExecutionEngine( db ); ExecutionResult result = engine.execute( "start n=node(0) return n, n.name"); System.out.println( result ); |
输出结果:
1 2 3 4 5 6 7 | +---------------------------------------------------+ | n | n.name | +---------------------------------------------------+ | Node[0]{name:"reference node"} | "reference node"| +---------------------------------------------------+ 1row 0ms |
注意:在这使用的类来自于 org.neo4j.cypher.javacompat包,而 不是+org.neo4j.cypher+,通过下面的链接查看Java API。
你可以在结果中获取列的一个列表:
1 2 | List<String> columns = result.columns(); System.out.println( columns ); |
输出结果:
1 | [n, n.name] |
在单列中获取结果数据集,像下面这样:
1 2 3 4 5 6 7 8 | Iterator<Node> n_column = result.columnAs( "n"); for( Node node : IteratorUtil.asIterable( n_column ) ) { // note: we're grabbing the name property from the node, // not from the n.name in this case. nodeResult = node + ": "+ node.getProperty( "name"); System.out.println( nodeResult ); } |
在这种情况下结果中只有一个几个记录:
1 | Node[0]: reference node |
要获取所有的列,用下面的代替:
1 2 3 4 5 6 7 8 9 | for( Map<String, Object> row : result ) { for( Entry<String, Object> column : row.entrySet() ) { rows += column.getKey() + ": "+ column.getValue() + "; "; } rows += "\n"; } System.out.println( rows ); |
输出结果:
1 | n.name: reference node; n: Node[0]; |
要获取Java接口中关于Cypher的更多信息,请参考:Java API。
要获取更多关于Cypher的范例的信息,请参考: cypher-query-lang 和 data-modeling-examples。