
第22章 后台作业
本文翻译自The Flask Mega-Tutorial Part XXII: Background Jobs
这是Flask Mega-Tutorial系列的第二十二部分,我将告诉你如何创建独立于Web服务器之外运行的后台作业。
本章致力于为应用程序中运行时间较长或复杂的异步任务进程进行优化。这些进程不能在请求的上下文中同步执行,因为这会在任务持续期间阻塞对客户端的响应。在第十章中,我将邮件的发送转移到后台线程中执行,以免阻塞响应。 虽然使用线程处理电子邮件是可以接受的,但当问题处理时间更长时,此解决方案就不足以支撑了。 公认的做法是将耗时长的任务移交到worker进程(或进程池)。
为了证明长时间运行任务存在的必要性,我将介绍Microblog的一个导出功能,用户通过它可以请求一个包含他们所有用户动态的数据文件。 当用户使用该选项时,应用程序将启动一个导出任务,该导出任务将生成包含所有用户动态的JSON文件,然后通过电子邮件发送给用户。 所有这些活动都将在worker进程中发生,并且在执行时,用户可以看到显示完成百分比的进度。
任务队列简介
任务队列为后台作业提供了一个便捷的解决方案。 Worker进程独立于应用程序运行,甚至可以位于不同的系统上。 应用程序和worker之间的通信是通过消息队列完成的。 应用程序提交作业,然后通过与队列交互来监视其进度。 下图展示了一个典型的实现:
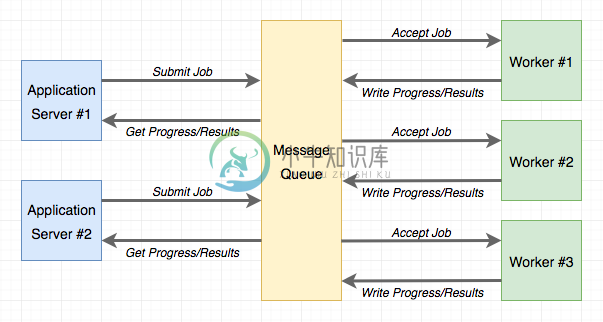
Python中最流行的任务队列是Celery。 这是一个相当复杂的软件包,它有很多选项并支持多个消息队列。 另一个流行的Python任务队列是Redis Queue(RQ),它牺牲了一些灵活性,比如只支持Redis消息队列,但作为交换,它的建立要比Celery简单得多。
Celery和RQ都非常适合在Flask应用程序中支持后台任务,所以我倾向于选择更简单的RQ。 不过,用Celery实现相同的功能其实也不难。 如果你对Celery更感兴趣,可以阅读我的博客中的Using Celery with Flask文章。
使用RQ
RQ是一个标准的Python三方软件包,用pip安装:
(venv) $ pip install rq(venv) $ pip freeze > requirements.txt
正如我前面提到的,应用和RQ worker之间的通信将在Redis消息队列中执行,因此你需要运行Redis服务器。 有许多途径来安装和运行Redis服务器,比如下载其源码并执行编译和安装。 如果你使用的是Windows,Microsoft在此处维护了Redis的安装程序。 在Linux上,你可以通过操作系统的软件包管理器安装Redis。 Mac OS X用户可以运行brew install redis,然后使用redis-server命令手动启动服务。
除了确保服务正在运行并可供RQ访问之外,你不需要与Redis进行其他交互。
创建任务
通过RQ执行一项简单的任务后,你就会很快熟悉它。 一个任务,不过是一个Python函数而已。 以下是一个示例任务,我将其放入一个新的app/tasks.py模块:
app/tasks.py:示例后台任务。
import timedef example(seconds):print('Starting task')for i in range(seconds):print(i)time.sleep(1)print('Task completed')
该任务将秒数作为参数,然后在该时间量内等待,并每秒打印一次计数器。
运行RQ Worker
任务准备就绪,可以通过rq worker来启动一个worker进程了:
(venv) $ rq worker microblog-tasks18:55:06 RQ worker 'rq:worker:miguelsmac.90369' started, version 0.9.118:55:06 Cleaning registries for queue: microblog-tasks18:55:0618:55:06 *** Listening on microblog-tasks...
Worker进程现在连接到了Redis,并在名为microblog-tasks的队列上查看可能分配给它的任何作业。 如果你想启动多个worker来扩展吞吐量,你只需要运行rq worker来生成更多连接到同一个队列的进程。 然后,当作业出现在队列中时,任何可用的worker进程都可以获取它。 在生产环境中,你可能希望至少运行可用CPU数量的worker。
执行任务
现在打开第二个终端窗口并激活虚拟环境。 我将使用shell会话来启动worker中的example()任务:
>>> from redis import Redis>>> import rq>>> queue = rq.Queue('microblog-tasks', connection=Redis.from_url('redis://'))>>> job = queue.enqueue('app.tasks.example', 23)>>> job.get_id()'c651de7f-21a8-4068-afd5-8b982a6f6d32'
来自RQ的Queue类表示从应用程序端看到的任务队列。 它采用的参数是队列名称和一个Redis连接对象,本处使用默认URL进行初始化。 如果你的Redis服务器运行在不同的主机或端口号上,则需要使用其他URL。
Queue的enqueue()方法用于将作业添加到队列中。 第一个参数是要执行的任务的名称,可直接传入函数对象或导入字符串。 我发现传入字符串更加方便,因为不需要在应用程序的一端导入函数。 对enqueue()传入的任何剩余参数将被传递给worker中运行的函数。
只要进行了enqueue()调用,运行着RQ worker的终端窗口上就会出现一些活动。 你会看到example()函数正在运行,并且每秒打印一次计数器。 同时,你的其他终端不会被阻塞,你可以继续在shell中执行表达式。在上面的例子中,我调用job.get_id()方法来获取分配给任务的唯一标识符。 你可以尝试使用另一个有趣表达式来检查worker上的函数是否已完成:
>>> job.is_finishedFalse
如果你像我在上面的例子中那样传递了23,那幺函数将运行约23秒。 在那之后,job.is_finished表达式将变为True。 就是这幺简单,炫酷否?
一旦函数完成,worker又回到等待作业的状态,所以如果你想进行更多的实验,你可以用不同的参数重复执行enqueue()调用。 队列中存储的有关任务的数据将保留一段时间(默认为500秒),但最终会被删除。 这很重要,任务队列不保留已执行作业的历史记录。
报告任务进度
上面使用的示例任务简单得不现实。 通常,对于长时间运行的任务,你需要将一些进度信息提供给应用程序,从而可以将其显示给用户。 RQ通过使用作业对象的meta属性来支持这一点。 让我重写example()任务来编写进度报告:
app/tasks.py::带进度的示例后台任务。
import timefrom rq import get_current_jobdef example(seconds):job = get_current_job()print('Starting task')for i in range(seconds):job.meta['progress'] = 100.0 * i / secondsjob.save_meta()print(i)time.sleep(1)job.meta['progress'] = 100job.save_meta()print('Task completed')
这个新版本的example()使用RQ的get_current_job()函数来获取一个作业实例,该实例与提交任务时返回给应用程序的实例类似。 作业对象的meta属性是一个字典,任务可以编写任何想要与应用程序通信的自定义数据。 在这个例子中,我写入了progress,表示完成任务的百分比。 每次进程更新时,我都调用job.save_meta()指示RQ将数据写入Redis,应用程序可以在其中找到它。
在应用程序方面(目前只是一个Python shell),我可以运行此任务,然后监视进度,如下所示:
>>> job = queue.enqueue('app.tasks.example', 23)>>> job.meta{}>>> job.refresh()>>> job.meta{'progress': 13.043478260869565}>>> job.refresh()>>> job.meta{'progress': 69.56521739130434}>>> job.refresh()>>> job.meta{'progress': 100}>>> job.is_finishedTrue
如你所见,在另一侧,meta属性可以被读取。 需要调用refresh()方法来从Redis更新内容。
任务的数据库表示
对于上面的例子来说,启动一个任务并观察它运行就足够了。 对于Web应用程序,情况会变得更复杂一些,因为一旦任务随着请求的处理而启动,该请求随即结束,而该任务的所有上下文都将丢失。 因为我希望应用程序跟踪每个用户正在运行的任务,所以我需要使用数据库表来维护状态。 你可以在下面看到新的Task模型实现:
app/models.py:Task模型。
# ...import redisimport rqclass User(UserMixin, db.Model):# ...tasks = db.relationship('Task', backref='user', lazy='dynamic')# ...class Task(db.Model):id = db.Column(db.String(36), primary_key=True)name = db.Column(db.String(128), index=True)description = db.Column(db.String(128))user_id = db.Column(db.Integer, db.ForeignKey('user.id'))complete = db.Column(db.Boolean, default=False)def get_rq_job(self):try:rq_job = rq.job.Job.fetch(self.id, connection=current_app.redis)except (redis.exceptions.RedisError, rq.exceptions.NoSuchJobError):return Nonereturn rq_jobdef get_progress(self):job = self.get_rq_job()return job.meta.get('progress', 0) if job is not None else 100
这个模型和以前的模型有一个有趣的区别是id主键字段是字符串类型,而不是整数类型。 这是因为对于这个模型,我不会依赖数据库自己的主键生成,而是使用由RQ生成的作业标识符。
该模型将存储符合任务命名规范的名称(会传递给RQ),适用于向用户显示的任务描述,该任务的所属用户的关系以及任务是否已完成的布尔值。complete字段的目的是将正在运行的任务与已完成的任务分开,因为运行中的任务需要特殊处理才能显示最新进度。
get_rq_job()辅助方法可以用给定的任务ID加载RQJob实例。 这是通过Job.fetch()完成的,它会从Redis中存在的数据中加载Job实例。 get_progress()方法建立在get_rq_job()的基础之上,并返回任务的进度百分比。 该方法做一些有趣的假设,如果模型中的作业ID不存在于RQ队列中,则表示作业已完成并且数据已过期并已从队列中删除,因此在这种情况下返回的百分比为100。 另一方面,如果job存在,但’meta’属性中找不到进度相关的信息,那幺可以安全地假定该job计划运行,但还没有启动,所以在这种情况下进度是0。
要将更改应用于数据库,需要生成新的迁移,然后升级数据库:
(venv) $ flask db migrate -m "tasks"(venv) $ flask db upgrade
新模型也可以添加到shell上下文中,以便在shell会话中访问它时无需导入:
microblog.py:添加Task模型到shell上下文中。
from app import create_app, db, clifrom app.models import User, Post, Message, Notification, Taskapp = create_app()cli.register(app)@app.shell_context_processordef make_shell_context():return {'db': db, 'User': User, 'Post': Post, 'Message': Message,'Notification': Notification, 'Task': Task}
将RQ与Flask应用集成
Redis服务的连接URL需要添加到配置中:
class Config(object):# ...REDIS_URL = os.environ.get('REDIS_URL') or 'redis://'
与往常一样,Redis连接URL将来自环境变量,如果该变量未定义,则会假定该服务在当前主机的默认端口上运行并使用默认URL。
应用工厂函数将负责初始化Redis和RQ:
app/init.py:整合RQ。
# ...from redis import Redisimport rq# ...def create_app(config_class=Config):# ...app.redis = Redis.from_url(app.config['REDIS_URL'])app.task_queue = rq.Queue('microblog-tasks', connection=app.redis)# ...
app.task_queue将成为提交任务的队列。 将队列附加到应用上会提供很大的便利,因为我可以在应用的任何地方使用current_app.task_queue来访问它。 为了方便应用的任何部分提交或检查任务,我可以在User模型中创建一些辅助方法:
app/models.py:用户模型中的任务辅助方法。
# ...class User(UserMixin, db.Model):# ...def launch_task(self, name, description, *args, **kwargs):rq_job = current_app.task_queue.enqueue('app.tasks.' + name, self.id,*args, **kwargs)task = Task(id=rq_job.get_id(), name=name, description=description,user=self)db.session.add(task)return taskdef get_tasks_in_progress(self):return Task.query.filter_by(user=self, complete=False).all()def get_task_in_progress(self, name):return Task.query.filter_by(name=name, user=self,complete=False).first()
launch_task()方法负责将任务提交到RQ队列,并将其添加到数据库中。 name参数是函数名称,如app/tasks.py中所定义的那样。 提交给RQ时,该函数会将app.tasks.预先添加到该名称中以构建符合规范的函数名称。description参数是对呈现给用户的任务的友好描述。 对于导出用户动态的函数,我将名称设置为export_posts,将描述设置为Exporting posts...。 其余参数将传递给任务函数。 launch_task()函数首先调用队列的enqueue()方法来提交作业。 返回的作业对象包含由RQ分配的任务ID,因此我可以使用它在我的数据库中创建相应的Task对象。
请注意,launch_task()将新的任务对象添加到会话中,但不会发出提交。 一般来说,最好在更高层次函数中的数据库会话上进行操作,因为它允许你在单个事务中组合由较低级别函数所做的多个更新。 这不是一个严格的规则,并且,在本章后面的子函数中也会存在一个例外的提交。
get_tasks_in_progress()方法返回该用户未完成任务的列表。 稍后你会看到,我使用此方法在将有关正在运行的任务的信息渲染到用户的页面中。
最后,get_task_in_progress()是上一个方法的简化版本并返回指定的任务。 我阻止用户同时启动两个或多个相同类型的任务,因此在启动任务之前,可以使用此方法来确定前一个任务是否还在运行。
利用RQ任务发送电子邮件
不要认为本节偏离主题,我在上面说过,当后台导出任务完成时,将使用包含所有用户动态的JSON文件向用户发送电子邮件。 我在第十章中构建的电子邮件功能需要通过两种方式进行扩展。 首先,我需要添加对文件附件的支持,以便我可以附加JSON文件。 其次,send_email()函数总是使用后台线程异步发送电子邮件。 当我要从后台任务发送一封电子邮件时(已经是异步的了),基于线程的二级后台任务没有什幺意义,所以我需要同时支持同步和异步电子邮件的发送。
幸运的是,Flask-Mail支持附件,所以我需要做的就是扩展send_email()函数的默认关键字参数,然后在Message对象中配置它们。 选择在前台发送电子邮件时,我只需要添加一个sync=True的关键字参数即可:
app/email.py:发送带附件的邮件。
# ...def send_email(subject, sender, recipients, text_body, html_body,attachments=None, sync=False):msg = Message(subject, sender=sender, recipients=recipients)msg.body = text_bodymsg.html = html_bodyif attachments:for attachment in attachments:msg.attach(*attachment)if sync:mail.send(msg)else:Thread(target=send_async_email,args=(current_app._get_current_object(), msg)).start()
Message类的attach()方法接受三个定义附件的参数:文件名,媒体类型和实际文件数据。 文件名就是收件人看到的与附件关联的名称。 媒体类型定义了这种附件的类型,这有助于电子邮件读者适当地渲染它。 例如,如果你发送image/png作为媒体类型,则电子邮件阅读器会知道该附件是一个图像,在这种情况下,它可以显示它。 对于用户动态数据文件,我将使用JSON格式,该格式使用application/json媒体类型。 最后一个参数包含附件内容的字符串或字节序列。
简单来说,send_email()的attachments参数将成为一个元组列表,每个元组将有三个元素对应于attach()的三个参数。 因此,我需要将此列表中的每个元素作为参数发送给attach()。 在Python中,如果你想将列表或元组中的每个元素作为参数传递给函数,你可以使用func(*args)将这个列表或元祖解包成函数中的多个参数,而不必枯燥地一个个地传递,如func(args[0], args[1], args[2])。 例如,如果你有一个列表args = [1, 'foo'],func(*args)将会传递两个参数,就和你调用func(1, 'foo')一样。 如果没有*,调用将会传入一个参数,即args列表。
至于电子邮件的同步发送,我需要做的就是,当sync是True的时候恢复成调用mail.send(msg)。
任务助手
尽管我上面使用的example()任务是一个简单的独立函数,但导出用户动态的函数却需要应用中具有的一些功能,例如访问数据库和发送电子邮件。 因为这将在单独的进程中运行,所以我需要初始化Flask-SQLAlchemy和Flask-Mail,而Flask-Mail又需要Flask应用实例以从中获取它们的配置。 因此,我将在app/tasks.py模块的顶部添加Flask应用实例和应用上下文:
app/tasks.py:创建应用及其上下文。
from app import create_appapp = create_app()app.app_context().push()
应用在此模块中创建,因为这是RQ worker要导入的唯一模块。 当使用flask命令时,根目录中的microblog.py模块创建应用实例,但RQ worker对此却一无所知,所以当任务函数需要它时,它需要创建自己的应用实例。 你已经在好几个地方看到了app.app_context()方法,推送一个上下文使应用成为“当前”的应用实例,这样一来Flask-SQLAlchemy等插件才可以使用current_app.config 获取它们的配置。 没有上下文,current_app表达式会返回一个错误。
然后我开始考虑如何在这个函数运行时报告进度。除了通过job.meta字典传递进度信息之外,我还想将通知推送给客户端,以便自动动态更新完成百分比。为此,我将使用我在第二十一章中构建的通知机制。更新将以与未读消息徽章非常类似的方式工作。当服务器渲染模板时,它将包含从job.meta获得的“静态”进度信息,但是一旦页面位于客户端的浏览器中,通知将使用通知来动态更新百分比。由于通知的原因,更新正在运行的任务的进度将比上一个示例中的操作稍微多一些,所以我将创建一个专用于更新进度的包装函数:
app/tasks.py:设置任务进度。
from rq import get_current_jobfrom app import dbfrom app.models import Task# ...def _set_task_progress(progress):job = get_current_job()if job:job.meta['progress'] = progressjob.save_meta()task = Task.query.get(job.get_id())task.user.add_notification('task_progress', {'task_id': job.get_id(),'progress': progress})if progress >= 100:task.complete = Truedb.session.commit()
导出任务可以调用_set_task_progress()来记录进度百分比。 该函数首先将百分比写入job.meta字典并将其保存到Redis,然后从数据库加载相应的任务对象,并使用task.user已有的add_notification()方法将通知推送给请求该任务的用户。 通知将被命名为task_progress,并且与其关联的数据将成为具有两个条目的字典:任务标识符和进度数值。 稍后我将添加JavaScript代码来处理这种新的通知类型。
该函数查看进度来确认任务函数是否已完成,并在这种情况下更新数据库中任务对象的complete属性。 数据库提交调用确保通过add_notification()添加的任务和通知对象都立即保存到数据库。 我需要非常精确地设计父任务,确保不执行任何数据库更改,因为执行本调用会将父任务的更改也写入数据库。
实现导出任务
现在所有的准备工作已经完成,可以开始编写导出函数了。 这个函数的高层结构如下:
app/tasks.py:导出用户动态通用结构。
def export_posts(user_id):try:# read user posts from database# send email with data to userexcept:# handle unexpected errors
为什幺将整个任务包装在try/except块中呢? 请求处理器中的应用代码可以防止意外错误,因为Flask本身捕获异常,然后将它们以我设置的日志配置的方式来进行处理。 然而,这个函数将运行在由RQ控制的单独进程中,而非Flask,因此如果发生任何意外错误,任务将中止,RQ将向控制台显示错误,然后返回等待新的job。 所以基本上,除非你正在观看RQ worker的输出或将其记录到文件中,否则将永远不会发现有错误。
让我们从上面带有注释的三部分中最简单的错误处理部分开始梳理:
app/tasks.py:导出用户动态错误处理。
import sys# ...def export_posts(user_id):try:# ...except:_set_task_progress(100)app.logger.error('Unhandled exception', exc_info=sys.exc_info())
每当发生意外错误时,我将通过将进度设置为100%来将任务标记为完成,然后使用Flask应用程序中的日志记录器对象记录错误以及堆栈跟踪信息(调用sys.exc_info()来获得)。 使用Flask应用日志记录器来记录错误的好处在于,你可以观察到你为Flask应用实现的任何日志记录机制。 例如,在第七章中,我配置了要发送到管理员电子邮件地址的错误。 只要使用app.logger,我也可以得到这些错误信息。
接下来,我将编写实际的导出代码,它只需发出一个数据库查询并在循环中遍历结果,并将它们累积在字典中:
app/tasks.py:从数据库读取用户动态。
import timefrom app.models import User, Post# ...def export_posts(user_id):try:user = User.query.get(user_id)_set_task_progress(0)data = []i = 0total_posts = user.posts.count()for post in user.posts.order_by(Post.timestamp.asc()):data.append({'body': post.body,'timestamp': post.timestamp.isoformat() + 'Z'})time.sleep(5)i += 1_set_task_progress(100 * i // total_posts)# send email with data to userexcept:# ...
每条动态都是一个包含两个条目的字典,即动态正文和动态发表的时间。 时间格式将采用ISO 8601标准。 我使用的Python的datetime对象不存储时区,因此在以ISO格式导出时间后,我添加了’Z’,它表示UTC。
由于需要跟踪进度,代码变得稍微复杂了些。 我维护了一个计数器i,并且在进入循环之前还需要发出一个额外的数据库查询,查询total_posts以获得用户动态的总数。 使用了i和total_posts,在每个循环迭代我都可以使用从0到100的数字来更新任务进度。
你可能会好奇我为什幺会在每个循环迭代中加入time.sleep(5)调用。主要原因是我想要延长导出所需的时间,以便在用户动态不多的情况下也可以方便地查看到导出进度的增长。
下面是函数的最后部分,将会带上data附件发送邮件给用户:
app/tasks.py:发送带用户动态的邮件给用户。
import jsonfrom flask import render_templatefrom app.email import send_email# ...def export_posts(user_id):try:# ...send_email('[Microblog] Your blog posts',sender=app.config['ADMINS'][0], recipients=[user.email],text_body=render_template('email/export_posts.txt', user=user),html_body=render_template('email/export_posts.html', user=user),attachments=[('posts.json', 'application/json',json.dumps({'posts': data}, indent=4))],sync=True)except:# ...
其实只是对send_email()函数的调用。 附件被定义为一个元组,其中有三个元素被传递给Flask-Mail的Message对象的attach()方法。 元组中的第三个元素是附件内容,它是用Python的json.dumps()函数生成的。
这里引用了一对新模板,它们以纯文本和HTML格式提供电子邮件正文的内容。 这是文本模板的内容:
app/templates/email/export_posts.txt:导出用户动态文本邮件模板。
Dear {{ user.username }},Please find attached the archive of your posts that you requested.Sincerely,The Microblog Team
这是HTML版本的邮件模板:
app/templates/email/export_posts.html:导出用户动态HTML邮件模板。
<p>Dear {{ user.username }},</p><p>Please find attached the archive of your posts that you requested.</p><p>Sincerely,</p><p>The Microblog Team</p>
应用中的导出功能
所有支持后台导出任务的核心组件现已到位。 剩下的就是将这个功能连接到应用,以便用户发起请求并通过电子邮件发送用户动态给他们。
下面是新的export_posts视图函数:
app/main/routes.py:导出用户动态路由和视图函数。
@bp.route('/export_posts')@login_requireddef export_posts():if current_user.get_task_in_progress('export_posts'):flash(_('An export task is currently in progress'))else:current_user.launch_task('export_posts', _('Exporting posts...'))db.session.commit()return redirect(url_for('main.user', username=current_user.username))
该函数首先检查用户是否有未完成的导出任务,并在这种情况下只是闪现消息。 对同一用户同时执行两个导出任务是没有意义的,可以避免。 我可以使用前面实现的get_task_in_progress()方法来检查这种情况。
如果用户没有正在运行的导出任务,则调用launch_task()来启动它。 第一个参数是将传递给RQ worker的函数的名称,前缀为app.tasks.。 第二个参数只是一个友好的文本描述,将会显示给用户。 这两个值都会被写入数据库中的Task对象。 该函数以重定向到用户个人主页结束。
现在我需要暴露该路由的链接,以便用户可以请求导出。 我认为最合适的地方是在用户个人主页,只有在用户查看他们自己的主页时,链接在“编辑个人资料”链接下面显示:
app/templates/user.html:用户个人主页的导出链接。
...<p><a href="{{ url_for('main.edit_profile') }}">{{ _('Edit your profile') }}</a></p>{% if not current_user.get_task_in_progress('export_posts') %}<p><a href="{{ url_for('main.export_posts') }}">{{ _('Export your posts') }}</a></p>...{% endif %}
此链接的渲染是有条件的,因为我不希望它在用户已经有导出任务执行时出现。
此时的后台作业是可以运作的,但是不会向用户提供任何反馈。 如果你想尝试一下,你可以按如下方式启动应用和RQ worker:
- 确保Redis正在运行
- 打开一个终端窗口,启动至少一个RQ worker实例。本处你可以运行命令
rq worker microblog-tasks - 再打开另一个终端窗口,使用
flask run(记得先设置FLASK_APP变量)命令启动Flask应用
进度通知
为了完善这个功能,我想在后台任务运行时提醒用户任务完成的百分比进度。 在浏览Bootstrap组件选项时,我决定在导航栏的下方使用一个Alert组件。 Alert组件是向用户显示信息的带颜色的横条。 我用蓝色的Alert框来渲染闪现的消息。 现在我要添加一个绿色的Alert框来显示任务进度。 样式如下: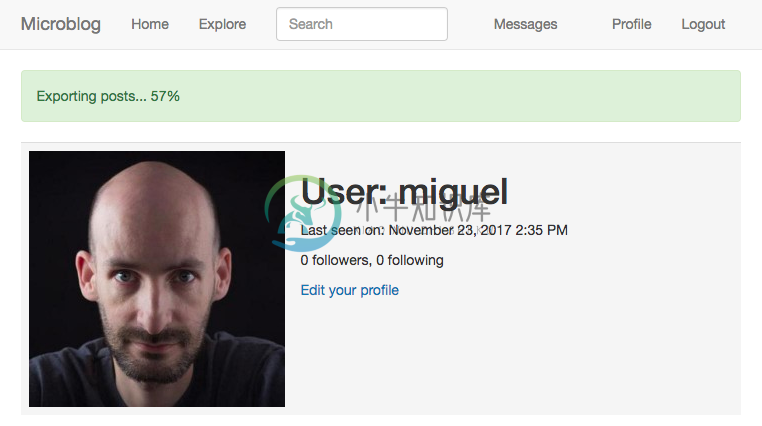
app/templates/base.html:基础模板中的导出进度Alert组件。
...{% block content %}<div class="container">{% if current_user.is_authenticated %}{% with tasks = current_user.get_tasks_in_progress() %}{% if tasks %}{% for task in tasks %}<div class="alert alert-success" role="alert">{{ task.description }}<span id="{{ task.id }}-progress">{{ task.get_progress() }}</span>%</div>{% endfor %}{% endif %}{% endwith %}{% endif %}...{% endblock %}...
渲染任务Alert组件的方法几乎与闪现消息相同。 外部条件在用户未登录时跳过所有与Alert相关的标记。而对于已登录用户,我通过调用前面创建的get_tasks_in_progress()方法来获取当前正在进行的任务列表。 在当前版本的应用中,我最多只能得到一个结果,因为我不允许多个导出任务同时执行,但将来我可能要支持可以共存的其他类型的任务,所以以通用的方式渲染Alert可以节省我以后的时间。
对于每项任务,我都会在页面上渲染一个Alert元素。 Alert的颜色由第二个CSS样式控制,本处是alert-success,而在闪现消息是alert-info。 Bootstrap文档包含有关Alert的HTML结构的详细信息。 Alert文本包括存储在Task模型中的description字段,后面跟着完成百分比。
百分比被封装在具有id属性的<span>元素中。 原因是我要在收到通知时用JavaScript刷新百分比。 我给任务ID末尾附加-progress来构造id属性。 当有通知到达时,通过其中的任务ID,我可以很容易地使用#<task.id>-progress选择器找到正确的<span>元素来更新。
如果你此时进行尝试,则每次导航到新页面时都会看到“静态”的进度更新。 你可以注意到,在启动导出任务后,你可以自由导航到应用程序的不同页面,正在运行的任务的状态始终都会展示出来。
为了对span>元素的百分比的动态更新做准备,我将在JavaScript端编写一个辅助函数:
app/templates/base.html:动态更新任务进度的辅助函数。
...{% block scripts %}...<script>...function set_task_progress(task_id, progress) {$('#' + task_id + '-progress').text(progress);}</script>...{% endblock %}
这个函数接受一个任务id和一个进度值,并使用jQuery为这个任务定位<span>元素,并将新进度作为其内容写入。 实际上不需要验证页面上是否存在该元素,因为如果没有找到该元素,jQuery将不会执行任何操作。
app/tasks.py中的_set_task_progress()函数每次更新进度时调用add_notification(),就会产生新的通知。 而我在第二十一章明智地以完全通用的方式实现了通知功能。 所以当浏览器定期向服务器发送通知更新请求时,浏览器会获得通过add_notification()方法添加的任何通知。
但是,这些JavaScript代码只能识别具有unread_message_count名称的那些通知,并忽略其余部分。 我现在需要做的是扩展该函数,通过调用我上面定义的set_task_progress()函数来处理task_progress通知。 以下是处理通知更新版本JavaScript代码:
app/templates/base.html:通知处理器。
for (var i = 0; i < notifications.length; i++) {switch (notifications[i].name) {case 'unread_message_count':set_message_count(notifications[i].data);break;case 'task_progress':set_task_progress(notifications[i].data.task_id,notifications[i].data.progress);break;}since = notifications[i].timestamp;}
现在我需要处理两个不同的通知,我决定用一个switch语句替换检查unread_message_count通知名称的if语句,该语句包含我现在需要支持的每个通知。 如果你对“C”系列语言不熟悉,就可能从未见过switch语句,它提供了一种方便的语法,可以替代一长串的if/elseif语句。这是一个很棒的特性,因为当我需要支持更多通知时,只需简单地添加case块即可。
回顾一下,RQ任务附加到task_progress通知的数据是一个包含两个元素task_id和progress的字典,这两个元素是我用来调用set_task_progress()的两个参数。
如果你现在运行该应用,则绿色Alert框中的进度指示器将每10秒刷新一次(因为刷新通知的时间间隔是10秒)。
由于本章介绍了新的可翻译字符串,因此需要更新翻译文件。 如果你要维护非英语语言文件,则需要使用Flask-Babel刷新翻译文件,然后添加新的翻译:
(venv) $ flask translate update
如果你使用的是西班牙语翻译,那幺我已经为你完成了翻译工作,因此可以从下载包中提取app/translations/es/LC_MESSAGES/messages.po文件,并将其添加到你的项目中。
翻译文件到位后,还要编译翻译文件:
(venv) $ flask translate compile
部署注意事项
为了完成本章,我还要讨论应用程序部署的变化。 为了支持后台任务,我在部署栈中增加了两个新组件,一个Redis服务器和一/多个RQ worker。 很明显,它们需要包含在部署策略中,因此我将简要介绍前几章中不同部署方式的一些调整。
部署到Linux服务器
如果你正在Linux服务器上运行应用,则添加Redis十分简单。 对于Ubuntu Linux,你可以运行sudo apt-get install redis-server来安装Redis服务器。
要运行RQ worker进程,可以按照第十七章中“设置Gunicorn和Supervisor”一节那样创建第二个Supervisor配置,在其中运行的命令改成rq worker microblog-tasks。 如果你想要运行多个worker(假设是生产环境),则可以使用Supervisor的numprocs指令来指示要同时运行多少个实例。
部署到Heroku
要在Heroku上部署应用,你需要将Redis服务添加到你的帐户。 这与我添加Postgres数据库的过程类似。 Redis也有一个免费档次,可以使用以下命令添加:
$ heroku addons:create heroku-redis:hobby-dev
新的redis服务的访问URL将作为REDIS_URL变量添加到你的Heroku环境中,这正是应用所需的。
Heroku的免费方案允许同时启动一个web进程和一个worker进程,因此你可以在免费的情况下启动一个rq worker进程。 为此,你将需要在procfile的一个单独的行中声明worker:
web: flask db upgrade; flask translate compile; gunicorn microblog:appworker: rq worker microblog-tasks
将这些变更重新部署之后,可以使用以下命令启动worker:
$ heroku ps:scale worker=1
部署到Docker
如果你将应用程序部署到Docker容器,那幺首先需要创建一个Redis容器。 为此,你可以使用Docker镜像仓库中的其中一个官方Redis镜像:
$ docker run --name redis -d -p 6379:6379 redis:3-alpine
当运行你的应用时,你需要以类似于MySQL容器的链接方式,链接redis容器并设置REDIS_URL环境变量。 下面是一个完整的命令来启动应用,包含了一个redis链接:
$ docker run --name microblog -d -p 8000:5000 --rm -e SECRET_KEY=my-secret-key \-e MAIL_SERVER=smtp.googlemail.com -e MAIL_PORT=587 -e MAIL_USE_TLS=true \-e MAIL_USERNAME=<your-gmail-username> -e MAIL_PASSWORD=<your-gmail-password> \--link mysql:dbserver --link redis:redis-server \-e DATABASE_URL=mysql+pymysql://microblog:<database-password>@dbserver/microblog \-e REDIS_URL=redis://redis-server:6379/0 \microblog:latest
最后,你需要为RQ worker运行一/多个容器。 由于worker与主应用具有相同的代码,因此可以使用与应用相同的容器镜像,并覆盖启动命令,以便启动worker而不是Web应用。 以下是启动worker的docker run命令:
$ docker run --name rq-worker -d --rm -e SECRET_KEY=my-secret-key \-e MAIL_SERVER=smtp.googlemail.com -e MAIL_PORT=587 -e MAIL_USE_TLS=true \-e MAIL_USERNAME=<your-gmail-username> -e MAIL_PASSWORD=<your-gmail-password> \--link mysql:dbserver --link redis:redis-server \-e DATABASE_URL=mysql+pymysql://microblog:<database-password>@dbserver/microblog \-e REDIS_URL=redis://redis-server:6379/0 \--entrypoint venv/bin/rq \microblog:latest worker -u redis://redis-server:6379/0 microblog-tasks
覆盖Docker镜像的默认启动命令有点棘手,因为命令需要分两部分给出。 --entrypoint参数只取得可执行文件的名称,但是参数(如果有的话)需要在镜像和标签之后,也就是在命令行的结尾处给出。 请注意rq命令需要使用venv/bin/rq,以便在没有手动激活虚拟环境的情况下,也能识别虚拟环境并正常工作。