
MMdnn 是微软开源的一套帮助用户在不同深度学习框架之间进行互操作的工具,包括模型转换和可视化。目前支持在 Caffe、Keras、MXNet、Tensorflow、CNTK、PyTorch 和 CoreML 等框架之间进行模型转换。
MMdnn 是一个用于转换、可视化和诊断深度神经网络模型的综合跨框架解决方案。MMdnn 中的「MM」代表模型管理,「dnn」是「deep neural network」深度神经网络的缩写。
MMdnn 可将一个框架训练的 DNN 模型转换到成其他框架可用的模型。主要特性如下:
模型文件转换器,转换 DNN 模型使其适合不同框架;
模型代码块生成器,为框架生成适合的训练或推断代码块;
模型可视化,可视化框架的 DNN 网络架构和参数;
模型兼容性测试(正在进行)。
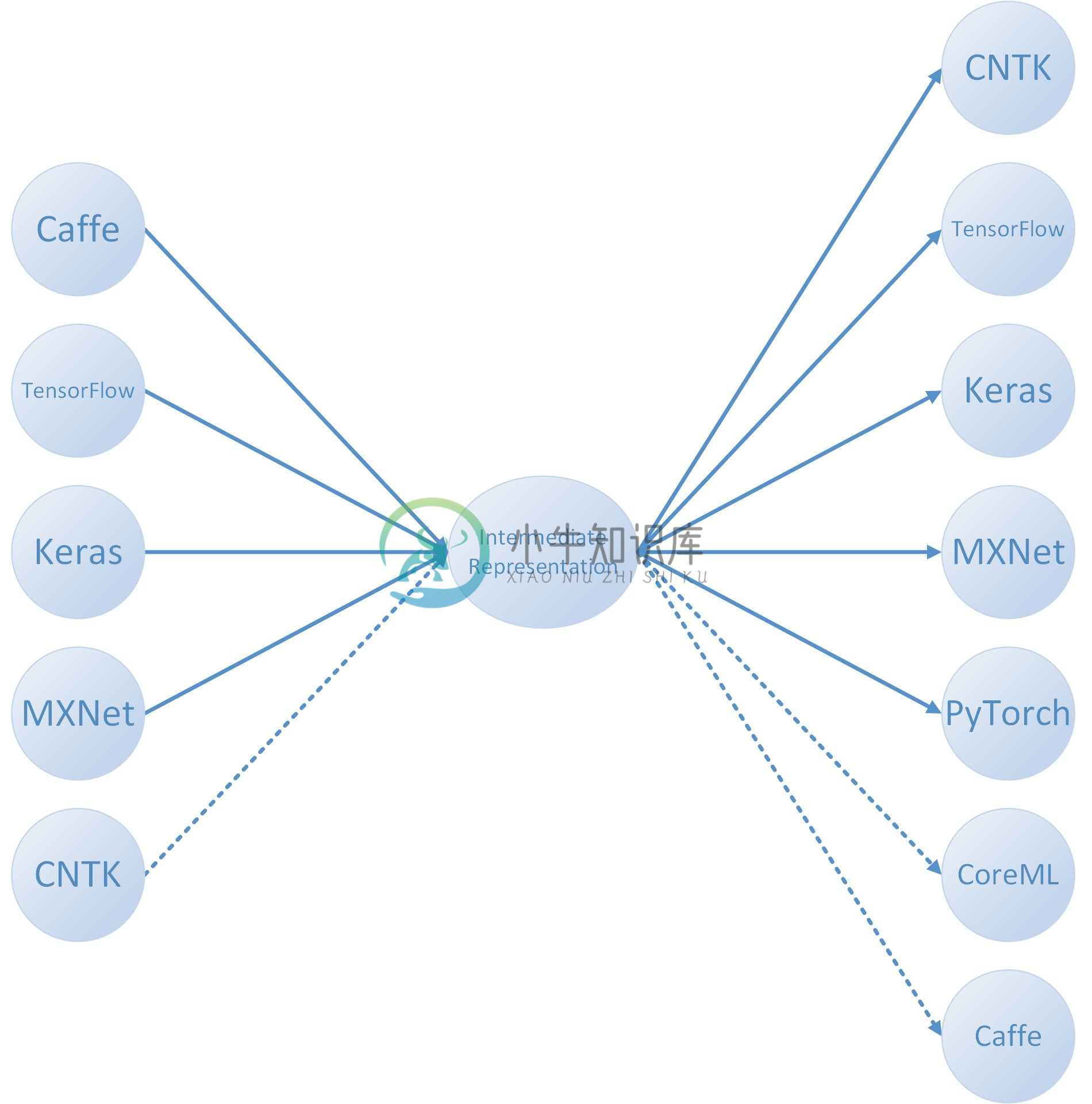
-
Caffe转mxnet模型——mmdnn中提到了使用mmdnn对模型进行转换,当时对转换的命令不是很清楚,最近重新查了一些,整理下mmdnn的转换命令。 一步转换 mmdnn的一步转换命令是mmconvert,源于mmdnn/conversion/_script/convert.py,其参数为: 命令 含义 -sf 输入模型类型 -in 输入模型网络(如果网络文件独立) -iw 输入权重文
-
一、mxnet转tensorflow模型 1.下载mmdnn源码或pip安装,切换到mmdnn主目录下;安装时需要安装numpy+mkl的最新版本,准备好 mxnet模型的 .json文件和.params文件。 2.运行命令行: python -m mmdnn.conversion._script.convertToIR -f mxnet -n model-symbol.json -w model
-
参考 https://github.com/Microsoft/MMdnn/blob/master/mmdnn/conversion/tensorflow/README.md#how-to-prepare-your-model-and-conversion-parameters 查看可用模型: How to prepare your model and conversion parameters
-
mmdnn是微软出的工具,能够在各种深度学习模型之间转换训练好的模型 安装:pip install mmdnn 举例:将tensorflow模型转换为caffe模型,需要安装好tensorflow和pycaffe, 之后运行命令:mmconvert -sf tensorflow -in model.ckpt-0.meta -iw model.ckpt-0 --dstNode coord_ou
-
深度学习有很多不同的框架,各有优点。一方面促进了就业,另外一方面也对程序员提出了更高要求,很多时候不得不在各种框架中穿梭转换…… 可是咱不是天才啊,怎么办?有天才们的杰作。比如这个MMdnn在Caffe,Keras,MXNet,Tensorflow,CNTK,PyTorch Onnx和CoreML之间转换模型。 # 稳定版本 sudo pip install mmdnn # 最新版本 p
-
https://github.com/Microsoft/MMdnn 刚开始在ubuntu18.04中使用的时候发现那些命令都不能使用,在windows下倒是好的。 后来发现是因为ubuntu18.04中默认使用的python2,而mmdnn需要使用的是python3 http://www.cnblogs.com/jasonlixuetao/p/9729753.html 修改默认使用的python
-
mmdnn模型转换到caffe,卷积层convolution_param中添加engine: CAFFE 在mmdnn->conversion->caffe的caffe——emitter.py 中修改 def emit_Conv(self,IR_node) 修改self.add_body(),在ntop=1后面添加 engine=1
-
LeNet 5 LeNet-5是第一个成功的卷积神经网络,共有7层,不包含输入,每层都包含可训练参数(连接权重)。 AlexNet tf AlexNet可以认为是增强版的LeNet5,共8层,其中前5层convolutional,后面3层是full-connected。 GooLeNet (Inception v2) GoogLeNet用了很多相同的层,共22层,并将全连接层变为稀疏链接层。 In
-
代码见nn_overfit.py 优化 Regularization 在前面实现的RELU连接的两层神经网络中,加Regularization进行约束,采用加l2 norm的方法,进行负反馈: 代码实现上,只需要对tf_sgd_relu_nn中train_loss做修改即可: 可以用tf.nn.l2_loss(t)对一个Tensor对象求l2 norm 需要对我们使用的各个W都做这样的计算(参考t
-
本章到目前为止介绍的循环神经网络只有一个单向的隐藏层,在深度学习应用里,我们通常会用到含有多个隐藏层的循环神经网络,也称作深度循环神经网络。图6.11演示了一个有$L$个隐藏层的深度循环神经网络,每个隐藏状态不断传递至当前层的下一时间步和当前时间步的下一层。 具体来说,在时间步$t$里,设小批量输入$\boldsymbol{X}_t \in \mathbb{R}^{n \times d}$(样本数
-
我用newff在Matlab中创建了一个用于手写数字识别的神经网络。 我只是训练它只识别0 输入层有9个神经元,隐层有5个神经元,输出层有1个神经元,共有9个输入。 我的赔率是0.1 我在Matlab中进行了测试,网络运行良好。现在我想用c语言创建这个网络,我编写了代码并复制了所有的权重和偏差(总共146个权重)。但当我将相同的输入数据输入到网络时,输出值不正确。 你们谁能给我指点路吗? 这是我的
-
我正在学习卷积神经网络,并试图弄清楚数学计算是如何发生的。假设有一个输入图像有3个通道(RGB),所以图像的形状是28*28*3。考虑为下一层应用大小为5*5*3和步幅为1的6个过滤器。这样,我们将在下一层得到24*24*6。由于输入图像是RGB图像,每个滤波器的24*24图像如何解释为RGB图像,即每个滤波器的内部构造的图像大小为24*24*3?
-
在LeNet提出后的将近20年里,神经网络一度被其他机器学习方法超越,如支持向量机。虽然LeNet可以在早期的小数据集上取得好的成绩,但是在更大的真实数据集上的表现并不尽如人意。一方面,神经网络计算复杂。虽然20世纪90年代也有过一些针对神经网络的加速硬件,但并没有像之后GPU那样大量普及。因此,训练一个多通道、多层和有大量参数的卷积神经网络在当年很难完成。另一方面,当年研究者还没有大量深入研究参
-
深度神经网络(DNN)是在输入和输出层之间具有多个隐藏层的ANN。 与浅层神经网络类似,DNN可以模拟复杂的非线性关系。 神经网络的主要目的是接收一组输入,对它们执行逐步复杂的计算,并提供输出以解决诸如分类之类的现实世界问题。 我们限制自己前馈神经网络。 我们在深层网络中有输入,输出和顺序数据流。 神经网络广泛用于监督学习和强化学习问题。 这些网络基于彼此连接的一组层。 在深度学习中,隐藏层的数量
-
神经网络和深度学习是一本免费的在线书。本书会教会你: 神经网络,一种美妙的受生物学启发的编程范式,可以让计算机从观测数据中进行学习 深度学习,一个强有力的用于神经网络学习的众多技术的集合 神经网络和深度学习目前给出了在图像识别、语音识别和自然语言处理领域中很多问题的最好解决方案。本书将会教你在神经网络和深度学习背后的众多核心概念。 想了解本书选择的观点的更多细节,请看这里。或者直接跳到第一章 开始