
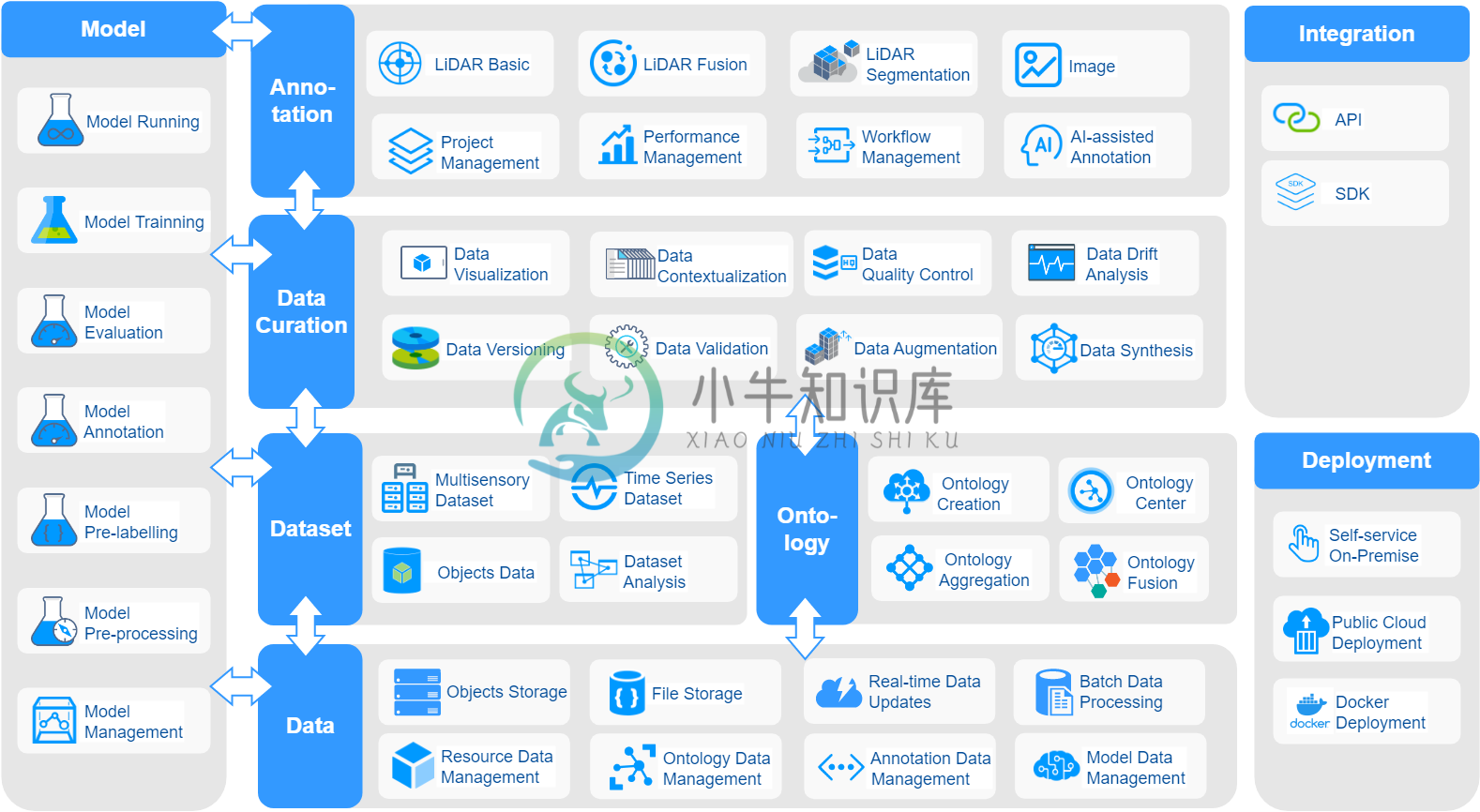
Xtreme1是一个开源的多模态训练数据平台,支持多格式(图片、点云及2D/3D融合)的数据上传、标注和监管。它能够帮助算法工程师和科学家高效标注数据和训练模型。 人工智能生命周期结果可视化,并通过可重复、可管理和自动化来一站式处理机器学习。通过提升数据质量,比如改进数据标签,提高数据标注质量等来提升整个Data-centric MLOps效率。人工智能生命周期结果可视化,并通过可重复、可管理和自动化来一站式处理机器学习。

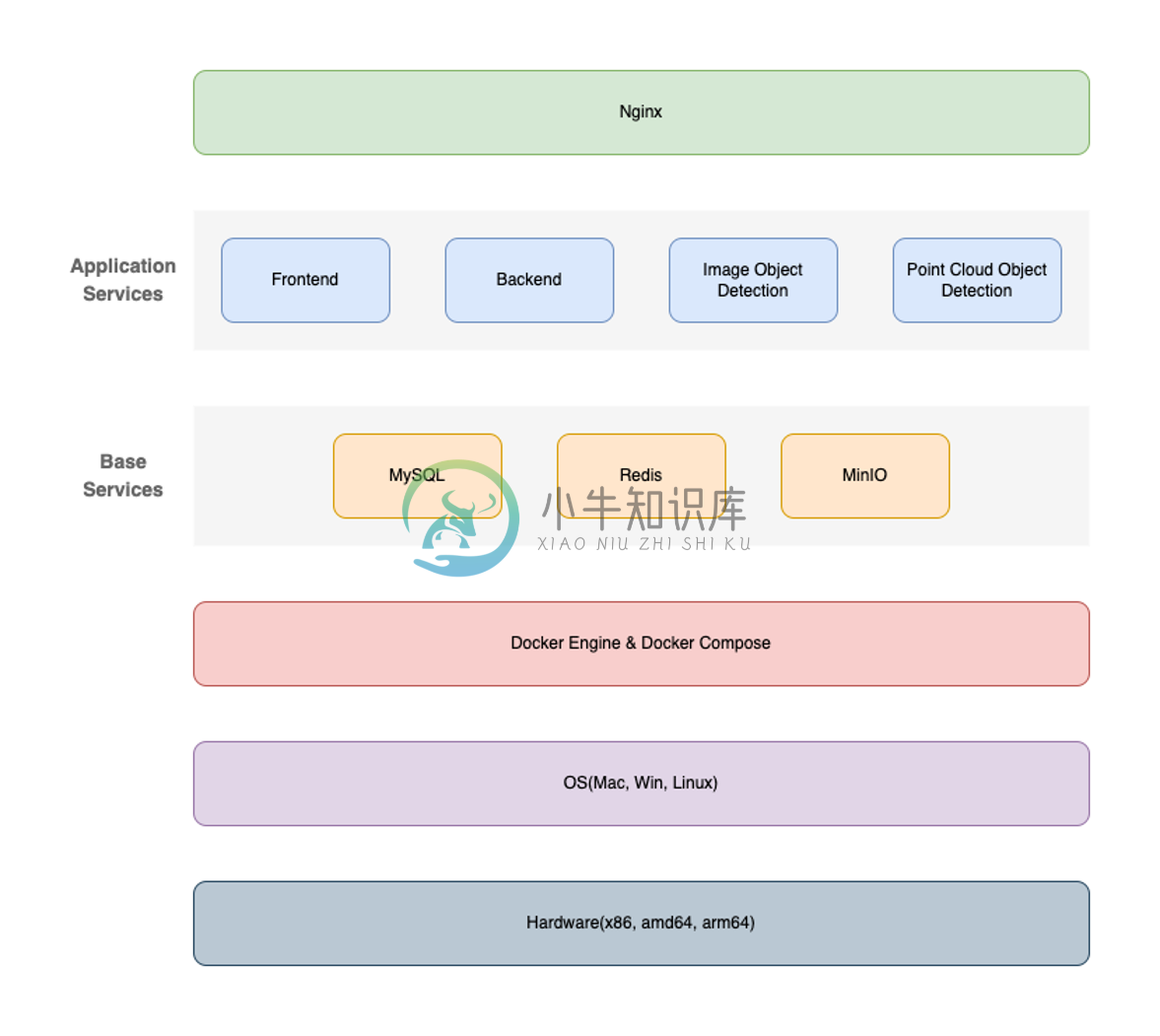
Xtreme1通过Docker Compose/Docker Engine来提供统一的运行环境;前端和后端服务均进行了拆分,可独立升级
-
我可以在AWS Sagemaker中通过评估模型来训练多个模型train.py脚本,以及如何从多个模型中获取多个指标? 任何链接、文档或视频都很有用。
-
在之前的描述中,我们通常把机器学习模型和训练算法当作黑箱子来处理。如果你实践过前几章的一些示例,你惊奇的发现你可以优化回归系统,改进数字图像的分类器,你甚至可以零基础搭建一个垃圾邮件的分类器,但是你却对它们内部的工作流程一无所知。事实上,许多场合你都不需要知道这些黑箱子的内部有什么,干了什么。 然而,如果你对其内部的工作流程有一定了解的话,当面对一个机器学习任务时候,这些理论可以帮助你快速的找到恰
-
在之前的描述中,我们通常把机器学习模型和训练算法当作黑箱子来处理。如果你实践过前几章的一些示例,你惊奇的发现你可以优化回归系统,改进数字图像的分类器,你甚至可以零基础搭建一个垃圾邮件的分类器,但是你却对它们内部的工作流程一无所知。事实上,许多场合你都不需要知道这些黑箱子的内部有什么,干了什么。 然而,如果你对其内部的工作流程有一定了解的话,当面对一个机器学习任务时候,这些理论可以帮助你快速的找到恰
-
为了评估我们的监督模型的泛化能力,我们可以将数据分成训练和测试集: from sklearn.datasets import load_iris iris = load_iris() X, y = iris.data, iris.target 考虑如何正常执行机器学习,训练/测试分割的想法是有道理的。真实世界系统根据他们拥有的数据进行训练,当其他数据进入时(来自客户,传感器或其他来源),经过训
-
Polar Verity Sense 拥有三种训练模式:心率模式、记录模式和游泳模式。 请注意,在记录模式或游泳模式下使用传感器前,需要将传感器连接到您的 Polar Flow 账号。该操作已在设置期间完成。如果您没有按照设置 Verity Sense 中的说明完成设置,则只能在心率模式下使用传感器。 在心率模式下,您可以将传感器连接到兼容的设备或应用,在训练期间实时追踪您的心率。有关详细说明,请
-
问题内容: 我想跑 分句。没有训练模型,因此我将单独训练模型,但是我不确定我使用的训练数据格式是否正确。 我的训练数据是每行一句话。我找不到与此有关的任何文档,只有此线程(https://groups.google.com/forum/#!topic/nltk- users/bxIEnmgeCSM )揭示了一些有关训练数据格式的信息。 句子标记器的正确训练数据格式是什么? 问题答案: 嗯,是的,P
-
问题内容: 因此,我一直遵循Google的官方tensorflow指南,并尝试使用Keras构建一个简单的神经网络。但是,在训练模型时,它不使用整个数据集(具有60000个条目),而是仅使用1875个条目进行训练。有可能解决吗? 输出: 这是我一直在为此工作的原始Google colab笔记本:https ://colab.research.google.com/drive/1NdtzXHEpiN
-
问题内容: 我像这样使用scikit-learn的SVM: 我的问题是,当我使用分类器预测训练集成员的班级时,即使在scikit- learns实现中,分类器也可能是错误的。(例如) 问题答案: 是的,可以运行以下代码,例如: 分数是0.61,因此将近40%的训练数据被错误分类。部分原因是,即使默认内核是(理论上也应该能够对任何训练数据集进行完美分类,只要您没有两个带有不同标签的相同训练点),也可