
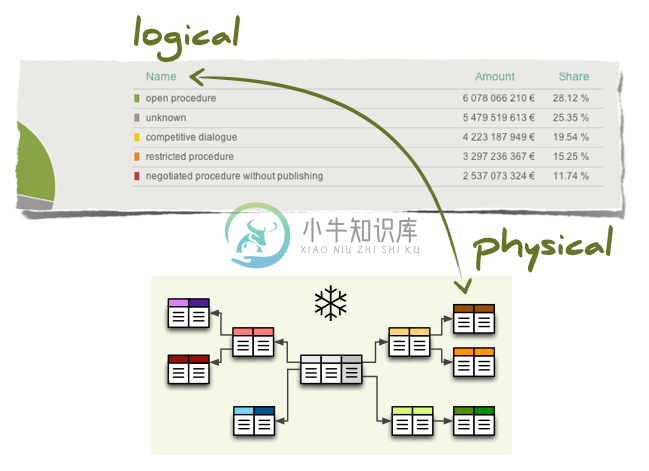
Data Brewery 是一组 Python 框架和工具,用于数据处理和分析。主要功能包括:聚合数据浏览、报表和多维建模。提供一组 OLAP HTTP 服务的轻量级 Python 框架。此外还包括 ETL 数据处理框架,数据审计等。
-
问题背景 Kylin作为一个极其优秀的MOLAP,提供了完整的Cube创建、更新流程。同时提供了Sql查询。功能上看没有问题,但是在提供查询服务的时候还是有些不友好。 sql查询需要常常需要关联Hive表,Cube的作用是对查询做优化,但是用户需要知道hive表结果——为什么不提供接口让用户直接对Cube模型查询呢? 比如,我们用kylin建立了一个Sales Cube,关于公司销售数据统计。维度
-
一、创建索引: 在SQLite中,创建索引的SQL语法和其他大多数关系型数据库基本相同,因为这里也仅仅是给出示例用法: sqlite> CREATE TABLE testtable (first_col integer,second_col integer); --创建最简单的索引,该索引基于某个表的一个字段。 sqlite> CREATE INDEX testtable_idx ON test
-
在现实世界中,我们经常遇到大量原始数据,这些数据不适合机器学习算法。 我们需要在将原始数据输入各种机器学习算法之前对其进行预处理。 本章讨论在Python机器学习中预处理数据的各种技术。 数据预处理 在本节中,让我们了解如何在Python中预处理数据。 最初,在文本编辑器(如记事本)中打开扩展名为.py文件,例如prefoo.py文件。 然后,将以下代码添加到此文件中 - import numpy
-
我有一个场景,文件有不同的类型。文件分为页眉、正文和页脚三部分。标题可以是2类型dipend,根据标题大小,我需要使用标记器和范围来解析内容。 页脚也一样,这取决于正文大小和页脚长度,需要解析页脚内容。 我查看了PatternMatchingCompositeLineMapper和fixedlenghttokenizer,但没有找到为范围指定条件的方法,也没有找到在页脚中共享正文内容以检查长度的方
-
本文向大家介绍分析Mysql事务和数据的一致性处理问题,包括了分析Mysql事务和数据的一致性处理问题的使用技巧和注意事项,需要的朋友参考一下 这篇文章通过安全性,用法,并发处理等方便详细分析了Mysql事务和数据的一致性处理问题,以下就是全部内容: 在工作中,我们经常会遇到这样的问题,需要更新库存,当我们查询到可用的库存准备修改时,这时,其他的用户可能已经对这个库存数据进行修改了,导致,我们查询
-
欢迎使用小米数据处理和分析服务(EMR)使用指南,本指南包含了EMR的基本介绍,以及如何使用EMR。
-
我想创建一个. bat文件,它将显示文件名以“多哥”开头的每个. csv文件的最后一行。批处理文件将与. csv文件位于同一个文件夹中。要输出应该是:[文件名][最后一行数据] 此批处理文件应始终每5分钟运行和测试. csv文件。
-
本文向大家介绍SQLite教程(五):索引和数据分析/清理,包括了SQLite教程(五):索引和数据分析/清理的使用技巧和注意事项,需要的朋友参考一下 一、创建索引: 在SQLite中,创建索引的SQL语法和其他大多数关系型数据库基本相同,因为这里也仅仅是给出示例用法: 从.indices命令的输出可以看出,三个索引均已成功创建。 二、删除索引: 索引的删除和视
-
分析和解读数据 错误检查 试验开始之后的短时间内(几个小时或者1天),我们应该通过实时观察「试验概况」与「指标详情」页面,来检查试验数据是否表现正常,也就是检查是否有程序错误。如果包括原始版本在内的任一版本没有数据显示或者和正常数据相比有很大的、异常的差异,说明试验可能在集成环节出现问题,或者存在程序错误。这时需要停止试验,重新检查调试。 置信区间的解读 若短时间内的数据正常,试验应继续运行至预定