
Druid 是一个高性能实时分析数据库。它是为大型数据集上实时探索查询的引擎,提供专为 OLAP 设计的开源分析数据存储系统,它的设计意图是在面对代码部署、机器故障以及其他产品系统遇到不测时能保持100%正常运行。它也可以用于后台用例,但设计决策明确定位线上服务。
数据流:
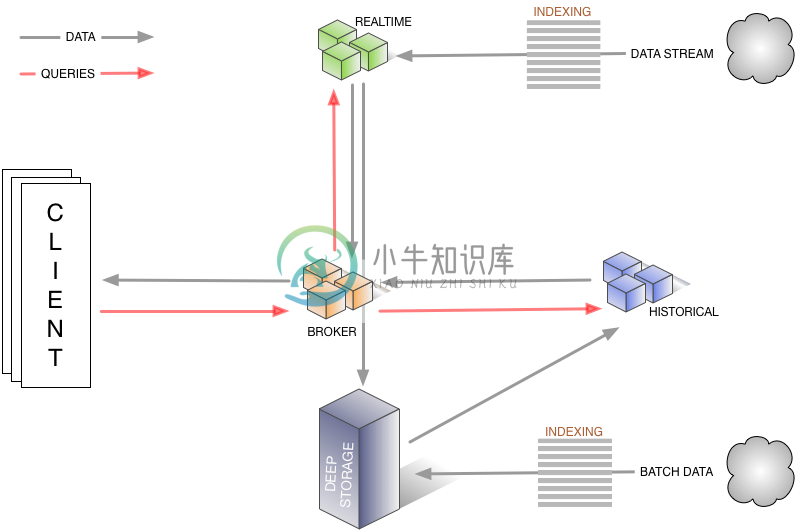
集群架构:
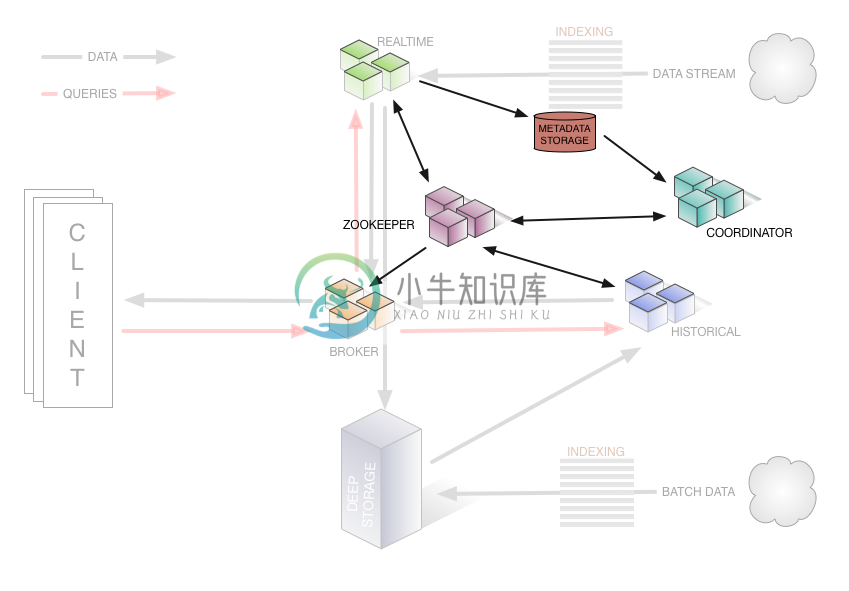
主要特性:
-
为分析而设计——Druid 是为 OLAP 工作流的探索性分析而构建。它支持各种 filter、aggregator 和查询类型,并为添加新功能提供了一个框架。用户已经利用 Druid 的基础设施开发了高级K查询和直方图功能。
-
交互式查询——Druid 的低延迟数据摄取架构允许事件在它们创建后毫秒内查询,因为 Druid 的查询延时通过只读取和扫描优必要的元素被优化。Aggregate 和 filter 没有坐等结果。
-
高可用性——Druid 是用来支持需要一直在线的 SaaS 的实现。你的数据在系统更新时依然可用、可查询。规模的扩大和缩小不会造成数据丢失。
-
可伸缩——现有的 Druid 部署每天处理数十亿事件和 TB 级数据。Druid 被设计成 PB 级别。
-
一 Apache Druid架构 1. Coordinator 监控Historical处理,负责分配segments到指定的服务,确保存在HIstorical中是自平衡的 2. Overlord 监控MiddleManager处理和控制数据加载进druid集群;对分配给MiddleManager的摄取任务和协调segments的发布负责 3. Broker 处理来自客户端的查询,解析将查询重定向
-
Apache druid运行需要依赖其他一些软件环境,所以需要先安装依赖环境,最后再安装druid。 这些依赖的环境包括: jdk zookeeper kafka 1.1 jdk安装 将jdk包下载下来进去下面操作,如果有可以用最下面的命令查看一下版本 # 解压命令 tar -zxf jdk-8u191-linux-x64.tar.gz -C /usr/local/ # 修改配置命令 vi /et
-
1. 加载测试数据 从quickstart/tutorial/wikiticker-2015-09-12-sampled.json.gz数据文件读取wikipedia数据,创建一个名称为deletion-tutorial的数据源 deletion-index.json内容如下,创建的segment为小时粒度 [root@bigdata001 apache-druid-0.22.1]# cat qu
-
此文是根据Apache druid官网资料进行编写,英语不是很好,而且本人还是菜鸟对一些原理和特性还有周边的工具不是很了解,所以很多的内容可能是错误的,如有人看了此文,发现错误的(翻译和理解的错误),请帮忙指正,万分感谢。 jvm配置 -Duser.timezone=UTC 时区设置,默认的,更改可能会有问题,跟北京时间有8小时差。换算为北京时间要+8小时 -Dfile.encoding=UTF-
-
Apache Druid还支持原生的Json格式查询,这里我们只讲解SQL查询。Druid的数据查询底层是通过发送HTTP请求 1. 通过dsql 查询2015年9月12日被编辑最多的10个维基百科页面 [root@bigdata001 apache-druid-0.22.1]# [root@bigdata001 apache-druid-0.22.1]# pwd /opt/apache-dru
-
本文向大家介绍实例分析ORACLE数据库性能优化,包括了实例分析ORACLE数据库性能优化的使用技巧和注意事项,需要的朋友参考一下 ORACLE数据库的优化方式和MYSQL等很大的区别,今天通过一个ORACLE数据库实例从表格、数据等各个方便分析了如何进行ORACLE数据库的优化。 tsfree.sql视图 这个sql语句迅速的对每一个表空间中的空间总量与每一个表空间中可用的空间的总量进行比较 表
-
我们正在快速开发一个应用程序,其中我们需要一次获取超过50K行(在应用程序加载时执行),然后数据将用于应用程序的其他部分进行进一步计算。我们正在使用Firebase实时数据库,我们面临一些严重的性能问题。 它目前需要大约40秒才能加载50K行(目前使用的是免费数据库版本,不确定这是否是原因),但我们也观察到,当多个用户使用该应用程序时,加载50K行开始需要大约1分20秒,Peak达到100%。 您
-
用户期望页面的交互性和流畅。但是在传输到显示器的过程中每个阶段都可能出现闪烁卡顿。 接下来我们将了解用于识别和解决运行时性能降低的常见问题的工具和策略。 TL;DR 不要编写强制浏览器重新计算布局的JavaScript。分离读写函数,并首先执行读取。 不要使您的CSS过于复杂。使用更少的CSS和保持你的CSS选择器简单。尽可能多避免layout。 总是选择不触发layout的CSS。 绘画可能占用
-
问题内容: 我需要一些想法来实现Java的(真正)高性能内存数据库/存储机制。在存储20,000+个Java对象的范围内,每5秒钟左右更新一次。 我愿意接受的一些选择: 纯JDBC /数据库组合 JDO JPA / ORM /数据库组合 对象数据库 其他存储机制 我最好的选择是什么?你有什么经验? 编辑:我还需要能够查询这些对象 问题答案: 您可以尝试使用Prevayler之类的工具(基本上是一个
-
本章主要介绍诸葛io的高级分析功能,包括: 广告监测 搜索关键词广告(SEM) 产品版本分析 网页端获取分析 APP获取分析 行为路径 用户粘性分析 SQL查询 跨平台分析 我们在官网Demo中开放了所有付费功能的试用体验,如您想了解更多内容,可以通过在线客服或客服电话与我们取得联系:40080-94843
-
问题内容: 我在公司中多次设计数据库。为了提高数据库的性能,我只寻找标准化和索引。 如果要求您提高数据库的性能,该数据库包含大约250个表以及一些具有数百万个记录的表,那么您将寻找什么不同的东西? 提前致谢。 问题答案: 优化逻辑设计 逻辑级别是关于查询和表本身的结构。首先尝试最大程度地发挥这一作用。目标是在逻辑级别上访问尽可能少的数据。 拥有最高效的SQL查询 设计支持应用程序需求的逻辑架构(例
-
我正在写一份棘手的申请书。该应用程序运行在64位八核linux机器上 Netty应用程序是一个简单的路由器,它接受请求(传入管道),从请求中读取一些元数据,并将数据转发给远程服务(传出管道)。 此远程服务将向传出管道返回一个或多个响应。Netty应用程序将把响应路由回发起客户端(传入管道) 会有成千上万的客户。将会有成千上万的远程服务。 我正在做一些小规模的测试(十个客户端,十个远程服务),但我没
-
性能分析 StackExchange.Redis 公开了少量的方法和类型来开启性能分析。由于其异步性和多路复用行为,性能分析是一个有点复杂的话题。 接口 性能分析接口是由这些组成的:IProfiler,ConnectionMultiplexer.RegisterProfiler(IProfiler),ConnectionMultiplexer.BeginProfiling(object), Con