
-
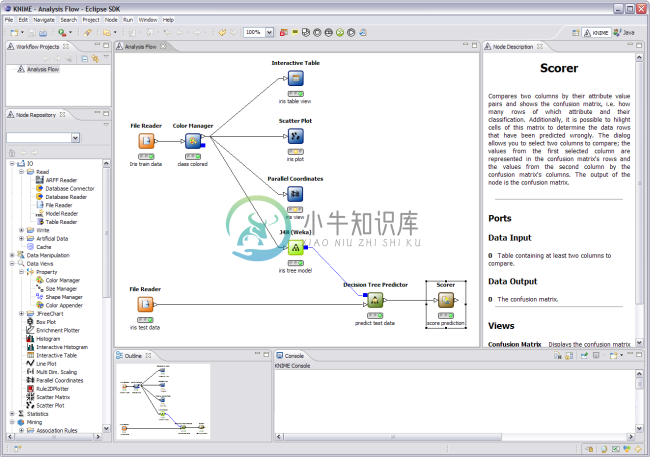
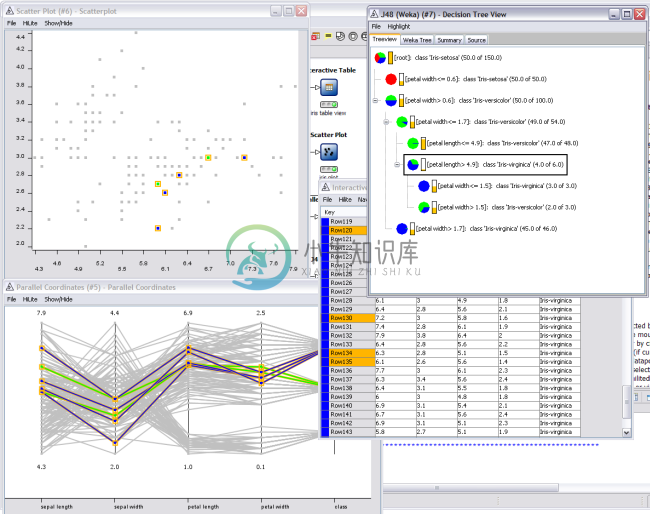
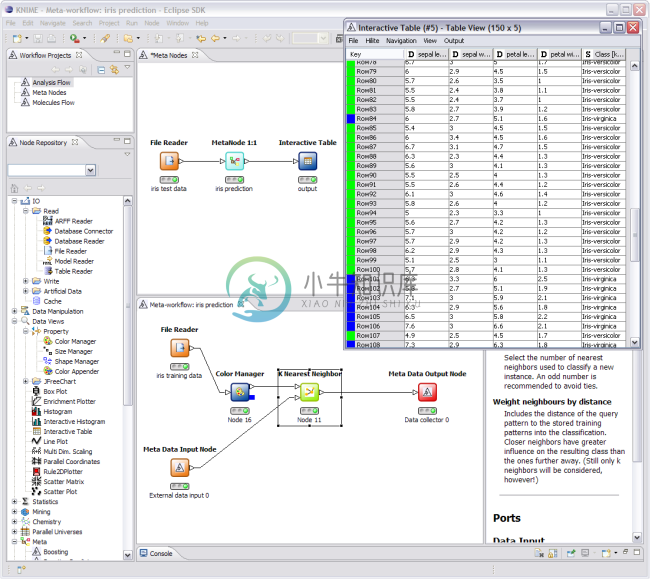
knime简介 Data Science is abounding. It considers different realms of the data world including its preparation, cleaning, modeling, and whatnot. To be precise, it is massive in terms of the span it cove
-
一、创建索引: 在SQLite中,创建索引的SQL语法和其他大多数关系型数据库基本相同,因为这里也仅仅是给出示例用法: sqlite> CREATE TABLE testtable (first_col integer,second_col integer); --创建最简单的索引,该索引基于某个表的一个字段。 sqlite> CREATE INDEX testtable_idx ON test
-
在现实世界中,我们经常遇到大量原始数据,这些数据不适合机器学习算法。 我们需要在将原始数据输入各种机器学习算法之前对其进行预处理。 本章讨论在Python机器学习中预处理数据的各种技术。 数据预处理 在本节中,让我们了解如何在Python中预处理数据。 最初,在文本编辑器(如记事本)中打开扩展名为.py文件,例如prefoo.py文件。 然后,将以下代码添加到此文件中 - import numpy
-
我有一个场景,文件有不同的类型。文件分为页眉、正文和页脚三部分。标题可以是2类型dipend,根据标题大小,我需要使用标记器和范围来解析内容。 页脚也一样,这取决于正文大小和页脚长度,需要解析页脚内容。 我查看了PatternMatchingCompositeLineMapper和fixedlenghttokenizer,但没有找到为范围指定条件的方法,也没有找到在页脚中共享正文内容以检查长度的方
-
社招,录取,一共三轮面试。 一面:自我介绍,问简历相关项目,出题:有5000万条车险顾客数据,已知其中的500万的用户有宠物,如何对其他4500万用户精准推荐宠物险。 二面:自我介绍,提问他们更换模型时,生效有延迟怎么处理。 三面:自我介绍,知道哪些机器学习算法,决策树原理,协方差作用。 HR谈薪:薪资构成:12个月加年终奖。三个月试用期,试用期间工资八折,年终奖发放看考核分数所处区间系数。 拒绝
-
本文向大家介绍分析Mysql事务和数据的一致性处理问题,包括了分析Mysql事务和数据的一致性处理问题的使用技巧和注意事项,需要的朋友参考一下 这篇文章通过安全性,用法,并发处理等方便详细分析了Mysql事务和数据的一致性处理问题,以下就是全部内容: 在工作中,我们经常会遇到这样的问题,需要更新库存,当我们查询到可用的库存准备修改时,这时,其他的用户可能已经对这个库存数据进行修改了,导致,我们查询
-
欢迎使用小米数据处理和分析服务(EMR)使用指南,本指南包含了EMR的基本介绍,以及如何使用EMR。