
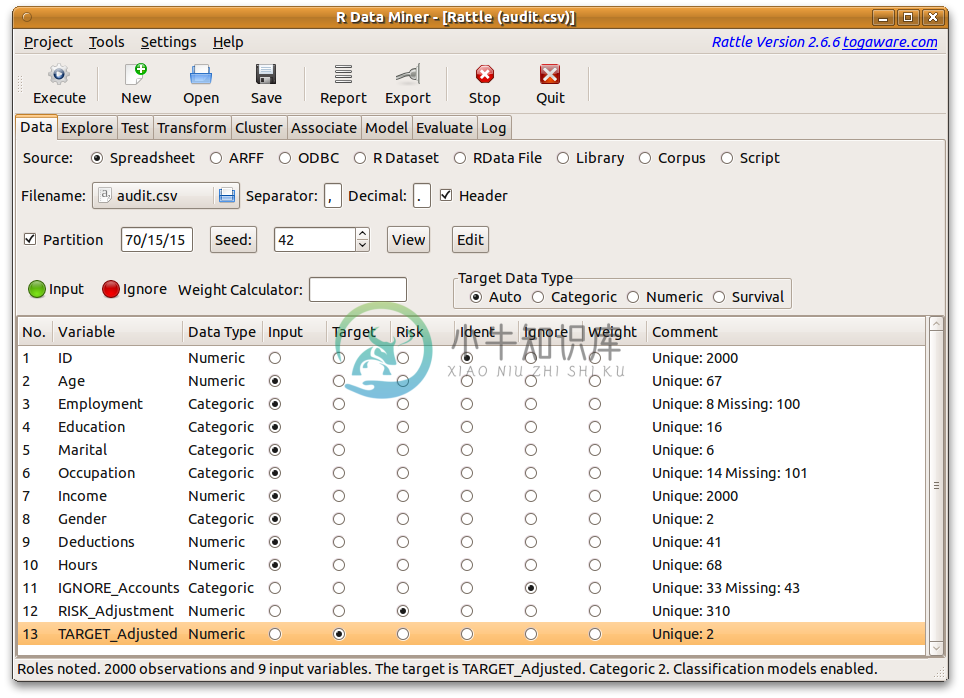
Rattle 是一个用于数据挖掘的R的图形交互界面(GUI),可用于快捷的处理常见的数据挖掘问题。从数据的整理到模型的评价,Rattle 给出了完整的解决方案。Rattle 和 R 平台良好的交互性,又为用户使用 R 语言解决复杂问题开启了方便之门。Rattle 易学易用,不要求很多的R语言基础,被广泛的应用于数据挖掘实践和教学之中,在澳大利亚,有至少 15 个政府部门采用 Rattle 作为标准的数据挖掘工具
-
助人为乐了,没想到我也有今天(狗头)。昨天帮商科舍友装Rattle, 算是让我想起以前远程Ubuntu服务器的痛苦回忆了。不过其实对于新手的干干净净的电脑来说从头装比几十个版本的Python和balabala软件相互限制要好处理的多。总的来说,就这个经历来说最难的不是装和解决问题的过程,是从超级大数据网络下搜索出来适合她的电脑情况的最靠谱有效的安装步骤的过程。 问题分析 首先她为什么自己装不上,是
-
1. 安装3.6.3版本的R 链接:https://cran.r-project.org/bin/windows/base/old/3.6.3/ 2. 安装RGtk2 install.packages("https://cran.microsoft.com/snapshot/2021-12-15/bin/windows/contrib/4.1/RGtk2_2.20.36.2.zip",
-
R语言图形用户界面数据挖掘包Rattle介绍、安装、启动、介绍(Using the rattle package for data mining) 目录
-
Rattle使用RGtk2 包提供的Gnome图形用户界面,可以在WINDOWS, MAC OS/X,Linux等多个系统中使用。 Rattle基于大量的R包:RGtk2, pmml, colorspace, ada, amap, arules, biclust, cba, descr, doBy, e1071, ellipse, fEcofin, fBasics, foreign, fpc, g
-
数据挖掘 18 大算法实现以及其他相关经典 DM 算法,BIRCH 算法本身上属于一种聚类算法,不过他克服了一些 K-Means 算法的缺点。
-
一位挖掘专家 tom khabaza 提出了挖掘九律,挺好的东西,特别是九这个数字,深得中华文化精髓,有点独孤九剑的意思: 第一,目标律。 数据挖掘是一个业务过程,必须得有业务目标。无目的,无过程。 第二,知识律。 业务知识贯穿在挖掘这个业务过程的各环节。 第三,准备律。 数据获取、数据准备等数据处理耗时占整个挖掘过程的一半。 第四,NFL律。 NFL,没有免费的午餐。没有一个固定的算法适用所有的
-
字节跳动 (1h) 1.自我面试 2.挑一个你认为比较成功的项目进行介绍? 3.介绍你做过的特征工程 4.你都有过哪些算法?介绍下随机森林、XGB、GBDT的差异 5.对模型进行评估时候选取的方法 携程控股(45min) 1.自我介绍 2.选择一个项目进行介绍 3.你建模的时候都用到哪些方法 4.项目细节 5.模型评估 腾讯科技(1个小时) 1.自我介绍 2.直接问项目 3.解释下随机森林和GBD
-
硕士研究cv 可能和数据挖掘不是那么匹配~ 大华一面(1h): 1、增量学习的科研项目(问了具体的细节 以及为什么) 2、语义分割的发展 3、UNet中的跳跃连接的作用 4、残差网络的shortcut连接的作用,数学方面证明残差网络可以避免梯度消失,并且问了一个关于残差网络的改进问题(面试官看最新的论文看到的,我没有理解他所说的问题) 5、宫颈肿瘤分割和pcr预测的项目(细节也问的很详细) 6、预
-
数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
-
1.1 KNN 1.1.1 思想 计算离待分类点距离最近的 K 个已分类点,K 个点中出现最多点种类为待分类点的种类。 1.1.2 距离 常见距离有欧式距离和余弦距离。余弦距离可以消除量纲的影响。相关系数 2. 聚类算法 2.1 K-means 2.1.1 思想 2.1.1.1 模型训练 根据类别个数 N,初始化 N 个点,作为该类别的中点。 遍历其他点,计算距离最近的中心点,该中心点的类别为当前
-
2道编程共40分,5道问答110分,共两个半小时,没做多久就退出来,哎。。。 有一道编程题用例过了,一提交通过0个用例,麻了 大佬给看看: 题目是车牌号识别准确率计算 输入N个车牌号,第一个字母是颜色,最后5个是号码,中间是地区号 每一行一个识别出的号码,一个真实标签 #我的秋招日记##网易雷火笔试##23届秋招笔面经#
-
时间过去有点久了,纯凭回忆,可能有些遗漏 一面 (1小时多吧) 机器学习基础知识 Bagging & Boosting 常用的聚类算法 Kmeans和DBSCAN的原理和区别 逻辑回归的原理 怎么处理离散数据 支持向量机原理 SVM怎么处理非线性 常用的回归模型 Attention原理 RNN和LSTM的区别 什么是梯度爆炸/梯度消失,什么情况下会出现 梯度渐进的原理 手撕算法 判断是否是回文 找