
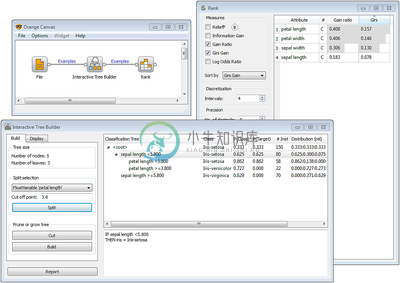
Orange 是一个基于组件的数据挖掘和机器学习软件套装,它的功能即友好,又很强大,快速而又多功能的可视化编程前端,以便浏览数据分析和可视化,基绑定了 Python以进行脚本开发。它包含了完整的一系列的组件以进行数据预处理,并提供了数据帐目,过渡,建模,模式评估和勘探的功能。其由C++ 和 Python开发,它的图形库是由跨平台的Qt框架开发。
-
1、conda create -n orange3 python=3.5 创建一个环境 2、activate orange3 激活orange环境 3、conda config --add channels conda-forge 4、(1)conda install orange3 或者(2)pip install orange3 如果上面两种方法由于网络问题老是出现Readtime out 的
-
一、安装orange3 python版本 3.6.8 pip install orange3 pip install PyQt5 学习官网:OWWidget — Orange Development 3 documentation The Data — Orange Data Mining Library 3 documentation Orange Data Mining - Blogs 启动命
-
Data mining 一种从大量数据中提取知识的过程,它涉及到统计学、机器学习和人工智能等多个领域。 它通常使用计算机程序来分析数据,发现潜在的关系或规则,并产生有用的信息。 常见技术 包括: 聚类分析、 分类器、 关联规则挖掘 回归分析。 data mining学习平台(网站): KDnuggets:该网站提供与data mining相关的新闻、教育资源和工具等。 Journal of Dat
-
From: http://blog.samibadawi.com/2010/04/r-rapidminer-statistica-ssas-or-weka.html You have a data mining problem and you want to try to solve it with a data mining software package. The most popular
-
Text-Mining-DataCamp-Text Mining: Bag of Words 1. Jumping into Text Mining with Bag of Words 1.1 What is text mining? (video) 1.2 Understanding text mining 1.3 Quick taste of text mining Instruction:
-
http://blog.csdn.net/pipisorry/article/details/52845804 orange的安装 linux下的安装 先安装依赖pyqt4[PyQt教程 - pythonQt的安装和配置及版本间差异] pip install orange3 检查是否安装成功 import Orange 运行GUI界面 alias orange 'python3 -m Orange
-
五个免费开源的数据挖掘软件 Orange Orange 是一个基于组件的数据挖掘和机器学习软件套装,它的功能即友好,又很强大,快速而又多功能的可视化编程前端,以便浏览数据分析和可视化,基绑定了Python以进行脚本开发。它包含了完整的一系列的组件以进行数据预处理,并提供了数据帐目,过渡,建模,模式评估和勘探的功能。其由C++ 和 Python开发,它的图形库是由跨平台的Qt框架开发。 Rapi
-
http://www.lfd.uci.edu/%7Egohlke/pythonlibs/ 下载Orange3 以及 依赖包 注意网页上标出的Orange 的依赖,以及 https://github.com/biolab/orange3 列出的依赖。 注意安装顺序: 先安装 PyQt5 , 再安装 AnyQt 可能需要安装 Microsoft Visual C++ Compiler for Pyth
-
感谢团子解救,笔试面试实在太累了,暑期就到此为止吧
-
1. 手撕,给出中序遍历和后序遍历,构建树 2. 介绍树模型,(GBDT,XGBoost等) 3. 项目为什么用XGBoost 4. 介绍LR 6. XGB和LR的区别,各适用哪些场景。 7. 项目中Lovain算法是个什么算法。 8. 项目中使用的评价指标 9. 准确率有什么缺点和问题 10. AUC 11. 优化算法 12. 激活函数 13. 特征提取方法? 14. CNN和MLP区别,CNN
-
一面 问实习 问的比较详细 然后问基础 XGBOOST算法详细介绍 XGBOOST算法与LightGBM区别 怎么筛选数据特征以及PCA怎么做 欠拟合怎么解决 注意不是过拟合 还问了一个业务问题 因为可能是美团平台事业部 写代码 leetcode 322 零钱兑换 要求同时输出零钱数量 以及 零钱组合 动态规划 粗心了 最开始只写了零钱数量 SQL 代码 比较简单 两个情形 一个题目 面试官水平挺
-
地图出行服务业务部-T联合 (一面已凉 投递时间:7.11(第一次投递的挂掉了) 变更岗位:7.26 测评邮件:7.26 面试时间:7.30 15:00,挂得很快,吃完饭回来就挂了 总时长:80min,其中项目40min 1、之前在百度做的岗位信息爬取和我的论文有什么关系,为什么离职了? 2、论文里的损失解释一下,设计的模型是微调的 or 预训练的? 3、比赛是自己做的还是组里合作的 4、tran
-
7.30一面 1.自我介绍 2.纯问项目,主要就是让讲项目,做这个项目的背景,以及具体思路。 3.手撕,(给一个有问题的路径,返回正确路径)
-
#美团求职进展汇总# #你收到了团子的OC了吗# 美团履约平台技术部,配送时间策略组 自我介绍,问了我学校和清华什么关系 1、上来一道算法题:找最长的回文串。用动态规划dp秒了。然后问怎么优化空间复杂度,想到从两遍同时找最长回文串来做。 2、然后根据简历来问,没想到简历拿错了,没拿我最新更新的简历。让我讲最拿手的项目。我共享屏幕展示了我最新的简历,讲我的SCI科研项目讲了半个小时。 3、问我ten
-
到这里为止,所有流程都走完了。 9月8日 一面,当天出结果 9月12日 二面,当天出结果 9月14日 三面,次日出结果 9月19日 hr面 1. hr上来先介绍了一下这个岗位未来具体做的事情,介绍的很详细。 2. 让我自己讲讲对这个岗位的理解 3. 自我介绍 4. 聊天 ①职业规划 ②你说你是美团的忠实用户,你可以聊聊你自己对美团的印象吗 (本人是究极吃货+旅游爱好者,出去旅游几乎全靠美团订酒店+
-
9月8日 一面,当天出结果 9月12日 二面,当天出结果 1. 自我介绍 2. 项目介绍,围绕项目出发询问一些相关的问题。这个过程在15分钟左右。 3. :你前面写题了吗 我:一面写了,二面没写 4. 在我以为要出题的时候,没有了……进入反问环节 我:啊!怎么这么快 :因为我们这个三轮的技术面是一个综合的评估,有些问题前两面面过了,就没必要再问了 后续流程:说本次面试的结果很快就会出。还剩最后一轮