《中邮消费金融》专题
-
根据Kafka分区的数量动态调整消费者线程的数量
我有一个Kafka主题,有50个分区 My Spring Boot应用程序使用Spring Kafka通过读取这些消息 Kubernetes中应用程序自动缩放的实例数。 默认情况下,Spring Kafka似乎每个主题启动1个消费者线程。 因此,对于应用程序的唯一实例,一个线程正在读取50个分区。 对于2个实例,有一个负载平衡,每个实例侦听25个分区。每个实例仍然有1个线程。 我知道我可以使用上的
-
ActiveMQ:消费者/生产者为同一个队列实现不同的协议?
我最近开始使用消息队列(使用ActiveMQ),并进行了试验。 null 谢谢你的建议,
-
来自不同群体的Kafka消费者来自不同的主题划分
我有一个场景,我已经在不同的节点上部署了4个Kafka消费者实例。我的主题有4个分区。现在,我想配置消费者,使他们都从主题的不同分区获取。 我知道一个事实,如果消费者来自同一个消费者组,他们会确保分区被平分。但在我的情况下,他们不在同一组。
-
MassTransit消费者传奇能由它所策划的相同信息发起吗?
7.0中对Event Hub Riders的新支持,加上现有的对Sagas的支持,似乎可以提供一种基于相关消息流(例如,在建筑物中的所有传感器之间)创建聚合状态的简单方法。在这个场景中,建筑物的标识符将用作消息的CorrelationId、Saga和发送到事件集线器的EventData消息的PartitionKey,以确保同一消费服务实例在给定时间接收该设备的所有消息。根据Event Hub重新平
-
LMAX Disruptor Producer在消费者完成之前错误地包装覆盖阅读
我最近被介绍给LMAX Disruptor,并决定试一试。多亏了开发人员,安装速度很快,没有任何麻烦。但如果有人能帮我,我想我遇到了一个问题。 问题:有人告诉我,当制作人发布活动时,它应该阻止,直到消费者有机会在包装之前取回它。我在消费者方面有一个序列障碍,我可以确认,如果生产者没有发布数据,消费者的waitFor呼叫将被阻止。但是,生产者似乎并没有受到任何监管,只会在环形缓冲区中封装并覆盖未处理
-
KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?
本文向大家介绍KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?相关面试题,主要包含被问及KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?时的应答技巧和注意事项,需要的朋友参考一下 1.在每个线程中新建一个KafkaConsumer 2.单线程创建KafkaConsumer,多个处理线程处理消息(难点在于是否要考虑消息顺序性,offset的提交方式)
-
如何更改Kafka提交的消费者偏移量与所需偏移量
我有Kafka流应用程序。我的应用程序正在成功处理事件。 如何使用重新处理/跳过事件所需的偏移量更改Kafka committed consumer offset。我试过如何更改topic?的起始偏移量?。但我得到了“节点不存在”错误。请帮帮我。
-
在本地执行模式下停止/启动Kafka消费者/生产者流
设置: Java 8 创建了一个简单的示例程序,以使用来自一个Kafka主题的1M消息并生成到另一个主题-以本地执行模式运行。这两个主题都有32个分区。 当我让它从头到尾运行时,它会消耗并生成所有消息。如果在完成之前启动然后停止(SIGINT),然后再次重新启动,则生产者仅接收原始1M消息的子集。 我已经确认了我对消费者的补偿,它阅读了所有1M消息。 -- 在本地执行模式下,这是预期的吗?是否需要
-
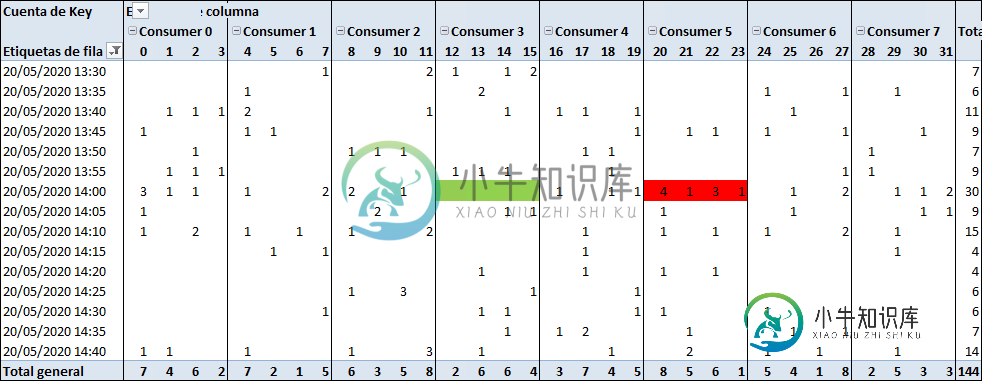 多个Kafka制作人都在写同一个主题-如何平衡消费
多个Kafka制作人都在写同一个主题-如何平衡消费所以我有一个设计,其中我有多个生产者P1、P2、P3、P4... PN写入单个主题T1,它有32个分区。 另一方面,我在一个消费者组中最多有32个消费者。 我想负载平衡我的消息消耗 阅读文档时,我可以看到3个选项: 1。自己定义分区(缺点是我必须知道最后一条消息发送到哪里,或者为每个生产者定义分区范围P) 2。定义一个密钥并将分区决定权交给Kafka哈希算法(缺点-负载平衡将在运气好的情况下定义)
-
如何解决Kafka暴风雨,只有消费者从Kafka的一半数据?
我在Apache/Storm/external/storm-kafka-client中使用Storm Kafka Spout的storm-kafka-client和新的Kafka Consumer API。我的拓扑如下所示: 当我将kafkaspout.java更改为打印consumerRecords的偏移量时,我发现跳过了一些偏移量。跳过http://7xtjbx.com1.z0.glb.clo
-
Google Play计费(测试模式):为什么我的购买会自动取消
我遵循了Google Developer Doc的所有最佳实践:https://developer.android.com/google/play/billing/billing_library_overview 我在 Beta 测试模式下推送我的应用。一切都很完美,除了每次我进行应用内(或订阅)购买时,我都会收到一封电子邮件(购买确认,OK),然后5-6分钟后,我收到另一封电子邮件(始终来自Go
-
Spring Cloud Stream Kafka-Streams无法为我的消费者和生产者配置SSL
我正在努力为Kafka-Streams正确配置Spring Cloud Stream,以便使用带有信任存储和密钥存储的SSL。 在我的应用程序中,我有多个流正在运行,所有流的SSL配置应该是相同的。 stream2:Topic2>Topic4 Topic3 stream3:Topic4>Topic5 我使用最新的Spring-Cloud Stream框架和Kafka-Streams以及Avro模型
-
多个生产者和消费者多线程Java不能按预期工作
我正在与Java一起研究生产者-消费者问题的多生产者和消费者用例。代码在GitHub上。同样的实现适用于单个生产者和消费者用例,但对于多生产者和消费者用例却表现得很奇怪。 我有一些关于输出的问题: 一开始,所有生产者和一个消费者都有锁: 我想所有的线程都应该竞争锁,并且最多应该有一个线程拥有所有时间的锁?是不是所有的制作人都共用这个锁?当生产者线程t1持有锁时,使用者线程t5是如何获得锁的? 它运
-
Kafka Streams API使用与Streams配置不同的消费者引导服务器
-
Kafka:消费者补偿如何与动态创建的组ID一起工作?
在Kafka中,每个消费群体都由一个独特的群体来代表。id属性。每个消费者组管理自己的偏移量(存储在_消费者_偏移量主题中)。如果我总是用一个动态生成的组启动我的消费者服务,那么这个偏移量会发生什么。身份证价值? 这个新的消费群体是否总是从主题的开头开始阅读,因为它没有偏移量,还是将“自动”。抵消重置生效?