《中邮消费金融》专题
-
如何使用Python imaplib回复电子邮件并包含原始消息?
问题内容: 我目前正在使用从服务器获取电子邮件并处理内容和附件的方法。 我想以状态/错误消息回复这些消息,并链接到我的网站上生成的结果内容(如果可以处理)。这应包括原始消息,但应删除所有附件(附件很大),最好仅用其文件名/大小替换它们。 由于我已经遍历了MIME消息部分,因此我假设需要做的是构建一个包含原始消息副本的新MIME消息树,并删除/替换附件节点。 在我走这条路之前,我希望有人能给我一些提
-
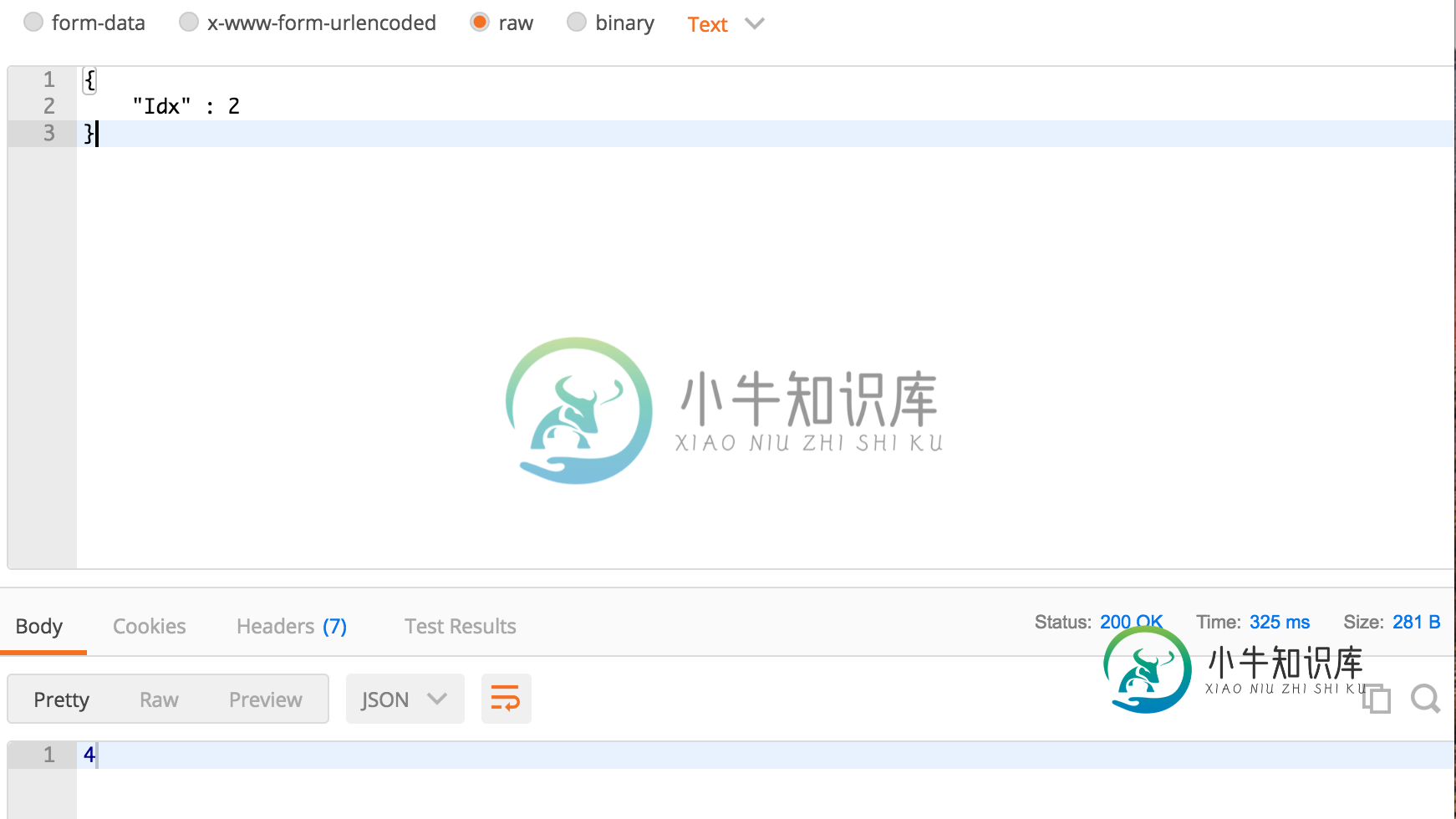 当我从邮递员那里发送消息时,如何接收参数
当我从邮递员那里发送消息时,如何接收参数我通过邮递员将参数发送到api网关并收到结果。所以我在lambda中尝试了一个简单的例子, 当我发送Idx时,它会回调两倍。 我在身体中选择原始,这样我就可以收到结果 但是,我将“Content Type”:“application/x-www-form-urlencoded”放在Headers部分,选择x-www-form-urlencoded,它返回这个。 我想收到邮递员通过x-www. fo
-
如何用PowerShell和EWS将邮件消息导出到EML或MSG文件
我目前正在编写一个PowerShell脚本,它需要从特定邮箱中提取所有邮件作为.eml或.msg文件,并将它们保存在备份服务器上。我将powershell版本5与Exchange 2010管理控制台模块(EWS)一起使用。 目前,我的脚本能够访问收件箱文件夹中的所有邮件及其属性,如正文、主题、附件等。然而,我找不到一种简单的方式或方法来导出消息(及其附件)。所以我的问题是,Exchange 201
-
JDK8中PermGen的消除
我已经安装了JDK8,并尝试运行Eclipse。我收到以下警告消息: 忽略这个VM选项的原因是什么?
-
在swing中在JTable中撤消
-
关于使用阻塞队列方法的Java生产者和消费者模式
问题内容: 我正在研究有关Java中线程的生产者和消费者设计模式,最近我在Java 5中进行了探索,引入Java 5中引入了BlockingQueue数据结构。现在,它变得更加简单,因为BlockingQueue通过引入阻塞方法隐式地提供了此控件。 put()和take()。现在,您无需使用等待和通知即可在生产者和消费者之间进行通信。如果有界队列,则如果Queue已满,BlockingQueue
-
使用高级消费者读取Kafka日志时的激励分区滞后值
我们所有的30个主题都是用kafka中的10个分区创建的。我们正在按分区监控所有主题/group p-id的滞后。 我们正在使用Fluentd插件从kafka读取和路由日志。该插件是使用高级消费者实现的。我们为插件的单个主题配置了一些消费者,为多个主题配置了一些消费者。总的来说,除了3个主题之外,数据正在流经,没有问题。 问题是,对于正在处理的30个主题中的3个,我们发现分区滞后值不一致,即查看特
-
用于获取偏移量和消费者组详细信息的ConFluent CLI命令
嗨,我在寻找一个汇合的cli命令来使用GetOffsetShell获得最早和最新的偏移,并获得消费者团体的细节。 寻找以下kafka命令的汇合cli命令, 获取偏移详细信息 正在获取消费者组列表 描述消费群体 有人能帮助我使用融合cli命令获得这些命令的功能吗?
-
Spring Kafka 消费者:有没有办法使用 Kafka 0.8 从多个分区读取?
这是一个场景:我知道,使用与Spring kafka相关的最新API(如Spring集成kafka 2.10),我们可以执行以下操作: 以及来自与相同kafka主题相关的不同分区的读取。 我想知道我们是否可以使用同样的方法,例如spsping-集成-Kafka1.3.1 我没有找到任何关于如何做到这一点的提示(我对xml版本很感兴趣)。
-
 2022 信也科技(23届秋招)消费场景前端一二三面面经
2022 信也科技(23届秋招)消费场景前端一二三面面经信也科技前端面经也太少了,就让我来补充一点吧(好像信也科技的前身是拍拍贷,这个公司出名一些,搜这个的面经会多些) 一面 日期:2022/11/7 自我介绍 如何去做的移动端的适配? 是如何做的适配?如何设置的 大小? 有没有了解过其它的适配方案?(我说了阿里的 和 方案,以及设置 的两种方式) 有没有了解过 和 的适配方式 介绍一下实习里面虚拟列表的实现 如何计算十万级数据加载的时间?(使用 这个
-
使用Spring Cloud stream kafka绑定消费者和启用DLQ覆盖重试尝试
我正在使用带有kafka绑定的spring cloud streams。消费者使用spring进行配置。云流动Kafka。绑定。功能配置和DLQ已启用。 当我使用来自主题的消息并发生异常时,我看到它重试3次,并将消息发送到DLQ。我已将maxAttemts配置为5,但我无法覆盖默认值3。 我使用的是spring kafka(2.7.8)和spring cloud(2020.0.4)。如何覆盖重试尝
-
消费者轮询未从具有3个分区的Kafka主题获取记录
注:使用的Kafka版本:Kafka2.11-0.9.0.1 我有一个名为测试Kafka的主题,它是三个分区和一个复制因子,这个主题在每个分区中都有一些字符串数据,即键和值对。 当我试图通过消费者api获取记录时,消费者。轮询函数不获取任何记录并给出记录。count=0,但是,当我使用相同的逻辑时,只有一个单分区,那么它工作良好并获取记录。 我以为Kafka会在内部处理多个分区,并从每个分区中逐个
-
从Kafka消费,使用Kafka方法和火花流给出了不同的结果
我正在尝试使用spark Streaming从Kafka中消耗一些数据。 我创造了2个工作岗位, 一个简单的Kafka作业,它使用:
-
SpringKafka2.2。2消费者只返回一条记录,而不是最大轮询记录
我们正在使用Spring Kafka 2.2.2版本从Kafka中检索记录,使用@KafkaListener和Con电流tKafkaListenerContainerFactory。我们已经配置了max-pore-记录为5,但是它总是在列表中只给消费者1条记录,而不是5条记录。 虽然配置相同,但它在Spring Kafka 2.1中也能工作。4.释放。 这是我们的申请表。yml配置: 以下是我们的
-
broker失败时集群ActiveMQ Artemis和生产者/消费者负载平衡配置
这会影响到最初连接到broker1的消费者,我不确定是否还有某种方法/配置使他们在这些代理之间透明地跳转,或者我是否需要创建两个消费者(实际上其中一个是空闲的),每个消费者都针对相应的代理?