
多个Kafka制作人都在写同一个主题-如何平衡消费

所以我有一个设计,其中我有多个生产者P1、P2、P3、P4... PN写入单个主题T1,它有32个分区。
另一方面,我在一个消费者组中最多有32个消费者。
我想负载平衡我的消息消耗
阅读文档时,我可以看到3个选项:
1。自己定义分区(缺点是我必须知道最后一条消息发送到哪里,或者为每个生产者定义分区范围P)
2。定义一个密钥并将分区决定权交给Kafka哈希算法(缺点-负载平衡将在运气好的情况下定义)
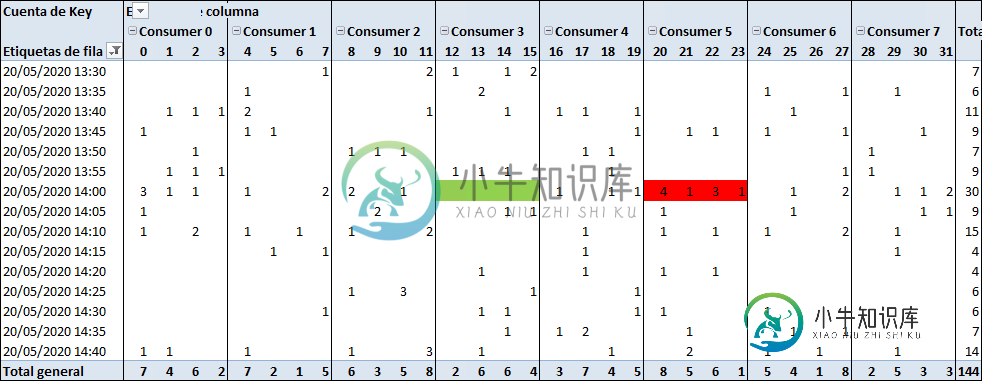
(根据Chris的回答,负载平衡应该交给哈希算法)-事实表明,这并不能为消费者提供平等的分布,因为消费者绑定到分区,我必须了解哈希算法才能选择一个好的密钥-对我来说,这听起来与选择分区(必须在生产者之间分配)是一样的。我当前的代码使用UUID作为键。对所选分区的分析,以及对工作的消费者的分析,显示了一种可能远远不相等的分布。我在下面复制它:

我真的需要自己编写整个负载平衡算法吗?我错过什么了吗?
共有1个答案

在消费者之间平衡负载是Kafka允许水平扩容的定义特性之一。
生产者使用的记录键是使其工作的原因。该键定义了消息进行的分区,并且任何分区都将被一个消费者按顺序消费,因此您的生产者应该使用一个键策略来产生均匀的传播,并确保相关消息在排序很重要时具有相同的键(请记住,如果严格排序很重要,则在飞行请求中还有其他考虑因素)。
前者是平衡负载的因素——消费者中没有循环,分区只是在每个组中的消费者之间尽可能平均地分配,他们独立投票。如果密钥分布良好,那么每个分区将有大约相同数量的记录。
因此,要实现有效的负载平衡,您唯一的责任就是使用一种良好的策略来创建消息键,并使用您计划扩展到的分区来定义主题。
-
假设我有一个主题T1,它有三个分区,即P1、P2和P3。其中p1是领导者,rest是追随者。
-
我有一个spring boot项目,我是spring-kafka来连接底层的kafka事件枢纽。 我不得不在同一节消费者课上听2个不同的话题。我有两种方法可以这样做。 一个是要有两个这样的Kafka听众: 另一种方法是在同一个kafkaListener中有两个主题,如下所示 ===================edit===============application.yml中的Kafka属性
-
我正在尝试加载一个简单的文本文件,而不是Kafka中的标准输入。下载Kafka后,我执行了以下步骤: 开始动物园管理员: zookeeper-server-start.sh配置zookeeper.properties 已启动服务器 kafka-server-start.sh配置server.properties 创建了一个名为“test”的主题: <code>bin/kafka主题。sh--创建-
-
我已经设置了kafka客户端,它可以产生和消费消息,当我们把有效载荷从生产者发送到主题时,它可以正常工作,所以我有问题生产者现在第一个消息我可以发送到主题,我也可以从kafka主题中消费,现在我尝试发送第二个消息,但是消费者没有从kafka主题中读取第二个消息,知道这里发生了什么吗? Producer.js consumer.js
-
在构建Kafka Streams拓扑时,可以通过两种不同的方式对多个主题的读取进行建模: 读取具有相同源节点的所有主题。 选项1相对于选项2是否有相对优势,反之亦然?所有主题都包含相同类型的数据,并具有相同的数据处理逻辑。
-
我有以下用例:将来自单个数据源的日志文件推送到Kafka主题(例如主题1)。有一个消费者将从中读取并转换为json格式并写回另一个主题(主题2)。另一个期望json中的数据将从主题2读取的消费者将进行一些其他修改并写回另一个主题(主题3)。 我的问题是,除了创建3个不同的主题之外,我能否创建一个主题,并让这些多个制作者写同一个主题?既然不能为生产者设置组id,我的消费者如何知道从哪个分区读取?我从