《万朋数智》专题
-
搜索成千上万文档(pdf和/或xml)的最佳做法
问题内容: 回顾停滞的项目,并在现代化成千上万的“旧”文档并通过网络提供文档方面寻求建议。 文档以各种格式存在,有些已经过时:(。 doc , PageMaker ,硬拷贝(OCR), PDF 等)。有资金可用于将文档迁移为“现代”格式,许多硬拷贝已被OCR转换为PDF-我们原本以为PDF是最终格式,但我们愿意接受建议(XML?) 。 一旦所有文档都采用通用格式,我们便希望 通过Web界面 提供和
-
如何在JdbcTemboard中使用获取大小来处理2000万行?
我有一个包含2000万行的表,由于,我无法使用单个查询选择所有行。我读到了属性,看起来它可能有助于解决我的问题,因为它是常见的建议 但我对如何应用它有疑问。 我有以下代码: 看起来jdbc驱动程序会为每个请求选择1000。但是我应该怎么做才能处理所有2000万行呢? 我应该调用jdbcTemplate吗。查询几次?
-
编写超过5000万从Pyspark df到PostgresSQL,最有效的方法
从Spark数据框到Postgres表格插入数百万条记录的最有效方法是什么?我在过去通过使用批量复制和批量大小选项也成功地从火花到MSSQL做到了这一点。 有没有类似的东西可以在这里为博士后? 添加我尝试过的代码以及运行流程所需的时间: 所以我做了上面的方法,1000万记录,并有5个并行连接,如中指定的,还尝试了200k的批量大小。 整个过程的总时间为0:14:05.760926(14分5秒)。
-
 申万宏源产品经理国际业务部面试复盘
申万宏源产品经理国际业务部面试复盘一面 群面 一小时 三个候选人 三个面试官 ——基础问题 第一部分 个人英文自我介绍 一分钟 第二部分 自我评价(优缺点)及理想工作状态 第三部分 你了解到的产品经理完整的工作流程,详细说一下 ——业务问题 第一部分 如何理解国际业务 第二部分 如何理解前台如销售岗位与中台如产品设计岗位 第三部分 中台部门如何与前台部门合作推广一个产品 第四部分 所在实习券商公司有什么比较优势和不足 第五部分
-
 【留学生找工实录】万兴科技产品一面面经
【留学生找工实录】万兴科技产品一面面经牛客网真的是灵到爆炸,来记录一下春招第一场面试,希望能继续保持面试好运拿到offer!! 一面 - 实习经历介绍 - 项目中充当的角色 - 为什么当时要做这个项目,做这个事情,背景的目的,最终产生的价值 - 复盘的话过程中什么地方可以做到更好 - 和设计开发吵架的时候怎么看待 - 产品经理需要的能力 - 对mentor的期望 - 新接手了一个产品,怎么快速接手业务、上手 #产品##求offer##
-
 北京万集科技 面经 (一面+二面)已oc 开奖了
北京万集科技 面经 (一面+二面)已oc 开奖了9.20收到电话 月薪16k 一年13薪,年终双薪,相当于14薪。有公寓(4人)月租金600 每个月300的食堂补贴 8.26一面 测试工程师 一共两个面试官 首先是自我介绍。然后面试官着重问项目,项目原理和算法,抠得很细,还问了代码是多少行之类的问题; 接着就是问关于测试的知识点,但我研究生不是这方向的所以答得不好 之后就是面试官讲了讲他们部门的构成 感觉凉了一半。。。因为后期面试官也没什么要
-
 万集科技(提前批)-- 算法工程师(苏州研究院)
万集科技(提前批)-- 算法工程师(苏州研究院)7.13 一面 专业问答环节 自我介绍 项目1介绍 数据标注中遇到的问题 团队分工以及具体职责 模型推理速度 基线的选择 训练设备以及部署设备 算法性能提升情况 项目2介绍 项目3介绍 聊天环节 薪资考虑 工作地考虑 读研期间工作时间安排 7.19 HR面 自我介绍 家庭情况 为什么选择XX大学 读研期间科研的整个过程 对象问题 职业规划 为什么选择苏州 为什么选择我们,不考虑一些大厂吗 对未来工
-
用三千万影视剧字幕语料库生成词向量
对语料库切词 因为word2vec的输入需要是切好词的文本文件,但我们的影视剧字幕语料库是回车换行分隔的完整句子,所以我们先对其做切词,有关中文切词的方法请见《教你成为全栈工程师(Full Stack Developer) 三十四-基于python的高效中文文本切词》,为了对影视剧字幕语料库切词,我们来创建word_segment.py文件,内容如下: # coding:utf-8 import
-
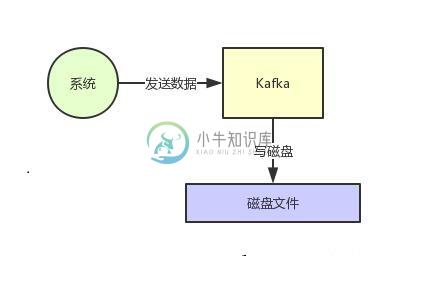 RocketMQ每秒要写入几十万并发,是怎么实现的?
RocketMQ每秒要写入几十万并发,是怎么实现的?主要内容:1、页缓存技术 + 磁盘顺序写,2、零拷贝技术,3、最后的总结这篇文章来聊一下Kafka的一些架构设计原理,这也是互联网公司面试时非常高频的技术考点。 Kafka是高吞吐低延迟的高并发、高性能的消息中间件,在大数据领域有极为广泛的运用。配置良好的Kafka集群甚至可以做到每秒几十万、上百万的超高并发写入。 那么Kafka到底是如何做到这么高的吞吐量和性能的呢?这篇文章我们来一点一点说一下。 1、页缓存技术 + 磁盘顺序写 首先Kafka每次接收到数据都会往磁
-
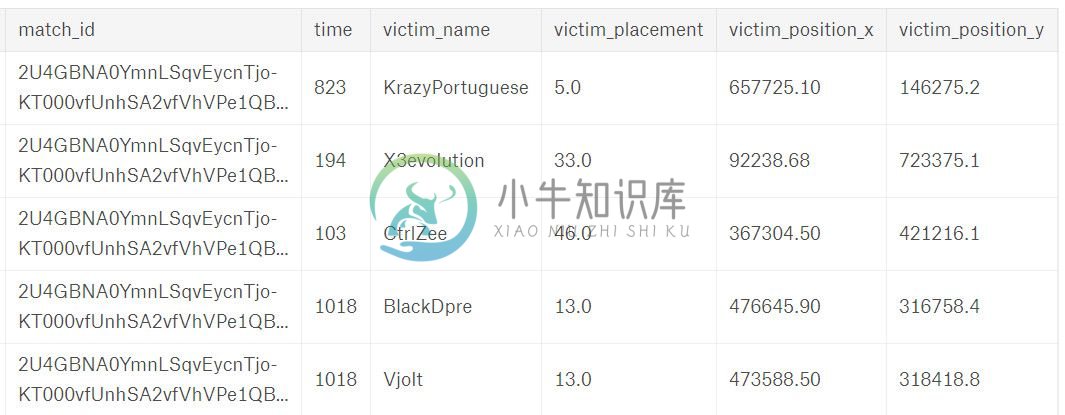 用Python可视化分析绝地求生上万场游戏数据,教你做最强吃鸡攻略啦~
用Python可视化分析绝地求生上万场游戏数据,教你做最强吃鸡攻略啦~导语大吉大利,今晚吃鸡~ 今天跟朋友玩了几把吃鸡,经历了各种死法,还被嘲笑说论女生吃鸡的100种死法,比如被拳头抡死、跳伞落到房顶边缘摔死 、把吃鸡玩成飞车被车技秀死、被队友用燃烧瓶烧死的。这种游戏对我来说就是一个让我明白原来还有这种死法的游戏。但是玩归玩,还是得假装一下我沉迷学习,所以今天就用吃鸡比赛的真实数据来看看如何提高你吃鸡的概率。那么我们就用 Python 和 R 做数据分析来回答以下的灵魂发问?想领取更多完整源码跟Python学习资料可点击这行字体首先来看下数据:.
-
请你说说,在你周围熟悉的同学、朋友眼里,你是怎样的人?
本文向大家介绍请你说说,在你周围熟悉的同学、朋友眼里,你是怎样的人?相关面试题,主要包含被问及请你说说,在你周围熟悉的同学、朋友眼里,你是怎样的人?时的应答技巧和注意事项,需要的朋友参考一下 在他们眼中,性格上我是一个开朗活泼乐观的人,做事上属于办事靠谱的人
-
Twitter API在尝试在twitter上获取用户的朋友时返回401(未经授权)
我正在使用以下代码,该代码在一段时间内像魅力一样工作,但最近在10次尝试中的9次中,我从Twitter api收到错误 Twitter API返回401(未经授权),处理您的请求时发生错误。 这是一个堆栈跟踪 我剩下的1次尝试实际上得到了用户的朋友。 我已经谷歌了一下并纠正了机器上的时间(正如他们所说,这是此错误的最常见原因之一),但错误仍然存在。 也有最小的不工作的例子: 它能够得到ACCESS
-
 UI设计师1分钟学会的大厂面试万能公式
UI设计师1分钟学会的大厂面试万能公式面试必会问到的问题: 请描述一下你的重点项目经历? 我们可根据STAR法则进行以下3个步骤的描述 (S-situation情景、T-task任务、A-action行动、R-结果 ) 句式一: 这是XX背景下的XX项目,我的任务是xx,我通过xx,实现和推动了xxx。 句式二: 目前产品/行业的现状是XXX,业务的目标是XXX,我们因此推导出设计目标是XXX,根据设计目标又可以推导出我的设计策略是X
-
 万集科技苏州研究院算法工程师一面感受
万集科技苏州研究院算法工程师一面感受我是同学介绍了解到万集科技苏州研究院的,7月9号投的简历,7月14号HR就通知我面试,面试时间是下午5点。面试官人非常好,主要问我做了哪些项目,然后问了一些3D点云中常见的算法,同时问了一些在做项目过程遇到的一些困难,整体面试体验非常好。然后我问了HR大哥有没有通过一面,大哥和我说通过一面了。目前在等待二面,希望可以顺利通过二面,拿到offer进入万集科技苏州研究院。
-
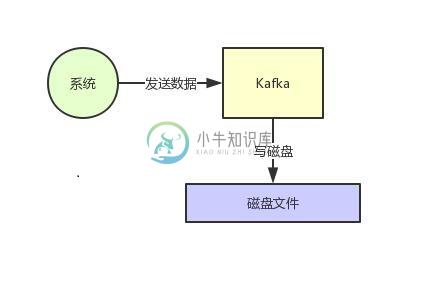 字节面试题: 如何让一个MQ抗住几十万并发?
字节面试题: 如何让一个MQ抗住几十万并发?主要内容:1、页缓存技术 + 磁盘顺序写,2、零拷贝技术,3、最后的总结这篇文章来聊一下Kafka的一些架构设计原理,这也是互联网公司面试时非常高频的技术考点。 Kafka是高吞吐低延迟的高并发、高性能的消息中间件,在大数据领域有极为广泛的运用。配置良好的Kafka集群甚至可以做到每秒几十万、上百万的超高并发写入。 那么Kafka到底是如何做到这么高的吞吐量和性能的呢?这篇文章我们来一点一点说一下。 1、页缓存技术 + 磁盘顺序写 首先Kafka每次接收到数据都会往磁