《万朋数智》专题
-
 万物心选算法实习生面经(一面二面+三面挂)
万物心选算法实习生面经(一面二面+三面挂)万物心选是一个小公司,但是听HR说团队挺牛的,是百度的原创团队成员,二面三面的时候也能感觉到面试官是大佬,但是感觉很怪,前面都聊得挺好的,最后把我挂了,浪费我蛮多时间的。 感觉最开始可能是想要我的,但是后来来了更合适的候选人,就找个理由把我挂掉了。 一面(7.5) 自我介绍 推荐的岗位和其他算法岗(CV,NLP)有啥区别 写个代码(补全训练过程,可以上网查,也可以复制自己的代码) import t
-
MMO如何处理真人游戏的每一刻为成千上万的玩家计算和发送数据包?
问题内容: 我正在开发游戏,正在考虑进入网络。我从事编程工作已有大约5年的时间,最近2年从事游戏开发。我只在自己的时间里真正地在线学习和学习书籍。我正计划为Amazon AWS EC2创建一个Java服务器,但是我只是想知道MMO如何在每个刻度上处理多个玩家。 仅仅是服务器的强大功能吗?我不是在寻找代码或任何东西,只是在一般情况下服务器是如何工作的。 服务器是否只是对所有播放器以及成千上万个对象进
-
从SQLite数据库文件中检索一百万条记录并将其显示在WPF数据网格中的最快方法是什么?
我有一个SQLite3数据库文件,有一百万行和50列(文件大小~200MB)。我想从这个文件加载数据,并将其显示在WPF上。 执行大约需要54秒<代码>SQLiteAdapter。填充(数据集)也需要相同的时间。有没有更快的方法从SQLite数据库获取数据?
-
你来说一下,在微信中,朋友圈功能对于微信的价值是什么?
本文向大家介绍你来说一下,在微信中,朋友圈功能对于微信的价值是什么?相关面试题,主要包含被问及你来说一下,在微信中,朋友圈功能对于微信的价值是什么?时的应答技巧和注意事项,需要的朋友参考一下 1 加速实现微信的商业化诉求。张小龙在微信公开课上提到自朋友圈功能发布至今,每天进入朋友圈的用户数一直在增长,朋友圈的日活用户有7.5亿,平均每个用户每天还会贡献10+次的浏览量,所以朋友圈单日的总量就是10
-
成千上万的图像,我应该如何组织目录结构?(Linux)
问题内容: 我正在由1and1.com托管的Linux服务器上,成千上万的用户上传了数千张图片(我相信他们使用的是CentOS,但不确定该版本)。这是一个与语言无关的问题,但是,供您参考,我正在使用PHP。 我的第一个想法是将它们全部转储到同一目录中,但是,我记得前一阵子,在一个目录中可以放多少个文件或目录是有限制的。 我的第二个想法是根据用户的电子邮件地址对目录内的文件进行分区(因为无论如何,这
-
 万集科技23届秋招前端岗一面二面hr面(已oc)
万集科技23届秋招前端岗一面二面hr面(已oc)公司效率很高,周二投简历,周三约周四面试,周五约下周一二面,一天推进一个流程,好评。 一面30min ——————二面—————— 1.自我介绍 2.为什么选择前端 3.是否用过绘制地图的js——cesium.js 4.数组去重 5.介绍一下原型链 6.js数据类型 7.列举一下es6语法 8.promise、promise.all 9.async/await 和 promise 的区别 10.事
-
使用此功能获得Galaxy Nexus(4.2.1)相机百万像素的问题
我用这个功能获得了百万像素的相机: 在我测试的所有手机中,它的前后摄像头都工作正常,但在Galaxy nexus中。galaxy nexus出问题了,因为我发现相机(正面和背面)有10万像素.... 星系关系和获得百万像素的方式有问题吗? PD:Galaxy Nexus Android版本为4.2.1
-
基于Neo4j的大型图节点度查询(百万节点和链接)
有人在neo4j上用gremlin或Cypher查询这么大的图形吗?
-
《程序员如何挣到一千万》发生变化的五个层次?
“如何挣到一千万?”没有具体的方法论和做法,分享发生这个变化的五个层次
-
请你预测一下,在星期五下午两点半有多少用户在刷朋友圈。
本文向大家介绍请你预测一下,在星期五下午两点半有多少用户在刷朋友圈。相关面试题,主要包含被问及请你预测一下,在星期五下午两点半有多少用户在刷朋友圈。时的应答技巧和注意事项,需要的朋友参考一下 分析思路: 星期五:工作日 下午两点半:工作时间 此时刷朋友圈人数 =微信日活X有刷朋友圈习惯的用户比例X该时刻刷朋友圈的用户比例 假设: 微信日活:10亿 刷朋友圈习惯的用户比例:90% 刷朋友圈的时长在一
-
如何确定百万个数据点中的哪些点(x,y)位于矩形(x1,x2,y1,y2)描述的区域内?
我需要弄清楚如何检查某些点是否位于给定坐标(x1,x2,y1,y2)的矩形内部或外部,即矩形的左上点和右下点。积分总数相当大,约为200万。我知道在这种情况下使用四叉树,但我似乎不知道如何在这里应用它。比如在树中存储什么以及如何查询它。 如果有人能帮助我理解如何有效地解决这个问题,那么这也太好了!
-
 万集科技 应用软件C++一面二面三面 面经(已开奖)
万集科技 应用软件C++一面二面三面 面经(已开奖)因为有激光雷达的相关岗位就果断投了,刚刚发了意向,终于有进京资格了! 一面 35min 全程猛怼项目,所有和雷达相关的项目都要猛问 1、改变根据目标来源动态改变IP地址是什么意思? 2、为什么用UDP不用TCP(你这个TCP才合理啊) 3、怎么处理无线通讯丢帧丢包的 4、多传感器时间同步是怎么做的 5、用工控机处理雷达数据,有没有遇到过性能瓶颈,怎么解决的 6、有没有遇到过coredump,怎么
-
 冲击年薪50万 | 校招后端开发面试真题每日一题
冲击年薪50万 | 校招后端开发面试真题每日一题为什么Java代码可以实现一次编写、到处运行? 参考答案: JVM(Java虚拟机)是Java跨平台的关键。 在程序运行前,Java源代码(.java)需要经过编译器编译成字节码(.class)。在程序运行时,JVM负责将字节码翻译成特定平台下的机器码并运行,也就是说,只要在不同的平台上安装对应的JVM,就可以运行字节码文件。 同一份Java源代码在不同的平台上运行,它不需要做任何的改变,并且只需
-
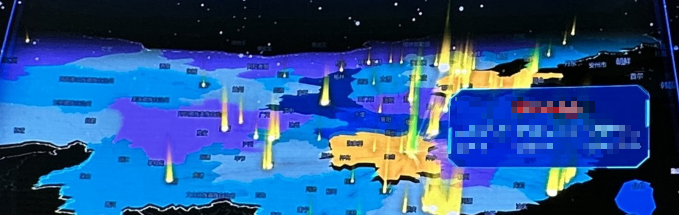 前端 - 请问万能的大佬们,这个地图效果如何实现?
前端 - 请问万能的大佬们,这个地图效果如何实现?这种地图效果是叫什么?具体该使用哪种技术实现,如何实现,有具体的示例吗?
-
MySQL数据库作发布系统的存储,一天五万条以上的增量,预计运维三年,怎么优化?
本文向大家介绍MySQL数据库作发布系统的存储,一天五万条以上的增量,预计运维三年,怎么优化?相关面试题,主要包含被问及MySQL数据库作发布系统的存储,一天五万条以上的增量,预计运维三年,怎么优化?时的应答技巧和注意事项,需要的朋友参考一下 (1)设计良好的数据库结构,允许部分数据冗余,尽量避免join查询,提高效率。 (2) 选择合适的表字段数据类型和存储引擎,适当的添加索引。 (3) 做my