《万朋数智》专题
-
如何选择我或我的朋友在新闻源中创建的帖子?
问题内容: 我已经尝试了很长时间了,然后才发现它是SQL查询,因此我一开始无法使其正常工作。 我正在尝试创建一个类似于Facebook的简单新闻提要页面,您可以在其中看到您在个人资料以及您的朋友个人资料上发布的帖子,还可以看到您的朋友在您的个人资料以及他们自己的个人资料上发表的帖子。 这是一个小提琴:http ://sqlfiddle.com/#!2/ a10f39/1 在此示例中,john123
-
 寻找身高最相近的小朋友 - 华为OD统一考试(D卷)
寻找身高最相近的小朋友 - 华为OD统一考试(D卷)OD统一考试(D卷) 分值: 100分 题解: Java / Python / C++ 题目描述 小明今年升学到小学一年级,来到新班级后发现其他小朋友们身高参差不齐,然后就想基于各小朋友和自己的身高差对他们进行排序,请帮他实现排序。 输入描述 第一行为正整数H和N,0<H<200,为小明的身高,0<N<50,为新班级其他小朋友个数。 第二行为N个正整数H1-HN,分别是其他小朋友的身高,取值范围0
-
 debugging - Ant message.warning 报错,但无影响,有遇到同样情况的朋友吗?
debugging - Ant message.warning 报错,但无影响,有遇到同样情况的朋友吗?ant message.warning 报错: parent 为 null,但似乎并没有什么影响。 想问问有遇到同样情况的吗?如何解决? 我试图简化代码进行复现,以及断点查询,但都失败了。 所以无法提供复现代码。
-
如何批量调整数百万个图像的大小以适合最大宽度和高度?
问题内容: 情况 我正在寻找一种方法来批量调整大小约为1500万个不同文件类型的图像,以适应特定的边框分辨率(在这种情况下,图像不能大于1024 * 1024),而不会扭曲图像,因此保留正确的宽高比。所有文件当前都位于我具有sudo访问权限的Linux服务器上,因此,如果我需要安装任何东西,我很好。 我尝试过的事情 在尝试使用Windows下的某些工具(Adobe Photoshop和其他工具)后
-
—个大数组,可能存了 100万个数字,要从其中取出 来第二大的数的下标,有什么快速的方法?
本文向大家介绍—个大数组,可能存了 100万个数字,要从其中取出 来第二大的数的下标,有什么快速的方法?相关面试题,主要包含被问及—个大数组,可能存了 100万个数字,要从其中取出 来第二大的数的下标,有什么快速的方法?时的应答技巧和注意事项,需要的朋友参考一下 用两个变量max,max2,其中max储存最大值,max2储存第二大值;初始化的时候,将数组中的第一个元素中较大的存进max中,较小的存
-
Java读取具有7000万行文本的大文本文件
问题内容: 我有一个包含7000万行文本的大型测试文件。我必须逐行阅读文件。 我使用了两种不同的方法: 和 是否有另一种方法可以使此任务更快? 最好的祝福, 问题答案: 1)我确定速度没有差异,两者都在内部使用FileInputStream和缓冲 2)您可以进行测量并亲自查看 3)虽然没有性能优势,但我喜欢1.7方法 4)基于扫描仪的版本 5)这可能比其余的更快 它需要一些编码,但是由于,它确实可
-
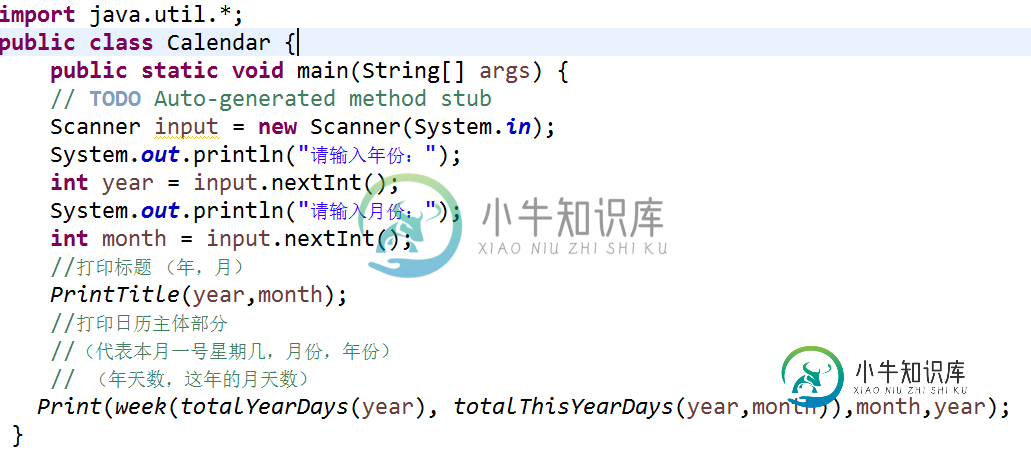 Java基础之打印万年历的简单实现(案例)
Java基础之打印万年历的简单实现(案例)本文向大家介绍Java基础之打印万年历的简单实现(案例),包括了Java基础之打印万年历的简单实现(案例)的使用技巧和注意事项,需要的朋友参考一下 问题:输入年,月,打印对应年月的日历。 示例: 问题分析: 1,首先1970年是Unix系统诞生的时间,1970年成为Unix的元年,1970年1月1号是星期四,现在大多的手机的日历功能只能显示到1970年1月1日这一天; 2,要想打印某年某月的日历,
-
 利用Python绘制有趣的万圣节南瓜怪效果
利用Python绘制有趣的万圣节南瓜怪效果本文向大家介绍利用Python绘制有趣的万圣节南瓜怪效果,包括了利用Python绘制有趣的万圣节南瓜怪效果的使用技巧和注意事项,需要的朋友参考一下 关于万圣节 万圣节又叫诸圣节,在每年的11月1日,是西方的传统节日;而万圣节前夜的10月31日是这个节日最热闹的时刻。在中文里,常常把万圣节前夜(Halloween)讹译为万圣节(All Saints' Day)。 为庆祝万圣节的来临,小孩会装扮成各种
-
 北京万集科技23秋招提前批前端面经
北京万集科技23秋招提前批前端面经水平垂直居中几种方式 vue生命周期 常用的设计模式有哪些 vue常见的指令有哪些 vueRouter的两种模式 ajax同步和异步的区别以及应用场景 数组随机排序 闭包以及闭包的应用和缺点 计算机网络基础 js的继承方式有哪些 讲一讲你如何对项目进行优化 薪资待遇想要多少 #万集科技##前端面经##23届提前批#
-
 2022万纬物流业务开发岗面试经验分享
2022万纬物流业务开发岗面试经验分享本人魔都 985 日语专业,在校期间参加了两份实习,一份世界500 强日企产品经理助理实习生,一份某互联网公司运营实习生。 去年的秋招竞争 十分激烈,想必今年地战况会更加惨烈,在此和大家分享一下我去年参加万纬物流校园招聘的经历。 简历投递 随缘在某招聘app上投的简历,接到了hrbp 的电话沟通,先是核对个人信息和过往的经历,询问了个人的岗位意向,因为前期的实习经验都是关于互联网和软件,H R
-
 万兴科技 桌面开发工程师(C++) 一面/二面
万兴科技 桌面开发工程师(C++) 一面/二面---------9/30 一面---------- 发波面经攒攒人品,希望万子给个机会,让我进入后续流程,想回长沙。 频记忆写的,整体还是比较简单的,聊的也比较轻松,二十五分钟的样子。 简单聊了下项目 项目中问到了TCP/UDP的区别 new delete和malloc和free的区别 vector的实现原理 数组跟链表的区别 快速排序的原理 二分查找的原理 哈希表跟链表的一个关系或者区别(不是
-
 万物心选 | 后端开发实习生 | 一,二,三面(OC)
万物心选 | 后端开发实习生 | 一,二,三面(OC)前言 11月30号Boss投递,12月2日一面,12月5日二面,12月7日三面 一面(12月2日,30min) 自我介绍 实习项目(15min) 简历项目(10min) 反问 二面(12月5日,50min) 自我介绍 实习项目(30min) 场景题(10min) 因为疫情管控,部分地区没法进行发货,然后商家会要求用户会按照省/市/区/详细住址填写无法收货的地址。但是部分用户填写的地址不是很准确或者
-
MyBatis 中 ${}和 #{}的正确使用方法(千万不要乱用)
本文向大家介绍MyBatis 中 ${}和 #{}的正确使用方法(千万不要乱用),包括了MyBatis 中 ${}和 #{}的正确使用方法(千万不要乱用)的使用技巧和注意事项,需要的朋友参考一下 1、#{}是预编译处理,MyBatis在处理#{ }时,它会将sql中的#{ }替换为?,然后调用PreparedStatement的set方法来赋值,传入字符串后,会在值两边加上单引号,如上面的值 “4
-
在10分钟内在Oracle中插入1千万个查询?
问题内容: 我正在研究文件加载器程序。 该程序的目的是获取一个输入文件,对其数据进行一些转换,然后将数据上传到Oracle数据库中。 我面临的问题是我需要优化在Oracle上非常大的输入数据的插入。 我正在将数据上传到表格中,可以说是ABC。 我正在C ++程序中使用Oracle提供的OCI库。具体来说,我使用OCI连接池进行多线程并加载到ORACLE中。(http://docs.oracle.c
-
批处理万年历实现代码(包括农历日期)
本文向大家介绍批处理万年历实现代码(包括农历日期),包括了批处理万年历实现代码(包括农历日期)的使用技巧和注意事项,需要的朋友参考一下 核心源码 以下是各计算部分算法: 计算星期: 基姆拉尔森计算公式 W= (d+2*m+3*(m+1)/5+y+y/4-y/100+y/400) mod 7 在公式中d表示日期中的日数+1,m表示月份数,y表示年数。 注意:在公式中有个与其他公式不同的地方: 把一月