《算法题》专题
-
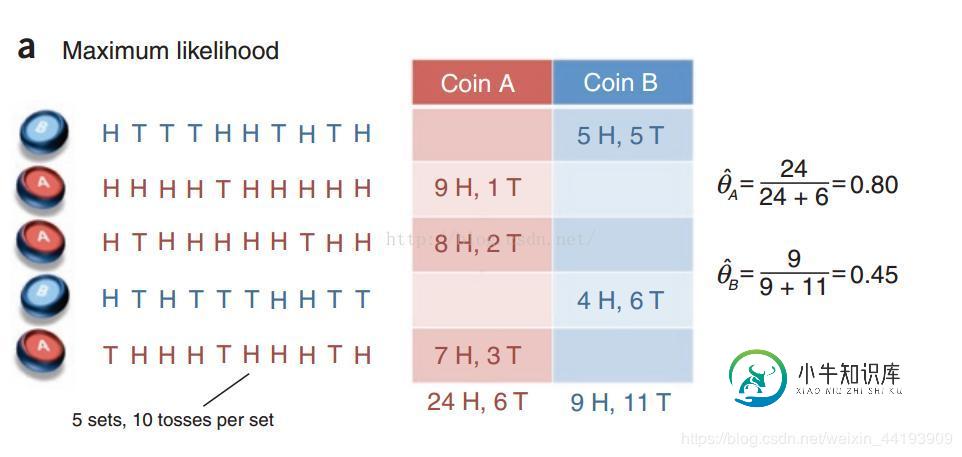 Python实现EM算法实例代码
Python实现EM算法实例代码本文向大家介绍Python实现EM算法实例代码,包括了Python实现EM算法实例代码的使用技巧和注意事项,需要的朋友参考一下 EM算法实例 通过实例可以快速了解EM算法的基本思想,具体推导请点文末链接。图a是让我们预热的,图b是EM算法的实例。 这是一个抛硬币的例子,H表示正面向上,T表示反面向上,参数θ表示正面朝上的概率。硬币有两个,A和B,硬币是有偏的。本次实验总共做了5组,每组随机选一个硬
-
Android图片缓存之Lru算法(二)
本文向大家介绍Android图片缓存之Lru算法(二),包括了Android图片缓存之Lru算法(二)的使用技巧和注意事项,需要的朋友参考一下 前言: 上篇我们总结了Bitmap的处理,同时对比了各种处理的效率以及对内存占用大小,点击查看。我们得知一个应用如果使用大量图片就会导致OOM(out of memory),那该如何处理才能近可能的降低oom发生的概率呢?之前我们一直在使用SoftRefe
-
 PHP实现的回溯算法示例
PHP实现的回溯算法示例本文向大家介绍PHP实现的回溯算法示例,包括了PHP实现的回溯算法示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP实现的回溯算法。分享给大家供大家参考,具体如下: 问题: 一头大牛驼2袋大米,一头中牛驼一袋大米,两头小牛驼一袋大米,请问100袋大米需要多少头大牛,多少头中牛,多少头小牛? 实现代码: 运行结果如下图: 更多关于PHP相关内容感兴趣的读者可查看本站专题:《PHP数
-
用Kruskal算法求图的最小割?
我们已经看到,树的生成和切割是密切相关的。这里有另一个联系。让我们移除Kruskal算法添加到生成树中的最后一条边;这将树分解为两个组件,从而在图中定义一个截(S,S)。我们对这个伤口能说什么呢?假设我们正在处理的图是未加权的,并且它的边是均匀随机排列的,以便Kruskal的算法处理它们。这里有一个值得注意的事实:在概率至少1/n^2的情况下,(S,S)是图中的最小割,其中割的大小(S,S)是S和
-
内置sagemaker算法的增量学习
我正在训练DeepAR AWS SageMaker的内置算法。使用sagemaker SDK,我可以使用特定的超参数训练模型: 我想以较小的学习率再次训练生成的模型。我遵循此处描述的增量培训方法:https://docs.aws.amazon.com/en_pv/sagemaker/latest/dg/incremental-training.html,但它不起作用,显然(根据链接),只有两个内置
-
谈谈锁机制与InnoDB锁算法?
本文向大家介绍谈谈锁机制与InnoDB锁算法?相关面试题,主要包含被问及谈谈锁机制与InnoDB锁算法?时的应答技巧和注意事项,需要的朋友参考一下 MyISAM和InnoDB存储引擎使用的锁: MyISAM采用表级锁(table-level locking)。 InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁 表级锁和行级锁对比: 表级锁: MySQL中锁定 粒度
-
PHP实现的贪婪算法实例
本文向大家介绍PHP实现的贪婪算法实例,包括了PHP实现的贪婪算法实例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP实现的贪婪算法。分享给大家供大家参考,具体如下: 背景介绍:贪婪算法与数据结构知识库算法可以说是离我们生活最近的一种算法,人总是贪婪的嘛,所以这种算法的设计是很符合人性的。之所以这么说,是因为人们会在生活中有意无意的使用贪婪算法来解决问题。最常见的就是找零钱了,每个人
-
Java扑克牌速算24的方法
本文向大家介绍Java扑克牌速算24的方法,包括了Java扑克牌速算24的方法的使用技巧和注意事项,需要的朋友参考一下 已知一副扑克牌有54张,去除大王和小王,剩余52张。在其中随机抽取4张牌,利用加减乘除进行计算得到24. 从A到10,他们的值分别为1到10. 从J到K,他们对应的值是减去10以后的值。编写程序生成一副扑克牌,随机抽取4张,进行计算是否能得到24. 如果可以,列出可能的计算表达式
-
SQL高效的计划生成算法
问题内容: 想象一下设有 分支机构的 教育中心。该教育中心的 课程 对所有分支机构都是通用的。 分行 *管理员生成的每个课程的每个分支中的 *房间 。例如,管理员输入数学课程的房间数。系统生成3个房间。换句话说,它们受到计数的限制。 每个房间每天有5个可用的教学时间。换句话说,每个教学小时(共5个)将有1个不同的学生组。 学生 -也按分支分组。每个学生都喜欢按周计划()上中学。 一周的1、3、5天
-
结合无损数据压缩算法
我想知道我们可以在多大程度上进行无损数据压缩;我无法找到一个无损算法的在线模拟器来执行一些经验测试。我可以自己做一个,但不幸的是,我在这段时间没有足够的时间;我仍然对我的直觉感到好奇,我将解释一下。 让我们只看两种更流行的算法:
-
antlr4语法中“~”运算符的意义
我正在努力理解语法文件:https://github.com/antlr/grammars-v4/blob/master/url/url.g4 我无法理解运算符在最后的Character集合中:我知道代表不在集合运算符中,如:https://github.com/antlr/antlr4/blob/master/doc/lexer-rules.md即是匹配任何单个字符不在描述的集合中,但如何解释当
-
C DFS中的迷宫回溯算法?
我是C的新手,我目前正在一个项目中创建一个使用DFS算法生成的迷宫。 我已经成功地生成了一条路径,例如 如上所述, Source是初始单元,1是我根据随机邻居创建的路径,D是“死胡同”。所以,如果可能的话,我想回到S,从另一个方向开始。我该如何处理队列和堆栈?有人能解释一下吗?非常感谢你?
-
浮点运算中尾数的乘法
关于尾数(关于浮点运算的指南),实际上如何将两个尾数相乘? 假设IEEE 754单精度浮点表示。 假设一个数字的尾数为,将被编码为(十进制为)。第二个数字的尾数为,将被编码为(十进制为)。 <代码>1.5 x 1.125=1.6875。 编码为(十进制为)。但是不等于... 尾数乘法是如何工作的,以至于将4194304(1.5)乘以1048576(1.125),得到5767168(1.6875)?
-
c#数学运算的一般方法
我想创建一个执行基本数学运算的通用方法。例如,如果将double传递给函数,它将返回double。 这对我不起作用。 编辑:我得到一个错误运算符“*”不能应用于“T”和“int”类型的操作数 然而,我想知道是否有其他方法来实现我正在努力的目标? 谢啦
-
哈夫曼树算法理解困难
我在基于频率表的哈夫曼树上工作。频率表是通过计算给定字符串中字符的频率并将相应项(字符和频率)放置在链接列表中生成的。然后,我需要将项目按频率顺序放置在哈夫曼树中。我得到了它背后的逻辑是确保每个子树都有右节点和左节点,添加它们的频率,用它们添加的频率创建一个根节点,将下一个频率分别放在左树和右树中,并重复这个过程,直到没有更多的频率,子树与添加其频率的根连接;我遇到的问题是如何实现代码。 代码相当