《算法题》专题
-
基于ELO的团队匹配算法
我正在寻找一种非常简单的方法,用未知(但已知)数量的球员组建2支球队。因此,这实际上不是一个标准的配对,因为它只为特定的比赛在整个注册球员池中创建一场比赛。我几乎只有一个变量,它是每个球员的ELO分数,这意味着它是唯一可以用来计算的选项。 我想到的只是简单地检查每一个可能的球员组合(每队6名),球队平均ELO之间的最小差异是最终创建的名册。我已经测试过这个选项,它为18名注册玩家提供了超过1700
-
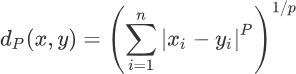 K-means聚类算法原理解析
K-means聚类算法原理解析主要内容:度量最小距离,总结通过《 什么是Kmeans聚类算法》一节的学习,我们了解了 K-means 聚类算法的聚类过程,其实就是不断寻找簇的质心的过程,该过程从随机设定 K 个质心开始,直到找到 K 个最合适的质心为止。本节我们透过算法流程直击算法的本质,帮助您彻底理解 K-means 算法。 度量最小距离 对于 K-means 聚类算法而言,找到质心是一项既核心又重要的任务,找到质心才可以划分出距离质心最近样本点。从数
-
 SVM分类算法应用及实现
SVM分类算法应用及实现主要内容:Sklearn库SVM算法,SVM算法应用SVM 是一种有监督学习分类算法,输入值为样本特征值向量和其对应的类别标签,输出具有预测分类功能的模型,当给该模型喂入特征值时,该模型可以它对应的类别标签,从而实现分类。 Sklearn库SVM算法 下面我看一下 Python 的 Scikit -Learn(简称 Sklearn) 库是如何实现 SVM 算法的。 支持向量机算法被包含在 sklearn.svm 模块中,该模块提供了 7 个常用类,
-
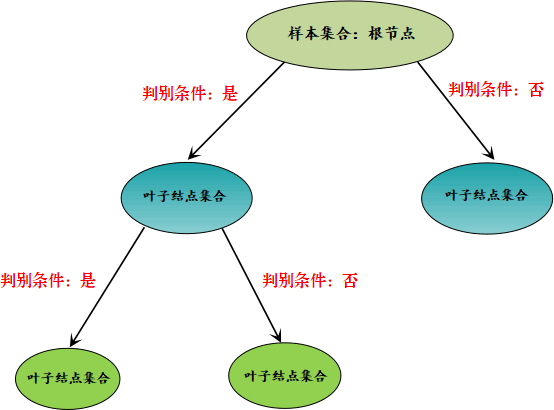 决策树算法和剪枝原理
决策树算法和剪枝原理主要内容:决策树算法原理,决策树剪枝策略本节我们对决策算法原理做简单的解析,帮助您理清算法思路,温故而知新。 我们知道,决策树算法是一种树形分类结构,要通过这棵树实现样本分类,就要根据 if -else 原理设置判别条件。因此您可以这样理解,决策树是由许多 if -else 分枝组合而成的树形模型。 决策树算法原理 决策树特征属性是 if -else 判别条件的关键所在,我们可以把这些特征属性看成一个 集合,我们要选择的判别条件都来自于
-
 二分查找(折半查找)算法
二分查找(折半查找)算法主要内容:折半查找算法,折半查找的性能分析,总结折半查找,也称 二分查找,在某些情况下相比于顺序查找,使用折半查找算法的效率更高。 但是该算法的使用的前提是静态查找表中的数据必须是有序的。 例如,在 这个查找表使用折半查找算法查找数据之前,需要首先对该表中的数据按照所查的关键字进行排序: 。 在折半查找之前对查找表按照所查的关键字进行排序的意思是:若查找表中存储的数据元素含有多个关键字时,使用哪种关键字做折半查找,就需要提前以该关键字对所有数据
-
A*搜索算法启发式函数
我正在尝试使用 A* 算法找到任何长度的滑动块拼图的最佳解决方案。 滑动积木拼图是一种游戏,白色(W)和黑色(B)的瓷砖排列在一个线性游戏板上,有一个单一的空白空间(-)。给定棋盘的初始状态,游戏的目的是将瓷砖排列成目标模式。 例如,我目前在董事会上的状态是BBW-WWB,我必须达到BBB-WWW状态。瓷砖可以通过以下方式移动:1.滑入相邻的空白空间,成本为1。2. 跳过另一个瓷砖进入空白区域,费
-
最小优先级队列Dijkstra算法
我的问题是:每个节点的优先级是什么?我认为它是最小值的传入边缘的权重,但我不确定。这是真的吗? 第二个问题,当我提取队列的根时,如果这个节点不与任何一个被访问的节点邻接,它将如何工作?
-
指纹匹配/识别算法/实现
问题内容: 整整一整天,我一直在编程领域投入时间来进行指纹匹配/识别算法/实现。尽管有点模糊,因为我似乎找不到任何真正相关的东西。 我基本上是在寻找两件事: 指纹识别:验证图像实际上是一个指纹,因此可以与另一个指纹匹配 指纹匹配:从项目中匹配两个指纹以查看实际是否相等 所有操作都将在图像上完成,因此我与硬件无关。我发现了一些东西,例如Java Fingerprint SDK等,并且在Stackov
-
Jenkins中的算法协商失败SSH
问题内容: 我正在尝试从Jenkins SSH到本地服务器,但抛出以下错误: SSH服务器上Java的安装版本: 客户端上的Java安装版本: 还尝试了以下解决方案: JSchException:算法协商失败, 但是不起作用。从油灰看来,一切正常。建立了连接,但是当我触发Jenkins作业时,将引发错误。我应该尝试其他版本的ssh服务器。现在我正在使用copssh。 问题答案: TL; DR编辑您
-
 阳光电源算法测试面经
阳光电源算法测试面经一面: 两个面试官 开发和测试的区别,以及你为啥想测试 聊项目和实习 讲讲等价类和边界值 都了解什么算法 了解粒子群算法吗?(啊啊啊俺忘了呜呜) 大概这些吧 许愿二面,想去阳光电源呜呜 9.26收到测评,立马就做完了,超希望能收到offer的! 更新,国庆节前已谈薪,在权衡去不去 #阳光电源#
-
第一章:数据结构和算法
Python 提供了大量的内置数据结构,包括列表,集合以及字典。大多数情况下使用这些数据结构是很简单的。 但是,我们也会经常碰到到诸如查询,排序和过滤等等这些普遍存在的问题。 因此,这一章的目的就是讨论这些比较常见的问题和算法。 另外,我们也会给出在集合模块 collections 当中操作这些数据结构的方法。 1.1 解压序列赋值给多个变量 1.2 解压可迭代对象赋值给多个变量 1.3 保留最后
-
基本排序算法 - 快速排序
JavaScript算法-快速排序 快速排序是处理大数据集最快的排序算法之一。它是一种分而治之的算法,通过递归的方式将数据依次分解为包含较小元素和较大元素的不同子序列。该算法不断重复这个步骤直到所有数据都是有序的。 这个算法首先要在列表中选择一个元素作为基准值(pivot)。数据排序围绕基准值进行,将列表中小于基准值的元素移到数组的底部,将大于基准值的元素移到数组的顶部。 快速排序的算法和伪代码
-
基本排序算法 - 归并排序
归并排序 归并排序是建立在归并操作上的一种有效的排序算法。该算法是分治法的一个非常典型的应用。归并排是一种稳定的排序方法。将已有序列的子序列合并 .把长度为n的输入序列分成两个长度为n/2的子序列; .对这两个子序列分别采用归并排序; .将两个排序好的子序列合并成一个最终的排序序列。 function mergeSort(arr) { //采用自上而下的递归方法 var len = ar
-
基本排序算法 - 希尔排序
希尔排序 这个算法在插入排序的基础上作出了很大的改善。希尔排序的核心理念与插入排序不同,它会首先比较距离较远的元素,而非相邻的元素。和简单的比较相邻元素相比,使用这种方案可以使离正确位置很远的元素更快回到适合的位置。当开始用这个算法遍历数据集时,所有元素之间的距离会不断减小,直到处理到数据集的末尾,这时算法比较的就是相邻元素了。 主要是通过遍历数组中相隔相同位置的元素去比较大小进行排列 funct
-
基本排序算法 - 插入排序
JavaScript算法-插入排序 插入排序 插入排序有两个循环,外循环将数组元素挨个移动,而内循环则对外循环中选中的元素及它后面的那个元素进行比较。如果外循环中选中的元素比内循环中选中的元素小,那幺数组会向右移动,为内循环中的这个元素腾出位置。 function insertionSort() { var temp,inner; for (var outer = 1; outer <=