《算法题》专题
-
带厚度绘制算法的圆
目前我正在使用Bresenham的圆圈绘制算法,它可以精细地绘制圆圈,但是我想要一种相对快速有效的方法来绘制具有指定厚度的圆圈(因为Bresenham的方法只绘制单个像素厚度)。我意识到我可以简单地绘制多个具有不同半径的圆圈,但我相信这将是非常低效的(并且效率很重要,因为这将在每微秒都很宝贵的Arduino上运行)。我目前使用以下代码: 我如何修改它以允许指定圆的厚度?PS我不想使用任何外部库,请
-
“中位数”算法的Python实现
我已经用python编写了medians算法的median的实现,但是它似乎没有输出正确的结果,而且对我来说它似乎也没有线性复杂度,知道我哪里出错了吗? 这个函数是这样调用的: 乐:不好意思。GetMed是一个简单地对列表排序并返回len(list)处的元素的函数,它应该在那里被选择,我现在修复了它,但我仍然得到错误的输出。至于缩进,代码工作没有错误,我看不出有什么问题:-?? LE2:我期望50
-
Java与Javascript兼容的AES算法
我需要使用AES算法加密Java应用程序中的一些值,并在我的应用程序的Javascript模块中解密相同的值。 我在互联网上看到了一些例子,但在兼容性方面似乎有些不同。 多谢了。
-
Prim算法在Java中的实现
我试图在Java中实现Prim的算法,用于我的图形HashMap LinkedList和一个包含连接顶点和权重的类Edge: 我的想法是,从一个给定的顶点开始:1)将所有顶点保存到一个LinkedList中,这样每次访问它们时我都可以删除它们2)将路径保存到另一个LinkedList中,这样我就可以得到我的最终MST 3)使用PriorityQueue找到最小权重 最后我需要MST,边数和总重量。
-
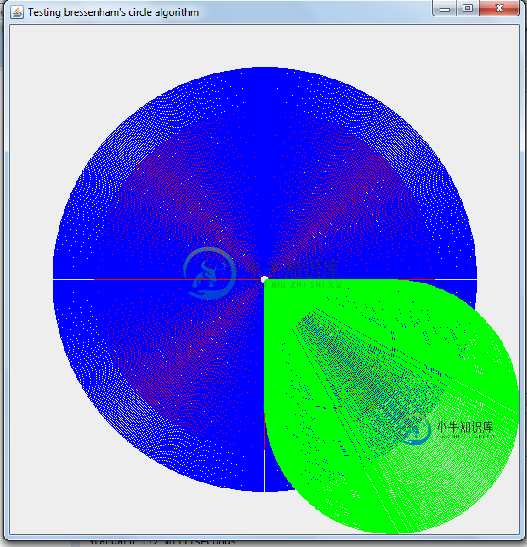 Bresenham圆绘制算法的实现
Bresenham圆绘制算法的实现我已经写了一个Bresenham的圆绘制算法的实现。该算法利用了圆的高度对称特性(它只计算第一个八分之一的点,并利用对称性绘制其他点)。因此,我希望它会非常快。《图形编程黑皮书》第35章的标题是“Bresenham是快的,而且快是好的”,虽然它是关于线条绘制算法的,但我可以合理地预期圆形绘制算法也很快(因为原理是一样的)。 这是我的java,摇摆实现 此方法使用以下方法: getNativeX和g
-
合并排序算法不工作
我正在尝试实现一个不能正常工作的mergesort算法。合并排序的工作方式如下: i、 将未排序的列表划分为n个子列表,每个子列表包含1个元素(1个元素的列表被视为已排序)。 ii.重复合并子列表以产生新排序的子列表,直到只剩下1个子列表。这将是已排序的列表。下面提供了实现。 最初,递归调用此方法,直到只有一个元素。 这是提供的合并方法。 这里的问题是什么? 输入是输出是
-
Ford-Fulkerson算法的一种改进
假设我们重新定义剩余网络,不允许边进入。认为福特-富尔克森的程序仍然正确地计算了最大流量。 我在想,当我们增加一条路径时,反向边缘的剩余容量会增加,如果需要,可以用来减少该边缘的流量(但总体上增加网络流量)。因此,如果我们不允许边进入,这意味着我们不允许边中的流减少(是的相邻节点)。因此,当我们允许边进入时,我们可以有一个类似的循环 但是如果我们再次禁止边进入,我们可以在没有循环的情况下找到相同的
-
Kafka消费者再平衡算法
有人能告诉我Kafka消费者的再平衡算法是什么吗?我想了解分区计数和消费者线程是如何影响这一点的。 非常感谢。
-
三元运算符语法(Java)[闭]
以下是关于的几个主题: 三元算子-Java 除此之外,我不懂语法。 我有一个带有和的方法。 三元运算符的语法为 我试过这个: 我有一个错误消息=>
-
mandelbrot集的光滑着色算法
我知道关于这件事,阿雷迪回答了很多问题。然而,我的略有不同。无论何时我们实现平滑着色算法,我都理解它。 其中n是逃逸迭代,2是z的幂,如果我没有弄错,z是该逃逸迭代处复数的模。然后,我们在颜色之间的线性插值中使用这个重整化的逃逸值来生成平滑的带状mandelbrot集。我已经看到了关于这个的其他问题的答案,我们通过HSB到RGB的转换来运行这个值,但是我仍然无法理解这将如何提供平滑的颜色渐变,以及
-
加权有向图的Prim算法
我正在学习最小生成树。我研究了Prim的加权有向图算法。 算法简单 您有两组顶点:已访问和未访问 将所有边的距离设置为无穷远 从未访问集合中的任意顶点开始并探索其边 在所有边中,如果目标顶点没有被访问,并且如果边的权重小于目标顶点的距离,则用该边的权重更新目标顶点的距离 选择距离最小的未访问顶点,然后再进行一次,直到所有顶点都访问完 相信通过以上算法,能够在所有的生成树中找到代价最小的生成树,即最
-
 并行压缩收集器算法
并行压缩收集器算法我有两个问题。其中一个会把话题弄得乱七八糟:) 1)我遇到了一个问题,即无法找到关于不同垃圾收集器在Hotspot中如何工作的完整信息。但我不是在谈论垃圾收集器工作的一般描述(我们在互联网上有很多这样的信息),我是在谈论具体的算法。我找到了这本白皮书(Java HotSpot虚拟机中的内存管理)http://www.oracle.com/technetwork/Java/javase/tech/m
-
就地排序堆栈的算法
哪种排序算法适合对堆栈进行排序以提高空间效率?我需要对堆栈进行“就地”排序。此外,我对“就地”算法的理解是它们不使用任何其他数据结构 - 这是正确的吗? 我知道这与这个问题相似,但我想知道堆栈是否会有所不同?我知道堆栈可以只是一种链接列表,但是你只能访问顶部的事实会改变你的做法吗?
-
插入排序算法的改进
如果使用双向链表代替数组,是否有可能提高插入排序算法的运行时间? 非常感谢。
-
最大流量算法的改进
我试着解决一个关于最大流量问题的问题。我有一个源和两个汇。我需要在这个网络中找到一个最大流量。这部分是一般最大流量。然而,在这种特殊的最大流问题中,两个目标必须得到相同的流量。 有没有人能帮助我,我该怎么做呢?