《算法题》专题
-
boost最短路径查找算法
你好,亲爱的朋友们。 我想在随机图中找到最短路径。我使用boost图形库。据我所知,我需要利用点之间的现有距离构建图形。之后,我需要使用一些算法。。。 正如我所见,Dijkstra的算法实际上是找到从1点到其他点的所有路径。(应该很慢?) A*需要一些额外的数据(不仅仅是距离) 如何找到2点之间的最短路径?我在bgl文件夹中看到了许多最短路径算法标头,但我没有找到如何使用它们的示例。 此外,我可以
-
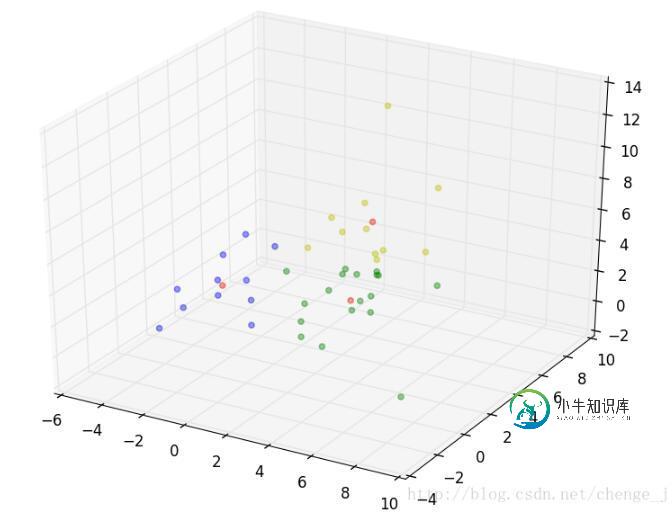 python实现k-means聚类算法
python实现k-means聚类算法本文向大家介绍python实现k-means聚类算法,包括了python实现k-means聚类算法的使用技巧和注意事项,需要的朋友参考一下 k-means聚类算法 k-means是发现给定数据集的k个簇的算法,也就是将数据集聚合为k类的算法。 算法过程如下: 1)从N个文档随机选取K个文档作为质心 2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类,我们一般取欧几里得距离 3)重
-
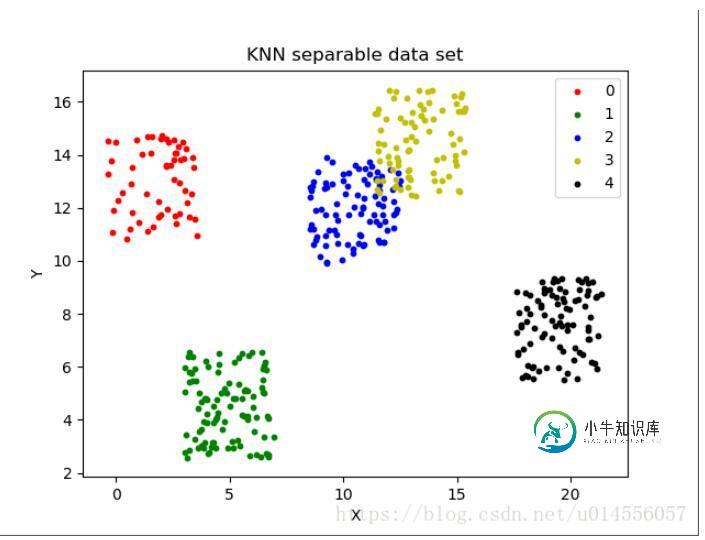 python可视化实现KNN算法
python可视化实现KNN算法本文向大家介绍python可视化实现KNN算法,包括了python可视化实现KNN算法的使用技巧和注意事项,需要的朋友参考一下 简介 这里通过python的绘图工具Matplotlib包可视化实现机器学习中的KNN算法。 需要提前安装python的Numpy和Matplotlib包。 KNN–最近邻分类算法,算法逻辑比较简单,思路如下: 1.设一待分类数据iData,先计算其到已标记数据集中每个数
-
python的sorted()使用什么算法?
问题内容: 我试图向某人解释为什么他们应该使用Python的内置sorted()函数而不是滚动自己的函数,但我意识到我不知道它使用什么算法。 如果重要的话,我们说的是python 2.7 问题答案: Python使用一种称为Timsort的算法: Timsort是一种混合排序算法,是从合并排序和插入排序派生而来的,旨在对多种现实数据表现良好。它是由Tim Peters在2002年发明的,用于Pyt
-
python计算时间差的方法
本文向大家介绍python计算时间差的方法,包括了python计算时间差的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python计算时间差的方法。分享给大家供大家参考。具体分析如下: 1、问题: 给定你两个日期,如何计算这两个日期之间间隔几天,几个星期,几个月,几年? 2、解决方法: 标准模块datetime和第三方包dateutil(特别是dateutil的rrule.coun
-
有效的区间分组算法
我需要找到一种算法来解决以下问题: 给出了一个区间列表(leftBound、RightBound),这是在此行为中对区间进行分组的最有效算法: 间隔:(1,4)、(6,9)、(1,3)、(4,8)、(6,9)、(2,7)、(10,15) 需要的解决方案: 组(2,3)包含(1,3), (1,4), (2,7) 组(6,8)包含(4,8), (6,9) 组(10,15)包含(10,15) 当然,有不
-
照片/图像到草图算法
问题内容: 是否有人对如何将照片和图像(位图)转换为类似草图的图片有想法,链接,库,源代码…?我找不到任何好的方法来做这件事。 我找到了此链接。如何以编程方式对图像进行卡通化?关于如何以编程方式对图像进行卡通化,但我更喜欢将其图像化为草图。 我想制作一个可以以编程方式将JPEG照片“转换”为粗略图像的android应用。 问题答案: 好的,所以我使用马克告诉我的不同技术找到了自己的答案。我使用以下
-
请你说一说洗牌算法?
本文向大家介绍请你说一说洗牌算法?相关面试题,主要包含被问及请你说一说洗牌算法?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 考察点: 公司:腾讯 1、Fisher-Yates Shuffle算法 最早提出这个洗牌方法的是 Ronald A. Fisher 和 Frank Yates,即 Fisher–Yates Shuffle,其基本思想就是从原始数组中随机取一个之前没取过的数字到新的
-
 请问有哪些排序算法
请问有哪些排序算法本文向大家介绍请问有哪些排序算法相关面试题,主要包含被问及请问有哪些排序算法时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 冒泡排序 是最简单的排序之一了,其大体思想就是通过与相邻元素的比较和交换来把小的数交换到最前面。这个过程类似于水泡向上升一样,因此而得名。举个栗子,对5,3,8,6,4这个无序序列进行冒泡排序。首先从后向前冒泡,4和6比较,把4交换到前面,序列变成5,3,8,4,6。
-
如何正确使用“ PBEWithHmacSHA512AndAES_256”算法?
问题内容: 我正在做一些Java加密,无法找到正确使用PBEWithHmacSHA512AndAES_256算法的方法。 加密似乎可以正常工作,但是我无法正确初始化解密密码。 下面是演示该问题的简短程序。特别是,请参见“问题”注释。 注意:我已经看到了这个非常有用的答案,并且可以使用该方案使事情正常进行,但是我很想知道我在这里做错了什么。 问题答案: // PROBLEM: If I pass “
-
Python算法之栈(stack)的实现
本文向大家介绍Python算法之栈(stack)的实现,包括了Python算法之栈(stack)的实现的使用技巧和注意事项,需要的朋友参考一下 本文以实例形式展示了Python算法中栈(stack)的实现,对于学习数据结构域算法有一定的参考借鉴价值。具体内容如下: 1.栈stack通常的操作: Stack() 建立一个空的栈对象 push() 把一个元素添加到栈的最顶层 pop() 删除栈最顶层的
-
Java数组奇数排序算法
我得到了一个算法,可以用一种特定的方式写出欠费的顺序。 找到数组的最低数 将其保存在新数组的开头。 标记在我们找到最低数字的起源(起始)数组点(例如将其标记为最大int数字)。 回到第1点。 重复all以按升序重写所有数字。 所以我得到了一个可以改变顺序的工作代码,但我不知道如何标记数字,多亏了这一点,我创建了一个新的数组。
-
 地形网格法线的计算
地形网格法线的计算我试图优化我的地形,减少三角形计数,同时保持尽可能多的细节。减少工作很好,我削减了五分之一顶点的数量没有太多的视觉损失。在这个新的非对称网格上法线的计算有一个问题。 每个顶点都有法线,下面是计算法线的片段: 其中三角形是与顶点(点)相连的三角形。我把所有的三角形法线加在一起(不进行归一化以使最终的向量以三角形面积加权),然后最后对最终结果进行归一化。 我相信计算是正确的,但结果中有一些讨厌的伪影(
-
有“完美”压缩的算法吗?
让我澄清一下,我不是在说完美压缩,也不是说一种能够压缩任何给定源材料的算法,我意识到这是不可能的。我试图得到的是一种算法,它能够将任何源比特串编码到它的绝对最大压缩状态,这取决于它的香农熵。 我相信我听说过一些关于霍夫曼编码在某种意义上是最优的事情,所以我相信这个加密方案可能是基于此的,但这是我的问题: 考虑位串:a="101010101010",b="110100011010"。 使用纯香农熵,
-
HyperLogLog算法是如何工作的?
我最近在业余时间学习了不同的算法,我遇到的一个看起来非常有趣的算法叫做超级日志算法——它估计一个列表中有多少独特的项目。 这对我来说特别有趣,因为它让我回到了我的MySQL时代,那时我看到了“基数”值(直到最近我一直认为它是计算出来的,不是估计出来的)。 所以我知道如何用O(n)编写一个算法,计算数组中有多少个唯一项。我是用JavaScript写的: 但问题是,我的算法虽然是O(n),但使用了大量