《十进制》专题
-
十九、自动特征选择
我们经常收集许多可能与监督预测任务相关的特征,但我们不知道它们中的哪一个实际上是预测性的。 为了提高可解释性,有时还提高泛化表现,我们可以使用自动特征选择来选择原始特征的子集。 有几种可用的特征选择方法,我们将按照复杂性的升序来解释。 对于给定的监督模型,最佳特征选择策略是尝试每个可能的特征子集,并使用该子集评估泛化表现。 但是,特征子集是指数级,因此这种详尽的搜索通常是不可行的。 下面讨论的策略
-
十七、深入:线性模型
线性模型在可用的数据很少时非常有用,或者对于文本分类中的非常大的特征空间很有用。 此外,它们是正则化的良好研究案例。 用于回归的线性模型 用于回归的所有线性模型学习系数参数coef_和偏移intercept_,来使用线性特征组合做出预测: y_pred = x_test[0] * coef_[0] + ... + x_test[n_features-1] * coef_[n_features-1]
-
十五、估计器流水线
在本节中,我们将研究如何链接不同的估计器。 简单示例:估计器之前的特征提取和选择 特征提取:向量化器 对于某些类型的数据,例如文本数据,必须应用特征提取步骤将其转换为数值特征。 为了说明,我们加载我们之前使用的 SMS 垃圾邮件数据集。 import os with open(os.path.join("datasets", "smsspam", "SMSSpamCollection")) as
-
十一、文本特征提取
在许多任务中,例如在经典的垃圾邮件检测中,你的输入数据是文本。 长度变化的自由文本与我们需要使用 scikit-learn 来做机器学习所需的,长度固定的数值表示相差甚远。 但是,有一种简单有效的方法,使用所谓的词袋模型将文本数据转换为数字表示,该模型提供了与 scikit-learn 中的机器学习算法兼容的数据结构。 假设数据集中的每个样本都表示为一个字符串,可以只是句子,电子邮件或整篇新闻文章
-
确定四舍五入为n个有效十进制数字时两个数字是否几乎相等的函数
问题内容: 我被要求测试第三方提供的图书馆。该库已知可精确到 n个 有效数字。任何不太重要的错误都可以安全地忽略。我想编写一个函数来帮助我比较结果: 此函数的目的是确定两个浮点数(a和b)是否近似相等。如果a == b(完全匹配),或者当a和b具有十进制值的 sigfig 有效数字舍 入时, 该函数将返回True 。 有人可以建议一个好的实施方案吗?我写了一个迷你单元测试。除非您在测试中看到错误,
-
浮点文字中有效十进制数字的最小数量是多少,以尽可能正确地表示值?
例如,使用 IEEE-754 32 位二进制浮点数,让我们表示 。它不能完全完成,但产生最接近的值。您可能希望以十进制写入值,并让编译器将十进制文本转换为二进制浮点数。 您可以看到,8 个(有效)十进制数字足以表示尽可能正确的值(最接近实际值)。 我用π和e(自然对数的基础)进行了测试,两者都需要8位小数才能正确测试。 但是,似乎需要9位数字。 https://godbolt.org/z/W5vE
-
进行递归二进制搜索
问题内容: 我知道Go有一个包含搜索功能的程序包,但这是出于教育目的。我一直在尝试在Go中实现二进制搜索算法,但无法使其正常工作。 这是我的代码: 它总是打印。为什么? 问题答案: 二进制搜索的逻辑是合理的。唯一的问题是您忘记了将每个递归调用的结果分配给和。 当前,您有以下这些递归调用: 您只需要分配结果:
-
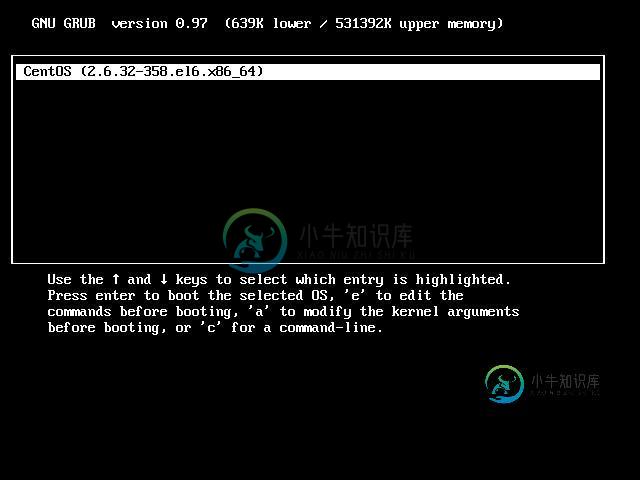 Linux学习之CentOS(二十二)--进入单用户模式下修改Root用户的密码
Linux学习之CentOS(二十二)--进入单用户模式下修改Root用户的密码本文向大家介绍Linux学习之CentOS(二十二)--进入单用户模式下修改Root用户的密码,包括了Linux学习之CentOS(二十二)--进入单用户模式下修改Root用户的密码的使用技巧和注意事项,需要的朋友参考一下 在上一篇随笔里面详细讲解了Linux系统的启动过程、,我们知道Linux系统的启动级别一共有6种级别,通过 /etc/inittab 这个文件我们就能看到: 这里我们看到系统的
-
1.14 第十三部分 强化学习和控制
第十三部分 强化学习(Reinforcement Learning)和控制(Control) 这一章我们就要学习强化学习(reinforcement learning)和适应性控制(adaptive control)了。 在监督学习(supervised learning)中,我们已经见过的一些算法,输出的标签类 $y$ 都是在训练集中已经存在的。这种情况下,对于每个输入特征 $x$,都有一个对应
-
第十一章 客户端识别与cookie机制
内容提要 本章介绍了http验证用户的一种机制————cookie,以及cookie的一些概念细节! 外在原因 http最初是一个匿名、无状态的请求/响应协议。服务器处理来自客户端的请求,然后向客户端回送一条响应。web服务器几乎没有什么信息可以用来判定是哪个用户发送的请求,也无法记录来访用户的请求序列。 能解决的问题 以在线商店为例讲解有了http有了验证身份的机制之后可以实现那些功能,(当然没
-
进程进阶
第三章 进程进阶 学习进程基础和Go编程时候后,我们会接触进程更底层的概念,包括信号、进程锁和系统调用等。 通过学习这章我们对进程的所有概念都了如指掌了,充分理解这些概念后有助于我们实现更高效的应用程序。
-
Excel 将 3 个十进制数更改为完整数字,尽管有格式选项,甚至在公式中也是如此
我的一个同事把他们的Excel表格发给我,让我看一下。问题是,对于一个非常具体的数字(56136.598),Excel会自动将该数字外推到小数点后10位,而不管格式选项如何。 单元格将数字显示到正确的小数点后3位,但如果您查看公式栏中的数字,它会显示所有小数点后10位。如果我将公式写入,它甚至会将数字更改为小数点后10位。 不幸的是,鉴于我所在的行业,我需要一些解释,为什么这个非常具体的数字会引起
-
使用Jongo和Jackson2,如何将MongoDB ObjectId(在POJO中的String_id下表示)反序列化为十六进制字符串表示?
我在pom.xml中使用的依赖关系: 我的用户POJO: 我的web服务:
-
第十五章:C语言扩展
本章着眼于从Python访问C代码的问题。许多Python内置库是用C写的, 访问C是让Python的对现有库进行交互一个重要的组成部分。 这也是一个当你面临从Python 2 到 Python 3扩展代码的问题。 虽然Python提供了一个广泛的编程API,实际上有很多方法来处理C的代码。 相比试图给出对于每一个可能的工具或技术的详细参考, 我么采用的是是集中在一个小片段的C++代码,以及一些有
-
1.11 第十部分 因子分析
第十部分 因子分析(Factor analysis) 如果有一个从多个高斯混合模型(a mixture of several Gaussians)而来的数据集 $x^{(i)} \in R^n$ ,那么就可以用期望最大化算法(EM algorithm)来对这个混合模型(mixture model)进行拟合。这种情况下,对于有充足数据(sufficient data)的问题,我们通常假设可以从数据中