《集群化》专题
-
如何创建一个Linux集群以在Java中运行物理模拟?
问题内容: 我正在开发用于执行物理模拟的科学应用程序。所使用的算法为O(n3),因此对于大量数据而言,需要很长时间才能处理。该应用程序将在大约17分钟内运行一次模拟,而我必须运行大约25,000次模拟。大约一年的处理时间。 好消息是,模拟彼此完全独立,因此我可以轻松地更改程序,以在多台计算机之间分配工作。 我可以看到实现此目的的多种解决方案: 获得一台多核计算机,然后在所有核之间分配工作。我需要做
-
了解Hazelcast成员加入或离开集群会影响哪些数据
我们的服务器端解决方案利用Hazelcast提供的分布式数据结构,提供与特定集群成员上的实体相关的可用状态。 当一个集群成员加入或离开集群时,我们需要其他集群节点意识到“发生了什么变化”:例如,当一个集群成员离开时,其他集群成员需要能够确定哪些实体已经变得不可用集群事件的结果,将其与具有其他原因(例如:与此类实体的正常生命周期行为相关)的实体可用性变化分开。 一个简单的实现可以基于在每个集群成员上
-
通过TCP连接连接同一集群中的无服务Kubernetes吊舱
我可以看到这两个IP,我试图连接使用tcp套接字,绑定他们与tcp端口8080。然而,它表明它没有连接。 我认为这不是使用tcp套接字连接它们的方式。是否有任何方法使一个pod服务器和其他pod客户端和conncet使用tcp套接字。 编辑: Client.C
-
如何使用Spring Boot在集群中只执行一次计划任务?
我在使用spring Boot开发的Web应用程序中有一个预定的任务。我在tomcat集群上运行它,所以在X小时,计划的任务从每个节点开始。 我读到了:https://github.com/lukas-krecan/shedlock,所以我跟着指南走了,但它不起作用..以下是我所做的: 我在POM中包含了这些依赖项: 然后我把这个添加到我的方法中: 如何避免使用spring Boot同时执行多次任
-
自定义计划程序将吊舱留在挂起的Kubernetes群集中
我在按照Kubernetes文档中提到的指示一步一步地部署自定义调度器 下面是[链接](https://kubernetes.io/docs/tasks/administer-cluster/configure-multiple-schedulers/) …………。 ........
-
无法使用Spring Boot应用程序在集群模式下运行Camel:Quartz2
我试图在集群模式下实现Camel:Quartz2调度器。这是我的两条路线 我的Application.Properties如下所示
-
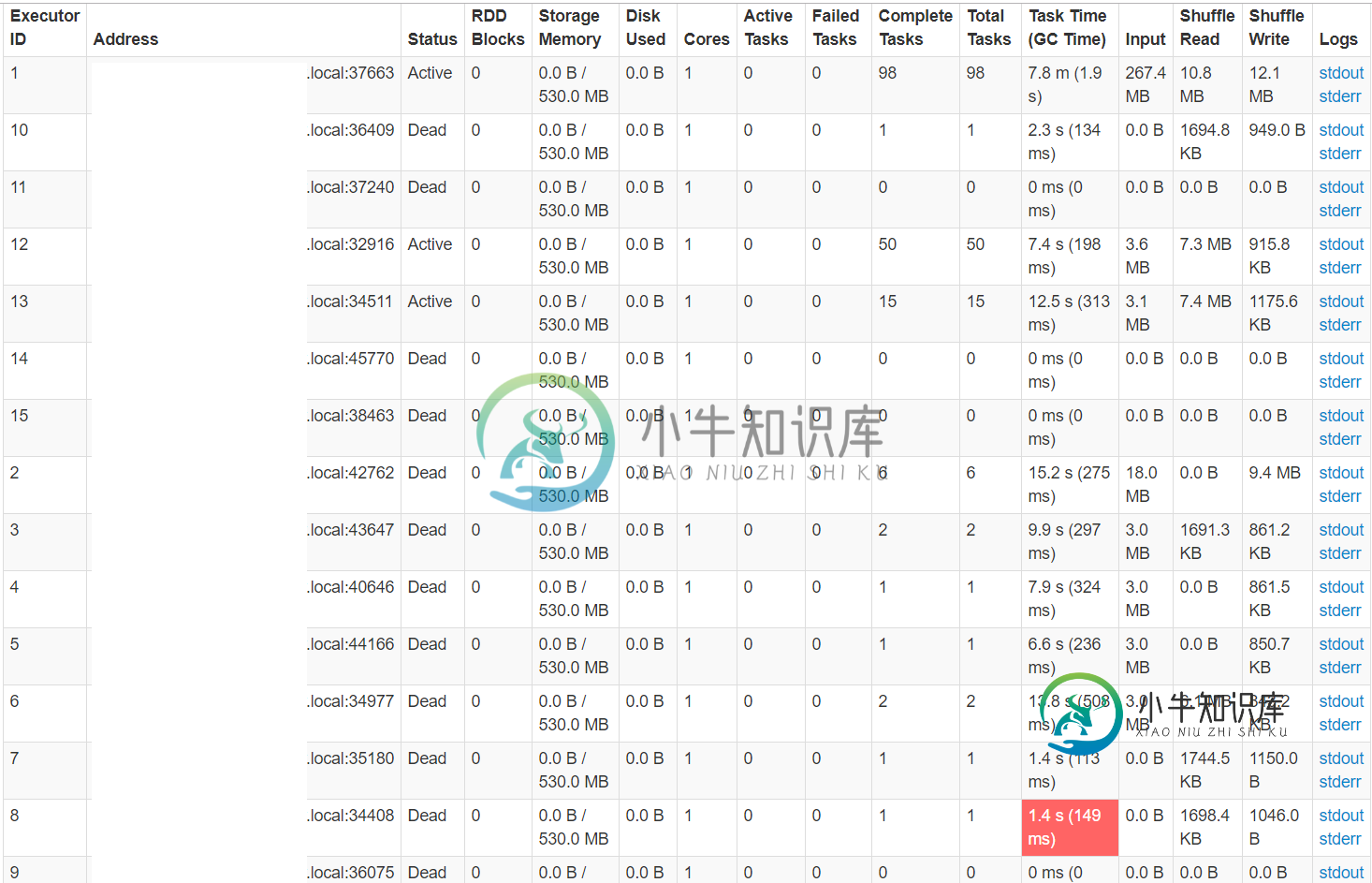 Spark性能:本地比集群快(执行器负载非常不均匀)
Spark性能:本地比集群快(执行器负载非常不均匀)让我先说我对spark相对来说是新手,所以如果我说了一些没有意义的话,请纠正我。 总结一下这个问题,不管我做什么,在某些阶段,一个执行器做所有的计算,这使得集群执行比本地的单处理器执行慢。 完整故事:我编写了一个Spark1.6应用程序,它由一系列映射、过滤器、连接和一个简短的graphx部分组成。该应用程序只使用一个数据源-csv文件。出于开发的目的,我创建了一个由100,000行7MB组成的模
-
Spark-submit/spark-shell>纱-客户端和纱-集群模式之间的区别
有两种部署模式可用于在YARN上启动Spark应用程序。在yarn-cluster模式下,Spark驱动程序在集群上由YARN管理的应用程序主进程中运行,客户端可以在启动应用程序后离开。在yarn-client模式下,驱动程序在客户端进程中运行,而应用程序主进程仅用于向YARN请求资源。 在此,我只能理解的区别是哪个地方的驱动程序在运行,但我无法理解哪个运行得更快。莫尔沃弗: 在运行Spark-s
-
无法在启用SSL的Kafka集群中注册Debezium(Kafka-Connect)连接器
我正在尝试在启用SSL的Kafka集群中注册MySql Debezium连接器。我为此目的使用的卷曲是: Debezium无法创建数据库。历史记录主题,它将失败,并出现以下错误: 美化错误:
-
SCTP端口未打开以接收来自kubernetes群集外部的流量
我有一个包含两台机器(一台主机器和一台工作机器)的集群,在工作节点上有一个pod,它提供SCTP服务。与pod相关的集群服务声明了externalIPs。externalIPs的值是工人机器的公共IP(####.###.208)。当使用helm部署pod和服务时,我可以看到pod和服务都可用,并且外部IP被分配给服务,但netstat命令的结果表明,为sctp服务定义的端口未打开以从外部世界访问,
-
Azure应用服务(Linux),NEXT JS应用,PM2无法设置群集模式
我尝试使用启动命令“PM2 runtime start ecosystem.config.JS”或“PM2--no daemon start ecosystem.config.JS”在Azure应用程序服务(Linux)的下一个JS应用程序上通过PM2设置集群。两个命令都失败。当我使用pm2运行时,传递给NodeJS脚本的当前工作目录变成:“wwwroot/econosystem.config.j
-
如何确定Redis(启用群集模式)复制组中的主要endpoint
我们有一个群集Redis设置(引擎版本5.04),其中有三个节点组,每个节点组位于各自的AZ中,每个组包含三个节点,在传输和静止时启用加密。Stunnel是在bastion主机上配置的,它允许我运行bash脚本,以便在需要时(在升级应用程序期间)刷新每个主副本。 通过控制台应用最新的Redis软件补丁后,由于自动故障切换,每个节点组中的主要endpoint都发生了更改,我正在寻找确定新主要endp
-
无法建立垂直。云环境中垂直柱之间的x群集
无法建立垂直。云环境中垂直柱之间的x群集 我在配置vert时遇到问题。x eventbus群集在私有云环境中。 在实验室测试中,我尝试使用Hazelcast集群管理器制作两个垂直点来建立一个集群,每个垂直点都在您自己的容器中运行。 问题很可能是由于配置错误引起的,但我无法找到它。在这个云上,不可能进行多播调用,那么我使用的是TCP IP发现策略。 最初的计划是制作一个“labatf api”垂直链
-
如何在安装了kubeadm的Kubernetes群集上配置入口控制器
我在Hetzner Cloud上安装了一个带有“kubeadm”的库伯内特斯集群。 安装成功后,我安装了带有Helm的入口控制器。 入口控制器服务的EXTERNAL-IP处于挂起状态。默认类型是LoadBalancer,据我所知,只有AWS、Google等云提供商才支持这种类型。。。 所以我将服务类型更改为NodePort。 我应该如何将外部DNS配置到我的服务? 我不想附加3。。。。端口,但让入
-
从群集中的Ignite本地缓存获取分布式查询数据
我在启用了本地模式集群(由2个服务器组成)中的每个节点上都有名为“igniteCache”的Ignite缓存。一定数量的条目被加载到这些本地缓存中。现在,我已经启动了单独的客户机节点,它从集群上的“igniteCache”查询数据。但当我查询数据时,总是得到空结果(而不是从两个服务器节点获取数据)