《集群化》专题
-
使用库伯内特安装Kafka和动物园管理员集群
任何人都可以分享我的yaml文件,用于创建具有两个kafka经纪人的kafka集群和具有3个服务器的动物园管理员集群。我是库伯内特斯的新手。
-
如何将新的Kafka代理机器动态添加到集群中
我们有Kafka合流集群,集群包括3个Kafka经纪人, 版本详情: 每台Kafka broker机器包括以下服务 现在,我们想要向当前的Kafka集群添加一个新的 代理计算机(其他 Kafka 计算机是 – – , ) 所以集群最终应该与: 经纪人机器- On Kafka 06-< code > broker . id = 6 编辑所有 Kafka 计算机上的 server.属性 - 并将以下参
-
 从Java连接到AWS Elasticache(Redis集群)的正确方式是什么?
从Java连接到AWS Elasticache(Redis集群)的正确方式是什么?我是AWS Elasticache redis的新手,我在endpoint以下。 我对使用Jedis和Redisson感到困惑,因为两者都提供单连接和群集连接类。 就像在Jedis,对于一个单一的连接,我们可以使用: 对于集群连接,我们使用: 当我想使用Redisson时,这些选项也会出现。我不想比较这两个库,我的问题是:当你只有一个endpoint,仍然可以利用AWS自动缩放功能时,哪一个是连接
-
我如何使用绝地连接到用于Redis集群的AWS ElastiCache?
之前,我们使用的Redis是通过AWS ElastiCache禁用集群模式的。 我们使用Jedis的Java代码指向主要的单节点endpoint,用于读写。 我们现在启用了群集模式。 现在,我们已经将代码更改为指向新Redis群集的配置endpoint,但它现在在接收请求时会抛出错误,请参见以下内容: Redis不可用。继续使用队列请求消息。org.springframework.data.red
-
Spring的绝地连接工厂是否支持新的绝地集群?
我们正在将Redis堆栈迁移到Redis集群。 在我们应用程序的某些部分,这意味着我们必须用JedisCluster对象替换Jedis对象。 在我们的Spring客户端中,我们使用JedisConnectionFactory将会话持久化到redis。但是,此类似乎不支持JedisCluster。 有没有想过如何将Spring应用程序连接到Redis集群? 我注意到这个工厂实现了RedisConne
-
Kafka集群(ZK,BR,BR,BR)中的流浪者无法建立连接
问题是我无法通过生产者脚本向集群中的任何代理发送消息。 该设置是单个动物园管理员服务器,在具有默认设置的ip (192.168.10.2:2181)上运行。 此外,还有3个代理正在运行(192.168.1001:9092192.168.11.1002:909292.168.10103:9092)。 在旋转经纪人之后,我可以在动物园管理员外壳中看到3个经纪人是连接的。 输出: 连接到192.168.
-
基于Kops AWS gossip的kubernetes集群上的fabric8控制台在哪里
我使用KOPS在AWS上部署了一个工作的基于Kubernetes Gossip的集群。在这个问题上,我部署了Fabric8。命令“gofabric8 validate”表示成功。 光栅
-
在Spark独立集群中,什么是工作者、执行者、核心?
> 执行者为每个应用程序。那么工人的角色是什么呢?它是否与执行者协调并将结果反馈给驱动程序?还是司机直接找被执行人对话?如果是的话,那么工人的目的是什么呢? 如何控制申请执行人数? 任务可以在执行器中并行运行吗?如果是,如何配置执行器的线程数? 示例2与示例1相同的集群配置,但我使用以下设置运行一个应用程序--executor-cores10--total-executor-cores10。 示例
-
etcd能否发现问题并为其他集群选出领导人?
更具体地说: > 是否可以为运行的群集以外的群集选择一个领导者,并将该信息提供给其他群集和节点? 为了更具体地说明这一点,使用上面的示例,假设上面示例中提到的MySQL DB集群中的一个主节点宕机。再次注意,MySQL DB的主服务器和副本运行在不同的集群上,与运行和承载数据的节点不同。 最后,上述任何一项都需要Kubernetes吗?或者可以单独管理外部群集吗? 如果它有帮助,这里有一个类似的问
-
如何强制condor向集群中的所有节点提交作业?
但是如果我想强迫condor使用所有的节点呢?只是为了评估在多个节点上运行时与在单个节点上运行时的进程时间? 我尝试在提交文件中添加requirements=Machine==“hostname1”&&Machine==“hostname2”,但不起作用。
-
如何检查kubernetes集群中剩余的内核数和ram容量
我有一个大约18个节点的Kubernetes集群,其中很少有4核16G RAM的节点,很少有16核64G RAM的,集群上运行着大约25-30个应用程序。 每个应用程序都配置有请求和限制参数,大约2-3个核心 现在,我如何获得当前的利用率报告,说明当前群集中还剩下多少个内核/RAM?在部署任何新应用程序之前。 我尝试使用以下命令: 这些并没有告诉我剩下的核心或内存的确切数量。 任何线索都会有很大帮
-
霍蒂奥的集群解决方案,用于开移上的骆驼
我们有一个与hawtio集成的camel应用程序,并部署在openshift环境中。这个应用程序已经被扩展成两个pod,并通过openshift路由向外界公开。 因此,通过 hawtio 致动器 url,当我们在运行时更改骆驼路由时,它已反映在任一 pod 上,而不是在两者中。我们正在寻找一种解决方案,我们可以通过hawtio url更新两个豆荚上的骆驼路线。 有人面临类似的问题吗?请提供建议。
-
在hadoop多节点群集上启动HDFS守护程序时出错
同时发布Hadoop多节点设置。一旦我开始我的hdfs恶魔在主(宾/start-dfs.sh) 我确实在主人的日志下面找到了 我确实在奴隶号上找到了下面的日志@ hadoop hduser数据节点本地主机。本地域。日志文件 有人能告诉我,设置有什么问题吗。
-
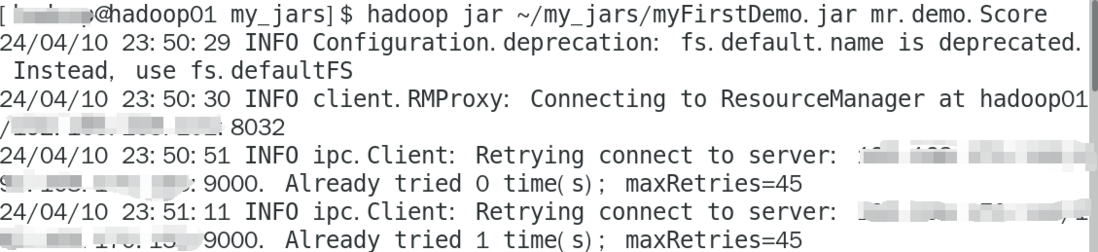 hadoop集群,为什么一直在连接9000端口,怎么解决?
hadoop集群,为什么一直在连接9000端口,怎么解决?为什么一直在连接,没有结果
-
k8s 如何使用 ClusterIP + ingress 从集群外部访问内部的 mysql?
我搭建了一个 minikube 环境 pod 和 service、ingress 的声明如下: 然后应用他们 查看 pod 状态正常 查看 services 状态正常 查看 ingress 状态正常 修改本地的 /etc/hosts 我的 minikube 的 ip 就是 192.168.49.2 然后从宿主机访问, 但是连接失败 然后我把 ClusterIP 改成 NodePort 却可以 然后