《链路追踪》专题
-
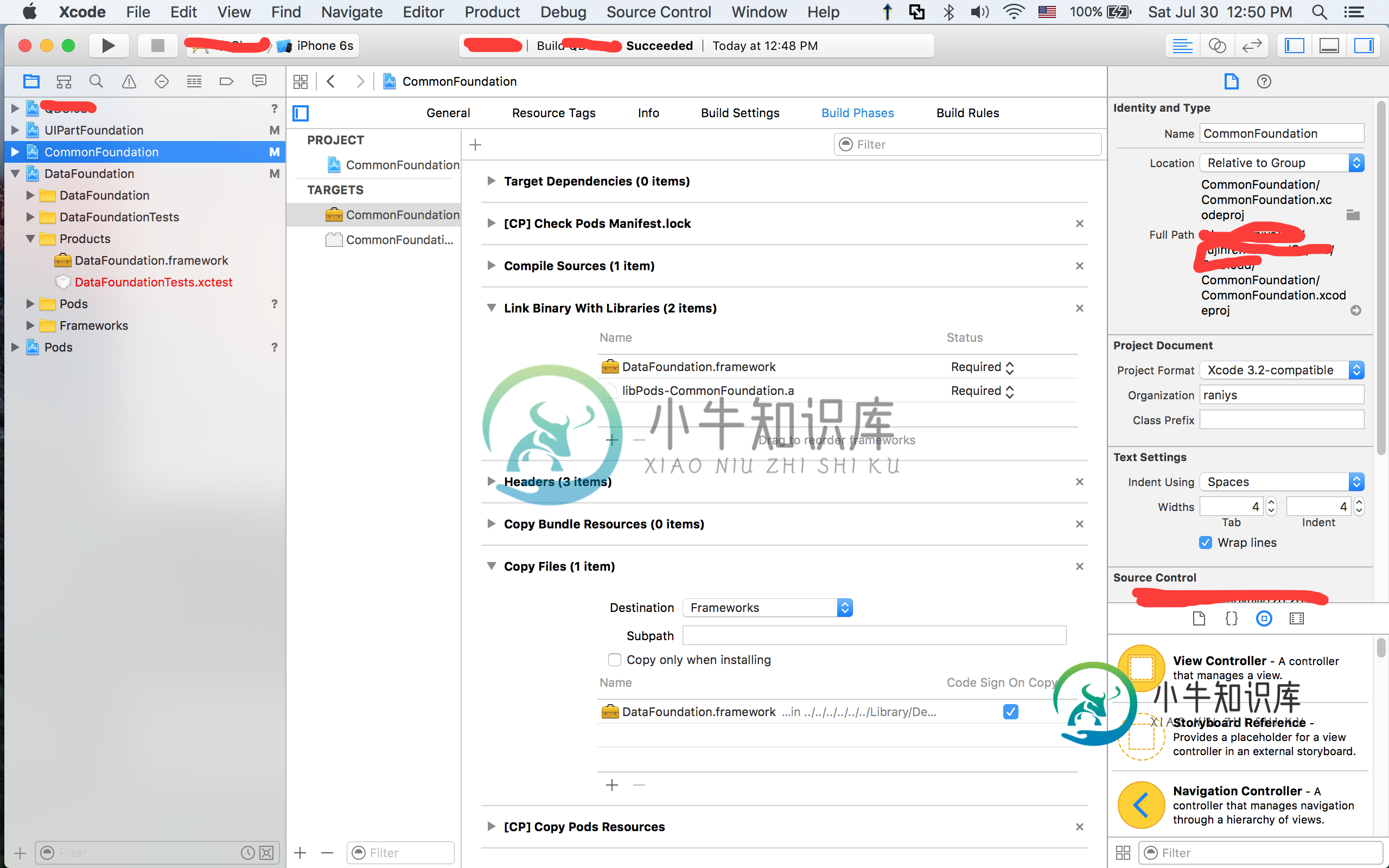 项目转移到另一个地方后,框架的链接路径发生了变化
项目转移到另一个地方后,框架的链接路径发生了变化这是我的项目结构: 1 个应用(顶部一个) 3个框架(我自己创建) 1 个可可豆荚静态库(底部一个) 当我cmd b时,所有子项目都将从底部开始构建到顶部,这没问题,一切都很好。 < li >为了引用/链接框架,我将框架产品放到每个子项目的/Build Phases/Link Binary With Libraries和/Build Phases/Copy Files中。 问题是: 当我将项目文件
-
如何使用常规JavaScript实现前置和追加?
问题内容: 如何在不使用jQuery的情况下使用常规JavaScript实现前置和追加? 问题答案: 也许您在问DOM方法和。 将节点作为现有子节点之前的子节点插入。(返回。) 如果为null,则将其添加到子级列表的末尾。等效地,更可读地使用。
-
如何在golang中将文本追加到文件中?
问题内容: 我发现os.Open()返回O_RDONLY文件,而os.Create()返回O_RDWR,但是找不到方法返回APPEND文件指针。 有什么帮助吗? 问题答案: 该OpenFile需要一个标志参数,您可以使用: 与O_CREATE一起使用,OpenFile还可以起到与os.Create()相同的作用。
-
我无法在追加到数组后修改项目
问题内容: 我正在为Unity Engine开发多人api。我有Room和RoomManager结构。当我要创建房间时,我设置房间名称id(所有变量),然后将这个新房间附加到RoomManager结构中的allRoom数组中。之后,当我修改为房间变量时,便无法更改任何变量。我不知道为什么? 这是我的结构和方法: RoomManager结构 房间结构 房间创建方法 将用户添加到房间 问题答案: 您的
-
在aa循环Python中将字典追加到列表
问题内容: 我是一名基本的python程序员,因此希望我的问题的答案会很容易。我正在尝试拿字典并将其附加到列表中。然后,字典更改值,然后再次循环添加。似乎每次执行此操作时,列表中的所有词典都会更改其值以匹配刚刚添加的值。例如: 我认为结果是,但是我得到了: 任何帮助是极大的赞赏。 问题答案: 您需要追加一个 副本 ,否则您将一遍又一遍地添加对同一词典的引用: 我用和代替和; 您不想掩盖内置类型。
-
引发异常时如何修改Python追溯对象?
问题内容: 我正在研究一个第三方开发人员用来为我们的核心应用程序编写扩展的Python库。 我想知道引发异常时是否可以修改回溯,因此最后一个堆栈帧是对开发人员代码中库函数的调用,而不是对引发异常的库中的行的调用。堆栈底部还有一些框架,其中包含对第一次加载我理想上也希望删除的代码时使用的函数的引用。 在此先感谢您的任何建议! 问题答案: 不更改回溯怎么办?您要求的两件事都可以通过不同的方式轻松完成。
-
Python创建文件和追加文件内容实例
本文向大家介绍Python创建文件和追加文件内容实例,包括了Python创建文件和追加文件内容实例的使用技巧和注意事项,需要的朋友参考一下 一、用Python创建一个新文件,内容是从0到9的整数, 每个数字占一行: 二、文件内容追加,从0到9的10个随机整数: 三、文件内容追加,从0到9的随机整数, 10个数字一行,共10行: 四、把标准输出定向到文件: 例子: 查看22端口情况,并将结果写入a.
-
如何在Swift中将元素追加到字典中?
问题内容: 我有一个简单的字典,其定义如下: 现在,我想在此字典中添加一个元素: 如何添加到现有词典中? 问题答案: 您正在使用。除非出于某种原因明确需要将其设为该类型,否则我建议使用Swift字典。 您可以通过迅捷的字典任何期望的功能而无需任何额外的工作,因为和无缝地弥合彼此。Swift的本机方式的优点是字典使用泛型类型,因此,如果将其定义为键和值,就不会错误地使用不同类型的键和值。(编译器代表
-
通过一次追加一行创建pandas数据帧
我知道pandas的设计目的是加载完全填充的,但我需要创建一个空的DataFrame,然后逐个添加行。做这件事最好的方法是什么? 我成功创建了一个空DataFrame,其中包含: 然后我可以添加一个新行,并用以下内容填充字段: 它可以工作,但看起来很奇怪:-/(它不能添加字符串值) 我如何添加一个新的行到我的数据帧(不同的列类型)?
-
通过主键将Pandas数据框追加到sqlite表
问题内容: 我想将Pandas数据框附加到名为“ NewTable”的sqlite数据库中的现有表上。NewTable具有三个字段(ID,名称,年龄),ID是主键。我的数据库连接: 我要附加的数据框: 如上所述,ID是NewTable中的主键。键“ L1”已在NewTable中,但键“ L11”不在中。我尝试将数据框追加到NewTable。 这将引发错误: 该错误很可能是因为键“ L1”已经在
-
将2D数组追加到3D数组,扩展三维
问题内容: 我有一个具有形状的数组,以及一个具有形状的数组。 如何将这两个形状附加为一个数组? 我试过了,但它没有保持尺寸,而该选项导致。 问题答案: 用途: 这可以处理数组具有不同维数的情况,并沿第三轴堆叠数组。 否则,要使用或,您必须自己制作三维尺寸并指定要在其上连接的轴:
-
创建大型Pandas DataFrame:预分配vs追加vs concat
问题内容: 逐块构建大型数据帧时,Pandas的性能令我感到困惑。在Numpy中,通过预分配一个大的空数组然后填充值,我们(几乎)总是可以看到更好的性能。据我了解,这是由于Numpy立即获取其所需的所有内存,而不是每次操作都必须重新分配内存。 在Pandas中,通过使用该模式,我似乎获得了更好的性能。 这是一个带有计时的例子。该类的定义如下。如您所见,我发现预分配比使用!慢大约10倍。使用适当的d
-
如何创建带有过渡的React Modal(追加到``)?
问题内容: 这个答案有一个模态https://stackoverflow.com/a/26789089/883571,它通过将附加到来创建基于React的模态。但是,我发现它与React提供的过渡插件不兼容。 如何创建一个带有过渡的(进入和离开期间)? 问题答案: 在2015年的React Conf上,Ryan Florence 使用门户进行了演示。这是创建简单组件的方法… 然后您通常可以在Rea
-
Google Sheet API V4(Java)在单元格中追加日期
我试图在单元格中添加日期,但工作表自动将值存储在带有单引号的字符串中()。对于在日期中存储值,我们还尝试添加,但它不适合我们。 下面是追加请求。 在工作表上附加单个日期单元格的示例代码 电子表格,单个日期值附加的示例代码
-
在Java中根据它们的大小追加列表
我试图根据它们的大小追加两个列表。前面有较大尺寸的列表。 但我无法取得适当的结果。有人能指出我的错误吗?我还在努力学习。