
T.E.E.D 1104 是一个在视频游戏中运用监督学习学习驾驶的深度神经网络,基于 PyTorch,并使用了 Nvidia 的 Apex 扩展库,支持混合精度训练与推断,最多有两倍的速度提升。

该项目的主要目的是实现一种可以在侠盗猎车手 5(GTAV,Grand Theft Auto V)中行驶的模型,实际可以适应于玩任何现有的视频游戏。该模型并不是按照交通法规进行驾驶,而是模仿人类在此游戏中的驾驶方式:全速行驶、避开其它汽车/人类/路灯行驶。
模型使用人类标记数据进行训练,在玩游戏时记录游戏和人类的主要输入数据,用于训练模型。
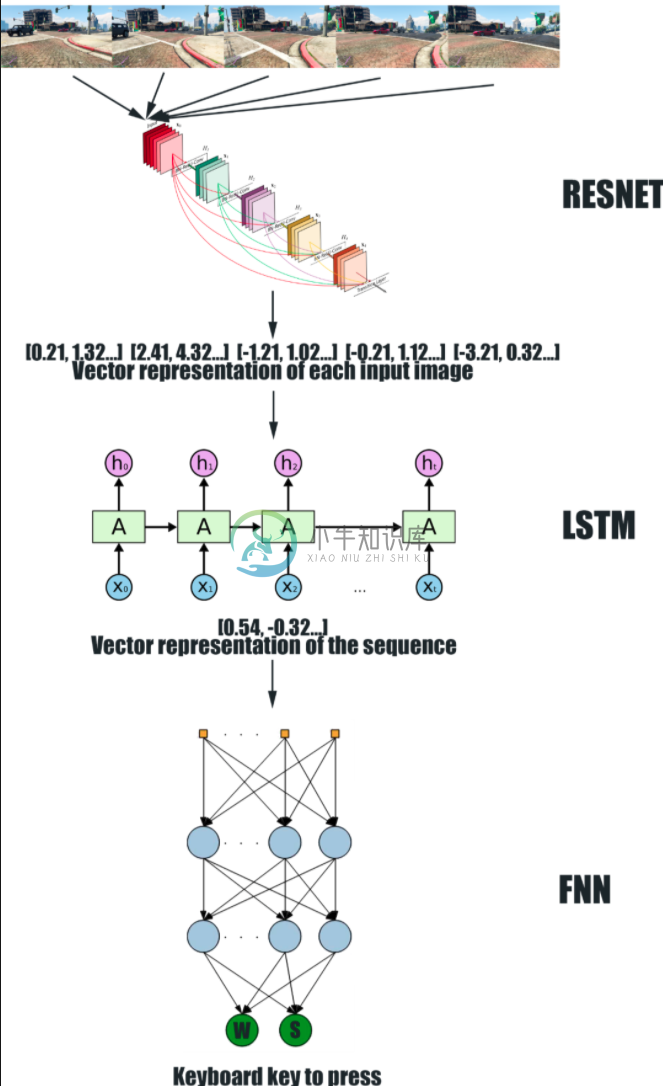
T.E.E.D 1104 由一个深度卷积神经网络(CNN)Resnet 与一个递归神经网络(RNN)LSTM 组成。CNN 接收 5 个图像序列作为输入,并为每个图像生成矢量表示。这些表示被输入到 RNN 中,该 RNN 为整个序列生成唯一的矢量表示。最后,前馈神经网络根据序列的矢量表示输出要在键盘上按下的键。
-
⑴什么是DCE? DCE:数据通信设备,DTE:数据终端设备. 1)只有在同步通信方式的线 路上才会有时钟速率,同步通信时需要线路两端进行信号发送频率的同步,也就是同步的时钟,在实际工程中由协议转换器,modem等线路控制设备来提供,而 实验环境中没有专门的线路控制设备,所以由其中的一台router的serial接口来提供。DCE一端的确定是由router之间的cable的线序来 决定的,所以ba
-
周报1104-1110 本周总结 论文梳理 RDN(CVPR 2017) 原文指出其结构可支持超过400层的网络训练,原文只有16x8=128层 residual dense block 稠密链接的问题在于参数量较大,并且稠密链接信息不全为有用信息 RCAN(ECCV 2018) 抛弃了RDN中的dense,猜测是因为其加大了网络参数,但是对最终指标并没有太大的提高 通道注意力 层数进一步增加至2
-
为了实现对金融机构的数据信息进行持续的系统监测和分析,早在2003年11月,银监会就计划用三年左右的时间建立一个“统一规划、统一管理、统一标准、资源共享”的非现场检查信息技术平台。银监会称其为“1104工程”。随着该工程的推进,银监会提出精细化监管的思路,对整个监管业务流程进行了重新设计。新的业务流程亦是一条完整的信息流,每一监管环节都将被记录到银监会新的数据系统中,使被监管机构各方面包括历年的所
-
近年来,在银监会和各银监分局的指导下,在社会各界的大力支持下,城市商业银行通过自身的不懈努力,取得了显著的成绩,市场份额稳步提高,有力地支持了地方经济发展。已经成为金融系统最具生机和活力的契机,同时随着银行业的改革深化,城商行面临前所未有的挑战,及时制订策略应对各类挑战,对于城商行下一步的稳步发展具有重要的意义。在这样的形式下,中国城市商业银行第七次会议和城市商业银行发展论坛在山东济南召开,中国银
-
1101 b是a的多少倍 #include <iostream> #include <cstring> using namespace std; int main() { string s; cin >> s; int a; cin >> a; string s1 = s.substr(s.length() - a); s1 += s.subst
-
神经网络和深度学习是一本免费的在线书。本书会教会你: 神经网络,一种美妙的受生物学启发的编程范式,可以让计算机从观测数据中进行学习 深度学习,一个强有力的用于神经网络学习的众多技术的集合 神经网络和深度学习目前给出了在图像识别、语音识别和自然语言处理领域中很多问题的最好解决方案。本书将会教你在神经网络和深度学习背后的众多核心概念。 想了解本书选择的观点的更多细节,请看这里。或者直接跳到第一章 开始
-
深度神经网络的工作地点、原因和方式。从大脑中获取灵感。卷积神经网络(CNN)和循环神经网络(RNN)。真实世界中的应用。 使用深度学习,我们仍然是习得一个函数f,将输入X映射为输出Y,并使测试数据上的损失最小,就像我们之前那样。回忆一下,在 2.1 节监督学习中,我们的初始“问题陈述”: Y = f(X) + ϵ 训练:机器从带标签的训练数据习得f 测试:机器从不带标签的测试数据预测Y 真实世界很
-
本文向大家介绍TensorFlow深度学习之卷积神经网络CNN,包括了TensorFlow深度学习之卷积神经网络CNN的使用技巧和注意事项,需要的朋友参考一下 一、卷积神经网络的概述 卷积神经网络(ConvolutionalNeural Network,CNN)最初是为解决图像识别等问题设计的,CNN现在的应用已经不限于图像和视频,也可用于时间序列信号,比如音频信号和文本数据等。CNN作为一个深度
-
我计划编写一个国际象棋引擎,它使用深度卷积神经网络来评估国际象棋的位置。我将使用位板来表示棋盘状态,这意味着输入层应该有12*64个神经元用于位置,1个用于玩家移动(0表示黑色,1表示白色)和4个神经元用于铸币权(wks、bks、wqs、bqs)。将有两个隐藏层,每个层有515个神经元,一个输出神经元的值介于-1表示黑色获胜,1表示白色获胜,0表示相等的位置。所有神经元都将使用tanh()激活函数
-
LeNet 5 LeNet-5是第一个成功的卷积神经网络,共有7层,不包含输入,每层都包含可训练参数(连接权重)。 AlexNet tf AlexNet可以认为是增强版的LeNet5,共8层,其中前5层convolutional,后面3层是full-connected。 GooLeNet (Inception v2) GoogLeNet用了很多相同的层,共22层,并将全连接层变为稀疏链接层。 In
-
我写的神经网络可以玩井字游戏。网络有9个输入神经元,它们描述板的状态(1-代表网络移动,1.5-代表对手移动,0-代表空单元)和9个输出神经元(具有最高值的输出神经元表示给定状态下的最佳动作)。网络没有隐藏层。激活函数-乙状结肠。学习方法--Q学习+反向传播。 网络是经过训练的,但很差(继续踩在被占用的单元格上)。所以我决定添加一个隐藏层。我想问: 在隐藏层中使用多少个神经元,在隐藏层和输出层中使
-
我想问在棋盘游戏中使用标准的具有TD学习方法的反向传播神经网络是否有意义? 我的方法看起来像: > < li >玩一局。Net同时扮演着贪婪策略和随机移动的角色。 < li> 对于每个存储的游戏位置(从终端1开始并移动到开始位置),计算估计位置值和期望位置值,例如 利用标准反向传播算法,从整个游戏结束训练中为网络创建训练模式,每个模式具有1个时期的小学习率。 在我的井字游戏中,我尝试了以上的一些组
-
代码见nn_overfit.py 优化 Regularization 在前面实现的RELU连接的两层神经网络中,加Regularization进行约束,采用加l2 norm的方法,进行负反馈: 代码实现上,只需要对tf_sgd_relu_nn中train_loss做修改即可: 可以用tf.nn.l2_loss(t)对一个Tensor对象求l2 norm 需要对我们使用的各个W都做这样的计算(参考t