
TensorFlow神经网络优化策略学习

在神经网络模型优化的过程中,会遇到许多问题,比如如何设置学习率的问题,我们可通过指数衰减的方式让模型在训练初期快速接近较优解,在训练后期稳定进入最优解区域;针对过拟合问题,通过正则化的方法加以应对;滑动平均模型可以让最终得到的模型在未知数据上表现的更加健壮。
一、学习率的设置
学习率设置既不能过大,也不能过小。TensorFlow提供了一种更加灵活的学习率设置方法——指数衰减法。该方法实现了指数衰减学习率,先使用较大的学习率来快速得到一个比较优的解,然后随着迭代的继续逐步减小学习率,使得模型在训练后期更加稳定,缓慢平滑得达到最优值。
tf.train.exponential_decay(learning_rate, global_step, decay_steps, decay_rate,staircase=False, name=None)
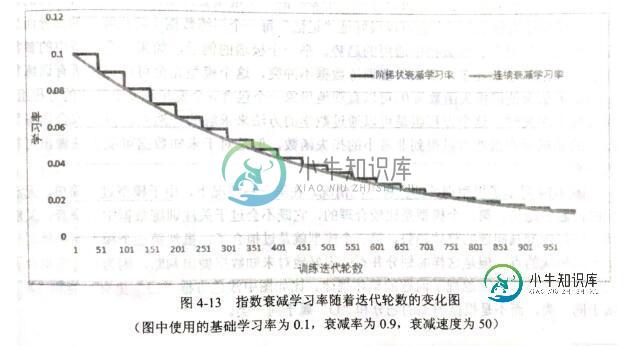
该函数会指数级减小学习率,实现每轮实际优化时的衰减后的学习率decayed_learning_rate = learning_rate * decay_rate ^ (global_step /decay_steps),learning_rate为设定的出事学习率,decay_rate为衰减系数,decay_steps为衰减速度。如下图,参数staircase=False时,学习率变化趋势为浅色部分;staircase=True时为深色部分,使得学习率变化为阶梯函数(staircase function),这种设置的常用应用场景是每完整地过完一遍训练数据,学习率就减小一次。
使用示例:learning_rate =tf.train.exponential_decay(starter_learning_rate, global_step, 100000, 0.96,staircase=True)。
二、过拟合问题
1. 过拟合问题及其解决方法
所谓过拟合问题,指的是当一个模型过于复杂后,它可以很好地记忆每一个训练数据中随机噪声的部分而忘记了要去学习训练数据中通用的趋势。
为了避免过拟合问题,常用的方法是正则化(Regularization),思想是在损失函数中加入刻画模型复杂程度的指标,将优化目标定义为J(θ)+λR(w) ,其中R(w)刻画的是模型的复杂程度,包括了权重项w不包括偏置项b,λ表示模型复杂损失在总损失中的比例。一般来说模型复杂度只由权重w决定。常用的刻画模型复杂度的函数R(w)有两种,一种是L1正则化:

另一种是L2正则化:

无论哪种正则化方式,基本思想都是希望通过限制权重的大小,使得模型不能任意拟合训练数据中的随机噪音。区别:L1正则化会让参数变得更稀疏,L2则不会,所谓参数变得更稀疏是指会有更多的参数变为0,可达到类似特征选取的功能。实践中,也可以将L1正则化和L2正则化同时使用:

2. 过拟合问题的TensorFlow解决方案
loss =tf.reduce_mean(tf.square(y_ - y) + tf.contrib.layers.l2_regularizer(lambda)(w)
以上就是一个含L2正则化项的损失函数。第一部分是均方误差损失函数,第二部分就是正则化项。lambda参数表示正则化项的权重,也就是J(θ)+λR(w)中的λ,w为需要计算正则化损失的参数。tf.contrib.layers.l2_regularize()函数可以计算给定参数的L2正则化项,类似地,tf.contrib.layers.l1_regularizer()可以就是那给定参数的L1正则化项。
# 比较L1正则化和L2正则化函数的作用效果 w = tf.constant([[1.0, -2.0], [-3.0, 4.0]]) with tf.Session() as sess: # 0.5*(|1|+|-2|+|-3|+|4|=5.0) print(sess.run(tf.contrib.layers.l1_regularizer(0.5)(w))) # 5.0 # 0.5*[(1+4+9+16)/2]=7.5 TensorFlow会将L2正则化项除以2使得求导的结果更简洁 print(sess.run(tf.contrib.layers.l2_regularizer(0.5)(w))) # 7.5
当神经网络的参数增多以后,上面的定义损失函数的方式会导致loss的定义式很长,可读性差,另外当网络结构复杂后定义网络结构的部分和计算损失函数的部分可能不在同一个函数中,通过变量方式计算损失函数就不方便了。为解决此问题,可以使用TensorFlow中提供的集合(collection)。具体实现见代码部分。
tf.add_to_collection()将变量加入至指定集合中;tf.get_collection()返回一个列表,存储着这个集合中的元素。
三、滑动平均模型
另一个使模型在测试数据上更健壮(robust)滑动平均模型。在采用随机梯度下降算法训练神经网络时,使用滑动平均模型在很多应用中可提高最终模型在测试数据上的表现,GradientDescent和Momentum方式的训练都能够从ExponentialMovingAverage方法中获益。
在TensorFlow中提供的tf.train.ExponentialMovingAverage是一个类class,来实现滑动平均模型。初始化tf.train.ExponentialMovingAverage类对象时,须指定衰减率decay和用于动态控制衰减率的参数num_updates。tf.train.ExponentialMovingAverage对每一个变量维护一个影子变量(shadow variable),该影子变量的初始值就是相应变量的初始值,每次变量更新时,shadow_variable =decay * shadow_variable + (1 - decay) * variable。从公式中可看出,decay决定了模型更新的速度,decay越大模型越趋于稳定,实际应用中decay一般设置为接近1的数。num_updates默认是None,若设置了,则衰减率按min(decay, (1 +num_updates) / (10 + num_updates))计算。
tf.train.ExponentialMovingAverage对象的apply方法返回一个对var_list进行更新滑动平均的操作,var_list必须是list的Variable或Tensor,该操作执行会更新var_list的影子变量shadowvariable。average方法可获取滑动平均后变量的取值。
四、代码呈现
1. 复杂神经网络结构权重L2正则化方法
import tensorflow as tf
'''''
# 比较L1正则化和L2正则化函数的作用效果
w = tf.constant([[1.0, -2.0], [-3.0, 4.0]])
with tf.Session() as sess:
# 0.5*(|1|+|-2|+|-3|+|4|=5.0)
print(sess.run(tf.contrib.layers.l1_regularizer(0.5)(w))) # 5.0
# 0.5*[(1+4+9+16)/2]=7.5 TensorFlow会将L2正则化项除以2使得求导的结果更简洁
print(sess.run(tf.contrib.layers.l2_regularizer(0.5)(w))) # 7.5
'''
# 复杂神经网络结构权重L2正则化方法
# 定义各层的权重,并将该权重的L2正则化项加入至名称为‘losses'的集合
def get_weight(shape, lambda1):
var = tf.Variable(tf.random_normal(shape), dtype=tf.float32)
tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(lambda1)(var))
return var
x = tf.placeholder(tf.float32, (None, 2))
y_ = tf.placeholder(tf.float32, (None, 1))
layer_dimension = [2,10,5,3,1] # 定义了神经网络每层的节点数
n_layers = len(layer_dimension)
current_layer = x # 将当前层设置为输入层
in_dimension = layer_dimension[0]
# 通过循环生成一个5层全连接的神经网络结构
for i in range(1,n_layers):
out_dimension = layer_dimension[i]
weight = get_weight([in_dimension,out_dimension], 0.003)
bias = tf.Variable(tf.constant(0.1, shape=[out_dimension]))
current_layer = tf.nn.relu(tf.matmul(current_layer, weight) + bias)
in_dimension = layer_dimension[i]
mse_loss = tf.reduce_mean(tf.square(y_ - current_layer))
tf.add_to_collection('losses', mse_loss)
loss = tf.add_n(tf.get_collection('losses')) # 包含所有参数正则化项的损失函数
2. tf.train.ExponentialMovingAverage使用样例
import tensorflow as tf # tf.train.ExponentialMovingAverage使用样例 v1 = tf.Variable(0, dtype=tf.float32) step = tf.Variable(0, trainable=False) # 此处step模拟神经网络迭代的轮数 # 定义一个滑动平均的类对象,初始化衰减率decay=0.99,用于动态控制衰减率的参数num_updates ema = tf.train.ExponentialMovingAverage(0.99, num_updates=step) # apply方法返回一个对var_list进行更新滑动平均的操作,var_list必须是list的Variable或Tensor # 该操作执行会更新var_list的影子变量shadow variable maintain_averages_op = ema.apply(var_list=[v1]) with tf.Session() as sess: init_op = tf.global_variables_initializer() sess.run(init_op) # average方法可获取滑动平均后变量的取值 print(sess.run([v1, ema.average(v1)])) # [0.0, 0.0] sess.run(tf.assign(v1, 5)) # min{0.99, (1+step)(10+step)=0.1}=0.1 # 更新v1的滑动平均值为 0.1*0.0+0.9*5=4.5 sess.run(maintain_averages_op) print(sess.run([v1, ema.average(v1)])) # [5.0, 4.5] sess.run(tf.assign(step, 10000)) sess.run(tf.assign(v1, 10)) # min{0.99, (1+step)(10+step)=0.999}=0.99 # 更新v1的滑动平均值为 0.99*4.5+0.01*10=4.555 sess.run(maintain_averages_op) print(sess.run([v1, ema.average(v1)])) # [10.0, 4.5549998] # 更新v1的滑动平均值为 0.99*4.555+0.01*10=4.60945 sess.run(maintain_averages_op) print(sess.run([v1, ema.average(v1)])) # [10.0, 4.6094499]
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
主要内容:使用TensorFlow实现递归神经网络递归神经网络是一种面向深度学习的算法,遵循顺序方法。在神经网络中,我们总是假设每个输入和输出都独立于所有其他层。这些类型的神经网络称为循环,因为它们以顺序方式执行数学计算。 考虑以下步骤来训练递归神经网络 - 第1步 - 从数据集输入特定示例。 第2步 - 网络将举例并使用随机初始化变量计算一些计算。 第3步 - 然后计算预测结果。 第4步 - 生成的实际结果与期望值的比较将产生错误。 第5步 -
-
在了解了机器学习概念之后,现在可以将注意力转移到深度学习概念上。深度学习是机器学习的一个分支。深度学习实现的示例包括图像识别和语音识别等应用。 以下是两种重要的深度神经网络 - 卷积神经网络 递归神经网络 在本章中,我们将重点介绍CNN - 卷积神经网络。 卷积神经网络 卷积神经网络旨在通过多层阵列处理数据。这种类型的神经网络用于图像识别或面部识别等应用。CNN与其他普通神经网络之间的主要区别在于
-
本文向大家介绍TensorFlow深度学习之卷积神经网络CNN,包括了TensorFlow深度学习之卷积神经网络CNN的使用技巧和注意事项,需要的朋友参考一下 一、卷积神经网络的概述 卷积神经网络(ConvolutionalNeural Network,CNN)最初是为解决图像识别等问题设计的,CNN现在的应用已经不限于图像和视频,也可用于时间序列信号,比如音频信号和文本数据等。CNN作为一个深度
-
我知道前馈神经网络的基本知识,以及如何使用反向传播算法对其进行训练,但我正在寻找一种算法,以便使用强化学习在线训练神经网络。 例如,我想用人工神经网络解决手推车杆摆动问题。在这种情况下,我不知道应该怎么控制钟摆,我只知道我离理想位置有多近。我需要让安在奖惩的基础上学习。因此,监督学习不是一种选择。 另一种情况类似于蛇游戏,反馈被延迟,并且仅限于进球和反进球,而不是奖励。 我可以为第一种情况想出一些
-
我试图用TensorFlow建立一个简单的神经网络。目标是在32像素x 32像素的图像中找到矩形的中心。矩形由五个向量描述。第一个向量是位置向量,其他四个是方向向量,组成矩形边。一个向量有两个值(x和y)。 该图像的相应输入为(2,5)(0,4)(6,0)(0,-4)(-6,0)。中心(以及所需输出)位于(5,7)。 我想出的代码如下所示: 遗憾的是,网络无法正常学习。结果太离谱了。例如,[[3.
-
我正在建立一个分类神经网络,以便对两个不同的类进行分类。 所以这是一个二元分类问题,我正尝试用一个前馈神经网络来解决这个任务。 但是网络是不能学习的,事实上,在训练过程中,网络的精度是不变的。 具体而言,数据集由以下人员组成: 65673行22列。 其中一列是具有值(0,1)的目标类,而其他21列是预测器。数据集是这样平衡的: null 可以看到也有NaN值,但我不能删除它,因为在其他列中有值0是