《flink》专题
-
flink DataStream keyBy API
-
Flink stucks在创建检查点时
我有一份很轻松的工作,在创建检查站方面很吃力。它几乎没有州(除了一些Kafka偏移)。 工作本身有以下基本设置: Kafka索资源- 迭代函数再次执行HTTP调用并转发成功的消息,丢弃4xx并重试5xx。从我的指标中可以看到,所有这些都发生了,我得到了一些5xx(返回迭代源)、一些4xx(忽略)和很多2xx(转发到HDFS)。 如果我查看线程转储,我可以看到某个任务被阻止了: 这一个正在等待对象监
-
Flink:关于Flink检查点和保存点的查询
下面是我对Flink的疑问。 我们可以将检查点和保存点存储到RockDB等外部数据结构中吗?还是只是我们可以存储在RockDB等中的状态。 状态后端是否会影响检查点?如果是,以何种方式? 什么是状态处理器API?它与我们存储的保存点和检查点直接相关吗?状态处理器API提供了普通保存点无法提供的哪些额外好处? 对于3个问题,请尽可能描述性地回答。我对学习状态处理器API很感兴趣,但我想深入了解它的应
-
无法将点/检查点flink状态保存到AWS S3存储桶
我试图检查/保存我在EMR上运行的flink状态到AWS上的s3存储桶。请注意: 实例(主节点和核心节点)正确设置了IAM角色,以访问s3 bucket及其内部的所有目录/文件(AmazonS3FullAccess策略附加到该角色,没有任何内容覆盖它) jobmanager日志:
-
Flink中保存点和检查点之间的差异
我知道stackoverflow上也有类似的问题,但在调查了其中几个之后,我知道 > 他们正在使用不同的存储格式 但这些并不是令人困惑的地方,我不知道什么时候该用一个,什么时候该用另一个。 考虑以下两种情况: 如果由于某种原因(例如错误修复或意外崩溃)需要关闭或重新启动整个应用程序,那么我必须使用保存点来恢复整个应用程序
-
Flink SQL支持Java映射类型吗?
我正在尝试使用Flink的SQL API从地图访问密钥。它失败,线程“main”组织中出现错误异常。阿帕奇。Flink。桌子应用程序编程接口。TableException:不支持类型:任何请告知我如何修复它。这是我的活动课 这是提交flink作业的主类 当我运行它时,我得到了例外 我正在使用flink 1.3.1
-
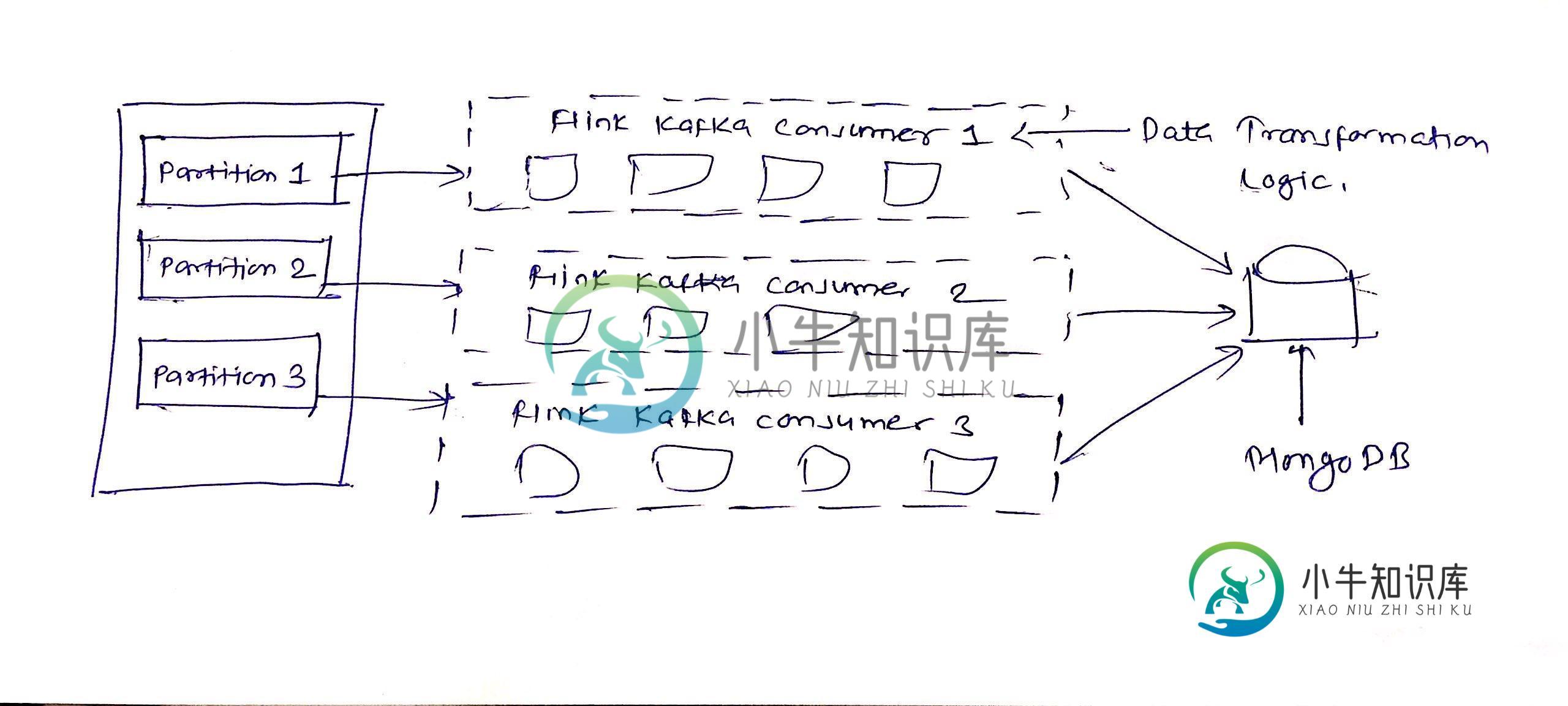 分区专用flink kafka使用者
分区专用flink kafka使用者我使用flink和Kafka创建了一个流媒体程序,用于流媒体mongodb oplog。根据与Flink支持团队的讨论,流的顺序不能通过kafka分区来保证。我已经创建了N个kafka分区,并希望每个分区创建N个flink kafka消费者,所以流的顺序应该至少在特定的分区中保持。请建议我是否可以创建分区特定的flink kafka消费者? 我正在使用env.setParallelism(N)进行
-
Flink-使用匕首注射-不可串行化?
我使用Flink(最新的git)从Kafka流到卡桑德拉。为了简化单元测试,我通过dagger添加了依赖注入。 ObjectGraph似乎正确地设置了自己,但是“内部对象”被Flink标记为“不可序列化”。如果我直接包括这些对象,它们会起作用--那么有什么区别呢? 通过Dagger Lazy 实例化的对象也不会序列化。 线程“main”org.apache.flink.api.common.inv
-
如何在Flink中使用LocalDate字段高效地序列化POJO?
-
java.util.List和java.util.Map的Flink序列化
我的Flink管道目前使用一个Pojo,它包含一些列表和(字符串的)映射,如下所示
-
Flink窗口状态大小和状态管理
在阅读了Flink的文档并四处搜索后,我无法完全理解Flink的句柄在其窗口中的状态。假设我有一个每小时滚动的窗口,其中包含一个聚合函数,该函数将消息累积到某个java pojo或scala case类中。该窗口的大小将与一小时内进入该窗口的事件数量相关联,还是仅仅与POJO/Case类相关联,因为我将事件累加到该对象中。(例如,如果将10000个味精数成一个整数,大小会接近10000*味精大小还
-
使用registerTypeWithKryoSerializer的Flink自定义序列化
让我知道你的想法,并祝贺这一惊人的作品。在以前的项目中,我们确实使用了storm或spark流媒体,但Flink在实时流媒体分析方面遥遥领先。 谢谢,继续努力!
-
Flink如何处理托管状态的序列化?
Flink以何种格式保存运算符的托管状态(用于检查点或逻辑运算符之间的通信(即沿着作业图的边缘)? 文档内容如下 背景:我正在考虑从JSON切换到使用AVRO来将数据输入到我的源中,并将数据发送到我的接收器中。但是,由Avro创建的自动生成的POJO类相当嘈杂。因此,在作业图(用于Flink操作符之间的通信)中,我正在考虑使用像Avro这样的二进制序列化格式是否有任何性能优势。这可能对性能没有实质
-
Flink序列化:POJO类型与GenericType
在我的Flink应用程序中,我使用java.time.instant表示UTC时间戳。应用程序运行良好,但我最近在Flink日志中注意到这条消息: “类class java.time.instant不能用作POJO类型,因为并非所有字段都是有效的POJO字段,必须作为GenericType处理。有关对性能影响的详细信息,请阅读Flink文档中的”数据类型&序列化“。”
-
Flink keyBy与RichParallelSourceFunction
我正在学习flink,试图理解一些概念。以下是几个问题: 对流的操作与从像这样的儿童获取源代码有什么区别?这两个操作都分割流。 还尝试实现一个非常简单的keyBy操作符来理解它,如下所示: 但我得到的输出令人困惑: 这意味着在子任务3上执行的所有内容。有人能帮忙解释一下原因吗?