
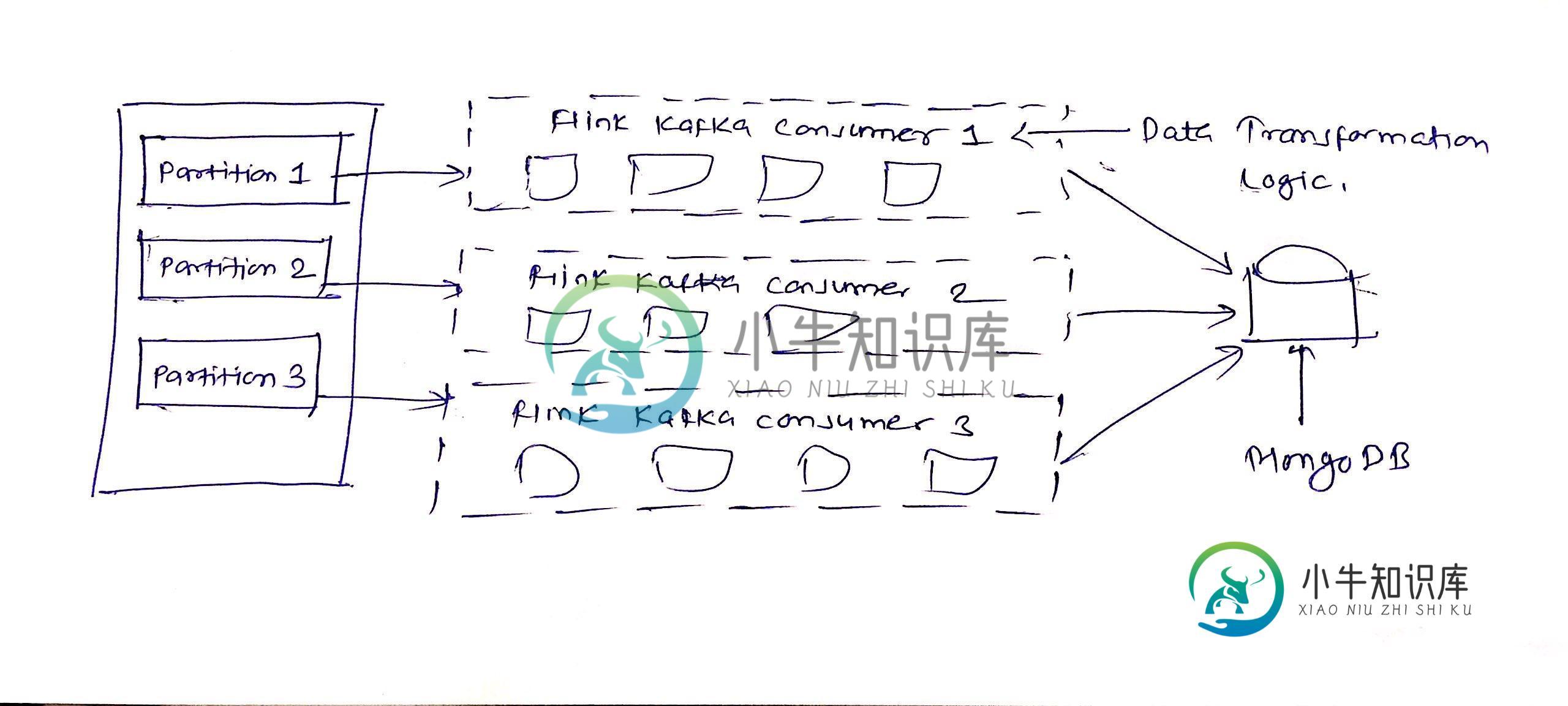
分区专用flink kafka使用者

我使用flink和Kafka创建了一个流媒体程序,用于流媒体mongodb oplog。根据与Flink支持团队的讨论,流的顺序不能通过kafka分区来保证。我已经创建了N个kafka分区,并希望每个分区创建N个flink kafka消费者,所以流的顺序应该至少在特定的分区中保持。请建议我是否可以创建分区特定的flink kafka消费者?
我正在使用env.setParallelism(N)进行并行处理。
共有1个答案

在做了大量的研究后,我找到了自己问题的解决办法。由于对kafka分区进行全局排序是不现实的,我创建了N个具有N个flink并行度的kafka分区,并编写了一个自定义的kafka分区器,它将覆盖默认的kafka分区策略,并根据自定义分区器中指定的逻辑将记录发送到特定的分区。这样可以确保特定的消息总是发送到同一个分区。当设置flink并行时,请在脑海中记住以下几点。
1)kafka partitions==flink Parallelism:这种情况是理想的,因为每个用户负责一个分区。如果您的消息在分区之间是平衡的,那么工作将均匀地分散在flink操作符之间;
2)kafka分区
-
我对Apache Kafka是新手,我试图理解以下两个方面的区别: 创建属于同一组id的两个使用者,这些使用者来自同一主题的两个分区。 用两个线程创建一个使用者,这些线程来自同一主题的两个分区。 在第一种方法中,我实际上理解的是,每个使用者将只使用与之“相关”的分区的消息,因为这两个使用者属于同一个组。 因此,在下面的示例中,可能会发生一些不同的情况: Thread1使用AAAA和CCCC/Thr
-
大家好,我正在努力将一个简单的avro模式与模式注册表一起序列化。 设置: 两个用java编写的Flink jobs(一个消费者,一个生产者) 目标:生产者应该发送一条用ConfluentRegistryAvroSerializationSchema序列化的消息,其中包括更新和验证模式。 然后,使用者应将消息反序列化为具有接收到的模式的对象。使用。 到目前为止还不错:如果我将架构注册表上的主题配置
-
我正在使用Kafka Producer和RoundRobin分区器来处理一个有12个分区的主题。 代码可在此处找到https://github.com/apache/kafka/blob/2.8/clients/src/main/java/org/apache/kafka/clients/producer/RoundRobinPartitioner.java 我面临的问题是,这个分区程序让分区正确
-
SuperMap Online提供路径导航、正/逆地理编码、坐标转换、本地搜索等常用的分析服务。GIS云分析服务是以“GIS功能+全国基础数据“的方式提供的REST服务,是可以直接拿来就用的GIS能力。您可以直接在业务系统中,通过REST API调用这些服务,也可以将GIS云存储的数据服务和上述云分析服务结合在一起进行应用开发。 点击了解更多详细信息。
-
一些无聊有趣的知识,如果你是一个正经讲究人,可以跳过这个版块以节约你的阅读时间。 cmatrix 《黑客帝国》的代码雨视觉特效。Bash pkg install cmatrix cmatrix cowsay cowsay 命令是一个有趣的命令,它会用 ASCII 字符描绘牛,羊和许多其他动物,还可以附带上个自定义文本,很巧的是 Termux 也封装了这个工具。Bash pkg intall cow
-
我的消费者并不是每次都能收到信息。我有3个代理(3个服务器)的Kafka集群,有3个主题和复制因子3的分区。 我有Java中的消费者,我将最大轮询记录设置在50000获取字节上,配置在50MB上。应用程序每分钟都进行轮询。当我向主题“my-topic”发送10条消息时,consumer不会给我所有的消息,而是只给我其中的一部分,其余的将在下一次运行中给我。消息是在applicatin睡眠期间由脚本