
Kafka使用者/分区与线程/分区关系

我对Apache Kafka是新手,我试图理解以下两个方面的区别:
- 创建属于同一组id的两个使用者,这些使用者来自同一主题的两个分区。
- 用两个线程创建一个使用者,这些线程来自同一主题的两个分区。
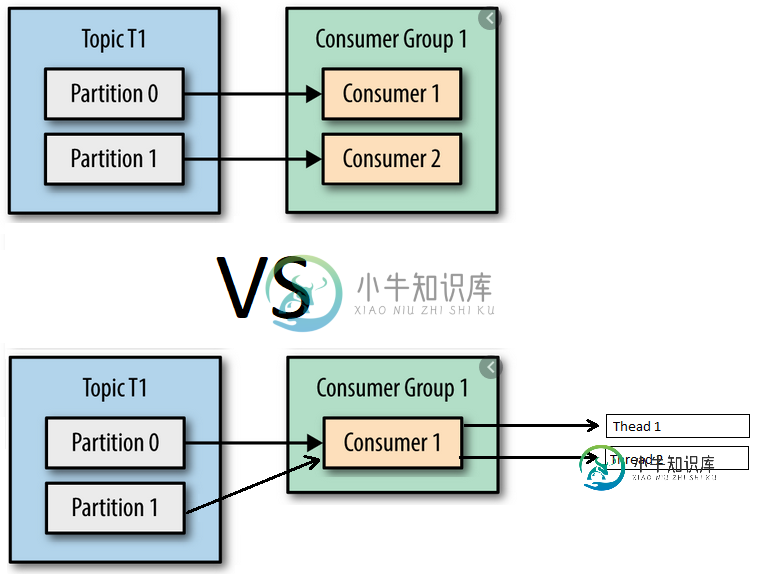
在第一种方法中,我实际上理解的是,每个使用者将只使用与之“相关”的分区的消息,因为这两个使用者属于同一个组。
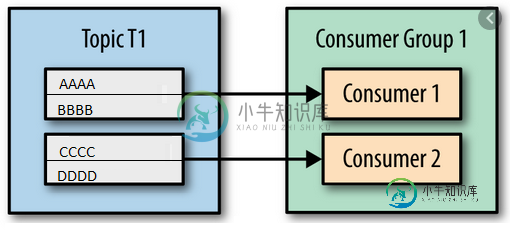
因此,在下面的示例中,可能会发生一些不同的情况:
- Thread1使用AAAA和CCCC/Thread2使用BBBB和DDDD
- Thread1使用AAAA,BBBB/Thread2使用CCCC和DDDD
- Thread1使用AAAA和DDDD/Thread2使用CCCC和BBBB
- Thread1使用CCCC,DDDD/Thread2使用AAAA和BBBB
- Thread1使用BBBB,DDDD/Thread2使用AAAA和CCCC
- Thread1使用BBBB,CCCC/Thread2使用AAAA和DDDD
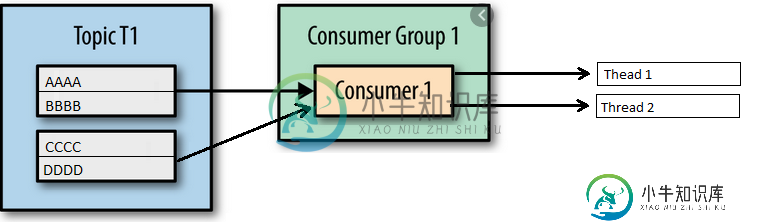
这两种方法之间的区别看起来微不足道。在第一种方法中,每个使用者只使用顺序分配给它的分区,而在第二种方法中,每个线程可以使用这两个分区,但可能发生的情况是,Thread1使用AAAA和Thread2使用BBBB,并且BBBB的进程在进程AAAA完成之前就完成了。
@KafkaListener(topics = "${kafka.topic}", groupId = "${kafka.groupid}", containerFactory = "kafkaListenerContainerFactory")
public void consumeJson(String mensaje,
@Header(KafkaHeaders.RECEIVED_PARTITION_ID) String partitionID) throws InterruptedException {
logger.info("-> Consumed JSon message");
logger.info("-> Read from partition:" + partitionID);
logger.info("-> Consumed JSON Message: [" + mensaje.toString()+"]");
}
java的代码:
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> config = new HashMap<>();
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapAddress);
config.put(ConsumerConfig.GROUP_ID_CONFIG, groupid);
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, maxPoll);
// Commit manual (para poner AckMode.BATCH), por configuración
config.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, autoCommit);
return new DefaultKafkaConsumerFactory<>(config);
}
@Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String,String>> kafkaListenerContainerFactory(){
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<String, String>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(5);
// Commit the offset when the listener returns after processing the record.
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.BATCH);
return factory;
}
当我运行springboot应用程序并看到日志时,它看起来就像是完成了一个线程/分区关系,就像是创建了一个使用者/分区一样。每个线程只消耗来自一个分区的数据!Thread0->Partition0、Thread1->Partition1、Thread2->Partition2、Thread3->Partition3、Thread4->Partition4。我已经检查了日志行的数组,它总是匹配的。
日志的一小部分:
[org.springframework.kafka.kafkalistenerEndpointContainer#0-0-C-1][9980][E.E.S.L.KafkaConsumer:][][]从分区读取的已消费JSon消息0
[org.springframework.kafka.kafkalistenerEndpointContainer#0-4-C-1][9980][E.E.S.L.Kafkaconsumer:][][]从分区读取的已消费的JSon消息4
[org.springframework.kafka.kafkalistenerEndpointContainer#0-2-C-1][9980][E.E.S.L.KafkaConsumer:][][]从分区读取的已消费JSon消息2
[org.springframework.kafka.kafkalistenerEndpointContainer#0-1-C-1][9980][E.E.S.L.KafkaConsumer:][][]从分区读取的已消费JSon消息1
这对我来说没有意义。正如文档所说:
具有多个线程的使用者:如果处理一条记录需要一段时间,单个使用者可以运行多个线程来处理记录,但是很难管理每个线程/任务的偏移量。如果一个使用者运行多个线程,那么同一分区上的两个消息可能由两个不同的线程处理,这使得在没有复杂线程协调的情况下很难保证记录传递顺序。如果处理单个任务需要很长时间,则此设置可能是合适的,但请尽量避免。
谢谢!
共有1个答案

您永远不应该执行异步处理;使用5个消费者,每个消费者得到一个分区,是正确的方法,也是保证有序处理的唯一方法。
使用来自单个使用者的多个线程会导致偏移量管理方面的问题。
将并发设置为5将创建5个使用者。
-
问题内容: 我最近一直在与Kafka一起工作,对某个消费群体下的消费者有些困惑。混淆的中心是将使用者实现为进程还是线程。对于这个问题,假设我正在使用高级消费者。 让我们考虑一个我尝试过的场景。在我的主题中,有2个分区(为简单起见,我们假设复制因子仅为1)。我创建了一个消费者()过程与组,然后创建尺寸2的主题计数地图,然后产生了2个消费者线程和该过程下。看起来好像正在消耗分区,而且正在消耗分区。这种
-
我使用flink和Kafka创建了一个流媒体程序,用于流媒体mongodb oplog。根据与Flink支持团队的讨论,流的顺序不能通过kafka分区来保证。我已经创建了N个kafka分区,并希望每个分区创建N个flink kafka消费者,所以流的顺序应该至少在特定的分区中保持。请建议我是否可以创建分区特定的flink kafka消费者? 我正在使用env.setParallelism(N)进行
-
现在,让我们考虑另一个场景(我没有尝试过,但我很好奇),在这个场景中,我启动了两个使用者进程和,这两个进程都具有相同的组,并且它们都是一个单线程进程。现在我的问题是: > 在这种情况下,两个独立的使用者进程(在同一个组下)将如何与分区相关?与上面的单进程多线程场景有何不同? 一般来说,使用者线程或进程如何与主题中的分区映射/相关? 关于将消费者实现为进程与线程,我在这里遗漏了什么微妙的事情吗?提前
-
我的消费者并不是每次都能收到信息。我有3个代理(3个服务器)的Kafka集群,有3个主题和复制因子3的分区。 我有Java中的消费者,我将最大轮询记录设置在50000获取字节上,配置在50MB上。应用程序每分钟都进行轮询。当我向主题“my-topic”发送10条消息时,consumer不会给我所有的消息,而是只给我其中的一部分,其余的将在下一次运行中给我。消息是在applicatin睡眠期间由脚本
-
我们正在使用Spring kafka来消费消息。我们已经为每个分区创建了接收消息的接收器。现在我们需要多个接收者从单个分区接收消息。 对于例如。假设我们有一个分区0。目前,我们只有一个接收器(接收器1)从这个分区接收消息。现在我想为同一个分区(分区0)添加另一个接收器(接收器2)。 因此,如果生产者向这个分区发送100条消息,接收器1应该接收50条消息,其余50条消息应该在接收器2中接收。我不希望
-
我使用的是Kafka流,具有无状态的简单处理器拓扑结构。 我有一个主题,有100个分区,有2台机器,每台机器有50个线程,运行同一个流媒体应用程序,因此最终我将在它们之间进行1-1映射。 主题中的消息已是键控消息。 我有一个逻辑约束,一旦线程连接到一个或多个分区,它应该继续处理这些分区(当然,直到重新启动发生,它会重新洗牌) 我从日志中看到线程反复(重新)加入消费者组。 我的问题,kafka 流