《flink》专题
-
Apache Flink:如何处理水印背后的所有事件?
我想使用Flink的事件时间戳,并计划实现一个简单的emitWatermark,即系统。currentTimeInMillis-10秒。我的理解是,翻滚窗口将触发start\u time window\u间隔10秒。因此,如果事件晚于水印到达,则会删除这些事件。 有没有办法将Flink丢弃的所有事件写入S3这样的接收器?
-
空闲源计时器上的Flink Keyedprocess函数
我有一个听Kafka的Flink过程。然后,将消耗的消息保存在并发哈希映射中一段时间,然后需要将其放入cassandra。 操作员链类似于 在使用EventTime时,我有一些疑问 消息将具有唯一的id、时间戳和其他一些属性。一分钟内可能有一百万个唯一的钥匙。keyBy操作会影响性能吗 我需要涵盖以下场景 > ID为1的X消息在8小时1分1秒到达 ID为2的Y消息在8小时1分4秒到达 由于我使用I
-
Flink Kafka:在没有收到消息的时间间隔后,优雅地关闭Flink消费来自Kafka源的消息
我已将flinkkafkaconsumer作为源添加到我的streamexecutionenvironment中。我想在特定时间内没有收到新消息时关闭/阻止flink使用数据(类似于kafka polltime)。目前它正在无限期运行,并阻止执行移动到下一步(验证消息)。请建议是否有任何解决方法。 注意:我从反序列化中尝试了endofstream,但它无法工作,因为流实际上是不确定的。 提前谢谢。
-
使用Kafka作为EventStore时恢复Flink中的状态一致性
我将微服务实现为事件源聚合,而事件源聚合又被实现为Flink FlatMapFunction。在基本设置中,聚合从两个kafka主题读取事件和命令。然后,它将新事件写入第一个主题并处理第三个主题的结果。因此,Kafka充当事件存储。希望这张图能有所帮助: 由于Kafka没有选中点,因此命令可能会被重放两次,而且输出事件似乎也可以在主题中写入两次。 在重复消息的情况下如何恢复状态?聚合是否可以知道其
-
Apache Flink中带有TumblingWindow的水印
我试图了解Apache FLink中Windows和Watermark生成之间的依赖关系,我在下面的示例中出现错误: 这里的时间戳是一个长的,我们可以从Kafka源中检索到,应该是:a,4 C,8,其中C是类别,5是时间戳。 每当我发送事件时,数据流都会打印,但不会使用窗口打印这些事件(打印(“Windows”)。此外,如果我收到一个事件A,12,然后生成了一个水印(在10秒内),那么我有C,2,
-
Flink水印根本没有前进?卡在-9223372036854775808
我遇到了与Flink EventTime处理水印类似的问题-9223372036854725808。然而,建议的解决方案(设置并行度和禁用检查点)没有任何效果。在本例中,我只是将1000个事件以1秒的间隔流式传输,然后将事件时间戳与ctx进行比较。timerService()。currentWatermark()
-
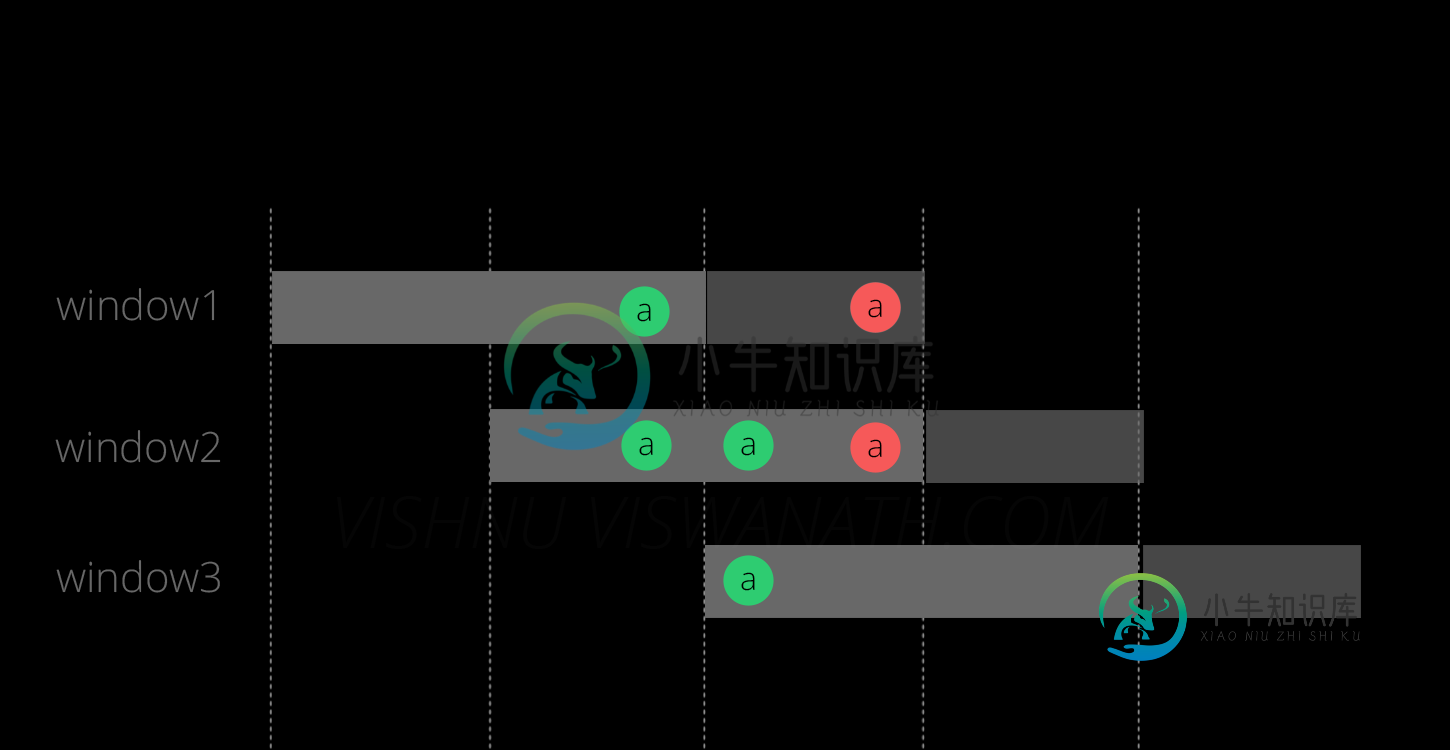 Flink了解后期事件vs watermark
Flink了解后期事件vs watermark看看这篇关于水印的文章 在那篇文章的后面,它解释了当设置允许迟到时: Flink不会丢弃邮件,除非它超过了window\u end\u允许的延迟时间 由于设置了允许的延迟,是否实际导致了对窗口的延迟评估? 那么水印和允许迟到的用法到底有什么不同呢?什么时候使用哪个?
-
Flink如何设置初始水印
我正在使用Flink 1.3.2和scala构建一个流媒体应用程序,我的Flink应用程序将监视一个文件夹,并将新文件流到管道中。文件中的每条记录都有一个相关的时间戳。我想使用此时间戳作为事件时间,并使用AssignerWithPeriodicWatermarks构建水印,我的水印生成器如下所示: 但是,由于我的文件夹中有一些旧数据,我不想处理它们。旧文件中记录的时间戳是
-
Flink:带有后期元素的水印
我在Flink中做实时流,其中Kafka是消息队列。我正在应用120秒的EventTimeSlidingWindow。和1秒的幻灯片。我还在事件时间的每秒插入水印。 我担心的是,如果元素在水印之后延迟出现,会发生什么?现在,我的情况是,Flink简单地丢弃了相应水印之后的消息。filnk是否提供了任何机制来处理此类延迟消息,例如维护单独的窗口?我也看过了文档,但我没有弄清楚。
-
Flink窗口函数getResult未触发
我正在尝试在我的Flink作业中使用事件时间,并使用来提取时间戳并生成水印。但是我有一些输入Kafka具有稀疏流,它可以长时间没有数据,这使得中的根本没有调用。我可以看到数据进入函数。 我已经设置了getEnv()。getConfig()。设置自动水印间隔(1000L) 我尝试过 还有会话窗口 所有的水印都显示没有水印,我怎么能让Flink忽略这个没有水印的东西呢?
-
Apache Flink翻滚窗口延迟结果
使用翻滚窗口的apache flink应用程序遇到问题。窗口大小是10秒,我希望每隔10秒有一个resultSet数据流。然而,当最新窗口的结果集总是延迟时,除非我将更多数据推送到源流。 例如,如果我在“01:33:40.0”和“01:34:00.0”之间将多条记录推送到源流,然后停止查看日志,则不会发生任何事情。 我在“01:37:XX”上再次推送一些数据,然后将在“01:33:40.0”和“0
-
Apache Flink翻滚窗口时间偏移与表API或SQL
任何人都知道如何使用时间偏移进行翻滚窗口-窗口大小为一天,时间偏移基于时区以小时为单位。 我找到了使用DataStream API执行此操作的示例,想知道如何使用Table API/SQL实现它。 下面是我使用DataStream API的代码。 提前谢谢。
-
Flink翻滚窗口标签
我有一个使用flink应用程序的场景,该应用程序接收以下格式的数据流: {“event\u id”:“c1s2s34”,“event\u create\u timestamp”:“2019-03-07 11:11:23”,“amount”:“104.67”} 我使用下面的滚动窗口来查找过去60秒内输入流的总和、计数和平均值。 键值。时间窗口(时间秒(60)) 然而,我如何标记聚合结果,以便我可以说
-
Flink流窗口内存使用情况
我正在评估Flink是否支持流媒体窗口以生成可能的警报。我关心的是内存使用情况,如果有人能帮我,我将不胜感激。 例如,该应用程序将在给定的滚动窗口(例如5分钟)内消耗流中潜在的大量数据。在评估时,如果例如有一百万个文档符合标准,它们会全部加载到内存中吗? 一般流程为: <代码>制作人- 此外,如果有一些清晰的文档描述了在这些情况下如何处理内存,那么我可能忽略了有人可能会指出这一点,这将很有帮助。
-
在Apache Flink中的多个窗口运算符中处理过去的数据?
上下文:我正在研究的项目处理定期(1分钟)生成的时间戳文件,并将其实时摄取到一系列级联窗口操作符中。文件的时间戳指示事件时间,因此我不需要依赖文件创建时间。每个窗口的处理结果被发送到一个接收器,该接收器将数据存储在多个表中。 我正在尝试想出一个解决方案来处理实时进程可能出现的停机时间。输入文件是独立生成的,因此在Flink解决方案严重停机的情况下,我想摄取和处理丢失的文件,就好像它们是由同一进程摄