《flink》专题
-
Flink进程中的TimerException
我们正在使用几个操作符运行Flink作业,包括map、windowing、flatMap(),作业失败,出现以下错误-只是想知道是什么原因导致此错误:
-
Flink中的收集器。它是做什么的?
我正在学习Flink,其中一件令我困惑的事情是使用一个名为Collector的对象。例如在平面图函数中。这个Collector和它的方法收集了什么?以及为什么例如map函数不需要通过显式使用它来传递结果? 这里可以看到在flatmap函数中使用收集器的一些示例:https://www.programcreek.com/scala/org.apache.flink.util.Collector 此外
-
Flink,一个插槽可以有多个线程还是只有一个线程?
在Flink中,像“平面地图”、“地图”等运算符称为任务,如果我将平面地图的并行度设置为30,那么这个任务有30个子任务。 现在,如果我只有一个插槽,它会在一个插槽中产生多个线程吗?还是每个插槽只有一个线程? Flink会在该插槽中简单地创建30个线程,还是使用类似线程池的东西? 以上不是一个恰当的例子。 假设在作业中我有操作符flatMap和map,它们都有并行度1,我只有一个插槽,这个插槽会创
-
在flatMap中使用Flink Table API获取序列化异常
我试图通过将flink env对象传递给flatMap对象来使用flatMap中的表api。但我遇到了序列化异常,这表明我添加了一些无法序列化的字段。 你能解释一下吗? 你好Sajeev
-
Apache Flink:SpiltStream与侧输出
从这个问题中,我了解到Apache Flink中的SplitStream现在已被弃用,建议改用side输出。有人能举一个侧面输出如何替代splitStream的例子吗? e、 g.如何修改下面的代码段以使用侧输出?
-
Apache Flink-数据集api-端输出
Flink是否支持数据集中的侧输出功能(批处理Api)?如果没有,从文件加载时如何处理有效和无效记录?
-
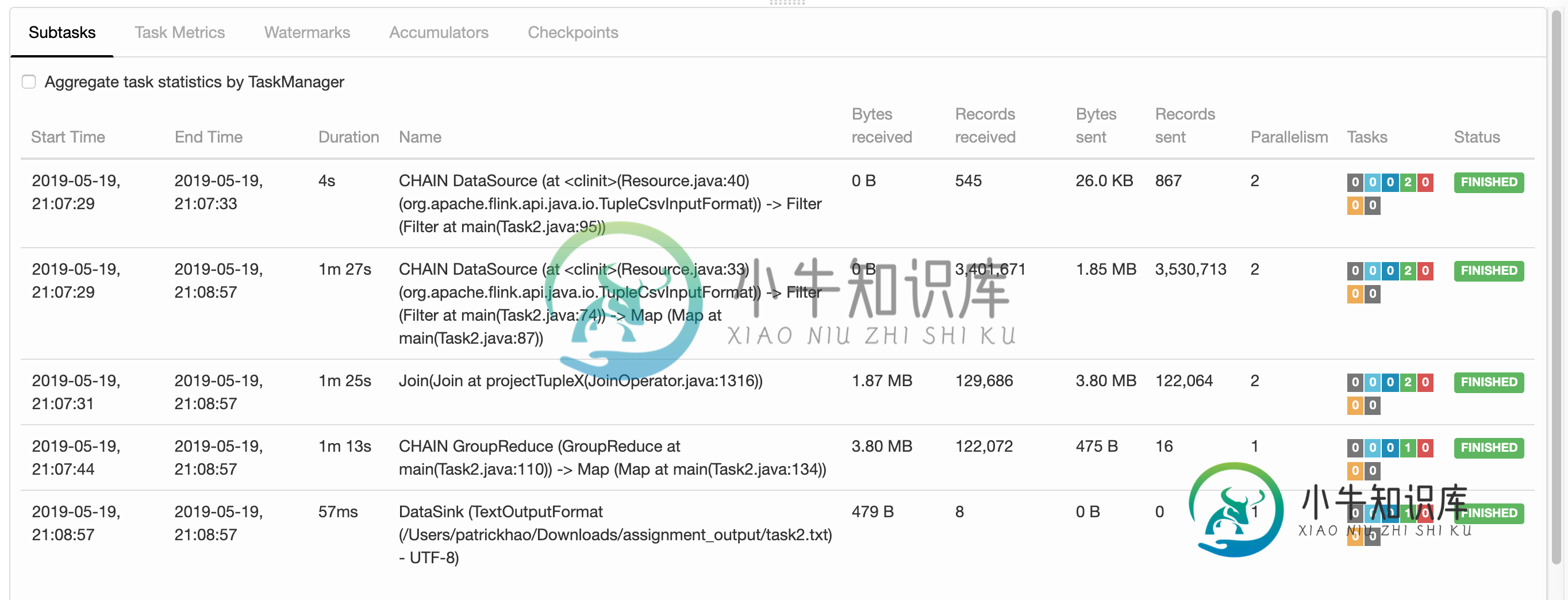 了解Apache Flink仪表板的输出
了解Apache Flink仪表板的输出我试图理解Apache Flink仪表板显示的“接收/发送的字节”是什么意思。在某些情况下,CSV文件托管在HDFS服务器上,我正在将结果写入机器上本地的TXT文件中。Flink也在我的机器上本地运行。考虑到这一点,“发送的字节”似乎是指“从HDFS服务器发送到我的机器的字节”,“接收的字节”似乎是指“从我的机器发送到HDFS服务器的字节”。这是正确的解释吗? 时间线显示的重叠任务也让我有点困惑。
-
如何在Apache Flink中的GroupedDataSet上平面映射函数
我想通过flatMap向数据集生成的每个组应用一个函数。groupBy(分组依据)。尝试调用flatMap时,我发现编译器错误: 我的代码: 事实上,在flink-0.9-SNAPSHOT的留档中没有列出或类似的。是否有类似的方法可以使用?如何在节点上单独实现每个组的所需分布式映射?
-
来自kafka的Flink消耗消息scala不能平面图
我试图遵循示例:https://blog.knoldus.com/a-quick-demo-kafka-to-flink-to-cassandra/我试图从kafka解析我的Shippingorder JSON消息并将其解析为对象。然后按一些属性对其进行分组,但在平面图步骤时出现错误。 我的sbt文件: 我的主文件。 我的订单对象 运行此作业时出错 我不知道这个错误。请解释并帮助我解决这个问题。
-
Apache Flink中的不可序列化对象
我正在使用Apache Flink对流数据执行分析。 我正在使用一个依赖项,其对象需要超过10秒才能创建,因为它在初始化之前读取hdfs中存在的几个文件。 如果我在open方法中初始化对象,我会得到一个超时异常,如果在接收器/平面图的构造函数中,我会得到序列化异常。 目前,我正在使用静态块来初始化其他类中的对象,使用前提条件。在主文件中选中NOTNULL(mgGenerator.mgGenerat
-
Apache Zeppelin升级至Flink 1.4.2
我尝试升级Apache Zeppelin以使用Flink 1.4.2。检查Flink Zeppelin解释器的源代码时,我没有发现任何从Flink版本的角度来看似乎是材料的东西,所以我只是将pom文件中的Flink verion更新为1.4.2,并从源代码运行了一个新的构建,令人惊讶地工作。运行Flink batch示例笔记本(或我自己的流媒体示例),我发现以下错误,我无法正确理解 如果能了解我们
-
Apache Flink错误处理和条件处理
我是Flink的新手,已经通过网站/示例/博客开始学习。我正在努力正确使用操作符。基本上我有两个问题 问题1:Flink是否支持声明性异常处理,我需要处理解析/验证/。。。错误? 我可以使用组织吗。阿帕奇。Flink。运行时。操作员。分类ExceptionHandler或类似的程序来处理错误 还是Rich/FlatMap功能是我的最佳选择?如果Rich/FlatMap是唯一的选项,那么是否有办法在
-
flink-将值注入flatmap
情况:多个相同的Kafka数据源被平面映射到元组中,以便以后进行联合、缩减、保存等等。 我需要知道每个平面映射数据包来自哪个原始数据源,以标记元组中的标签。我不希望每个数据源都有单独的FlatMapFunction,因为可能有数百个。 理想情况下,我能够将一些值传递到flatmap函数中,以添加到结果元组中。 可能的还有其他的方法来实现这一点吗?
-
Apache Flink DataStream API没有映射分区转换
Spark DStream有mapPartition API,而Flink DataStream API没有。是否有人可以帮助解释原因。我想做的是在Flink上实现一个类似于Spark的API。
-
是“流”。addSink(新的PrintSinkFunction())`和`流。print()`在Flink中也是一样
我已经看到了这两个流。addSink(新的PrintSinkFunction 基于https://github.com/apache/flink/blob/b2a342c6a6ef154ed3c1a44826ce2be14e538386/flink-streaming-java/src/main/java/org/apache/flink/streaming/api/datastream/Data