《flink》专题
-
是否可以在Kubernetes中运行一个具有高可用性、检查点和保存点的单容器Flink集群?
我目前正在运行一个Flink会话集群(库伯内特斯、1个JobManager、1个TaskManager、ZooManager、S3),其中运行多个作业。 由于我们正在努力添加更多作业,我们正在寻求改进我们的部署和集群管理策略。我们正在考虑迁移到使用作业集群,但是对将产生的容器数量有保留。每个作业一个容器不是问题,但是每个作业两个容器(1个JM和1个TM)会引起内存消耗问题。一些作业需要高可用性以及
-
库伯内特斯的Flink。如何将提交作业步骤添加到jobmanager flink docker?
我使用Flink搭配K8s。一切正常,但我必须在jobmanager启动时手动提交jar。 我认为我们可以扩展flink的形象,并添加提交作业的后期操作。所以jobmanager将是一对一的flink工作。我想这是https://www.youtube.com/watch?v=w721NI-mtAA公司 在这种情况下,如果JM关闭,K8s将启动新的pod并重新提交作业。 我没说错吧? 有没有人对F
-
无法更新Flink Native Kubernetes中的logback配置
我已经创建了一个Flink原生Kubernetes(1.14.2)集群,这是成功的。我正在尝试更新使用Flink Native Kubernetes公开的configmap的logback配置。Flink Native Kubernetes在集群启动期间创建此configmap,在集群停止时将其删除,此行为符合官方文档。 我更新了同样成功的回退配置图,这个过程甚至更新了作业管理器和任务管理器中的实
-
无法在独立kubernetes-flink部署(会话模式)上通过gui提交新作业
在独立kubernetes模式(会话集群)中部署flink后,我无法使用flink GUI上载任何新作业。单击添加新按钮并选择jar文件后,进度带结束,什么也没有发生。作业管理器日志中没有关于此的信息/错误。当我尝试上载任何文件(如文本文件)时,我收到一个错误,日志中有一个信息: 我还尝试上传假的jar(一个名为.jar的空文件),它可以工作——我可以上传这种文件。 我有一个全新的、干净的Apac
-
为Flink集群中的插件添加自定义依赖项
我有一个Flink会话集群(作业管理器任务管理器),版本1.11.1,配置了log4j控制台。属性包括Kafka appender。此外,在作业管理器和任务管理器中,我都启用了flink-s3-fs-hadoop内置插件。 我已经将kafka客户端jar添加到flink/lib目录,这是容器运行所必需的。但在实例化S3插件(并初始化记录器)时,我仍然会遇到类下加载错误。 原因:org.apache
-
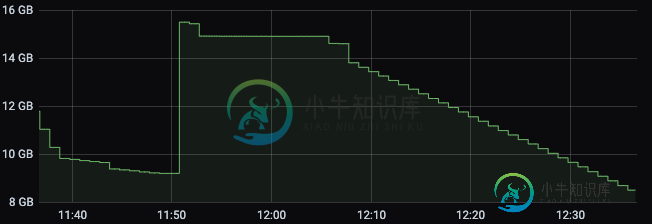 运行Apache Flink作业时K8s群集内存减少
运行Apache Flink作业时K8s群集内存减少我们正在尝试在K8s集群上部署apache Flink作业,但我们注意到一个奇怪的行为,当我们开始我们的作业时,任务管理器内存以分配的数量开始,在我们的例子中是3 GB。 最终,内存开始减少,直到达到约160 MB,此时,它会恢复一点内存,所以不会达到其极限。 这种非常低的内存通常会导致作业因任务管理器心跳异常而终止,即使在尝试查看Flink仪表板上的日志或执行作业流程时也是如此。 为什么它的内存
-
Flink作业集群与会话集群-部署和配置
我正在研究Flink 1.9.1的docker/k8s部署可能性。 我看完了[1][2][3][4]。 目前,我们确实认为,我们将尝试采用工作集群方法,尽管我们想知道社区的这一趋势是什么?我们不希望每个Flink集群部署多个作业。 不管怎样,我想知道一些事情: > 在这两种情况下,Flink的UI都显示每个任务管理器有4个CPU。 如果使用作业群集,如何重新提交作业。我指的是这个用例。你可能会说我
-
Flink工作部署在库伯内特斯
我正在尝试在Kubernetes集群(Azure AKS)中部署Flink作业。作业群集在启动后立即中止,但任务管理器运行正常。 docker镜像创建成功,没有任何异常。我可以运行docker镜像,也可以SSHdocker镜像。 我已经按照以下链接中提到的步骤: https://github.com/apache/flink/tree/release-1.9/flink-container/kub
-
Windows上的Apache Flink
首先,我是Flink的新手。我已经在Windows上安装了Apache Flink。我开始使用Flinkstart-cluster.bat.它打印出来 使用一个JobManager进程和一个TaskManager进程启动本地群集。您可以在派生的shell窗口中通过CTRL-C终止进程。Web界面默认打开http://localhost:8081/. 无论如何,当我提交这份工作时,我有一大堆信息:
-
Kubernetes上的Flink
我们正在使用构建流处理作业,并计划在库伯内特斯集群上运行它。在参考官方Flink留档时,我们主要遇到了两种将Flink作业提交到库伯内特斯集群的方法,一种是模式,另一种是模式。我们注意到使用后一种选项,没有yaml配置文件,看起来很简单。只是想知道推荐的模式/方法是什么以及它们的优缺点。谢谢。
-
Flink streaming,如何计数?
我遇到了一个用流处理扩展Klaviyo事件处理管道的帖子,在帖子中,Klaviyo公司的人在不同的时间段,每小时、每天甚至每月进行计数。 我有几个问题,如果我理解正确的话,他们使用的是时间窗口,但是使用时间窗口这么长时间,比如一天,正常吗?! 这对我来说没有意义,如果你每天或每月都在盘点,为什么不使用批处理呢?在这种情况下使用流媒体的基本好处是什么? 另一种情况是,如果我需要从一开始就实时计算Ka
-
Flink kafka使用者从特定分区获取消息
我们希望在读取消息表单kafka时实现并行性。因此我们想在flinkkafkaconsumer中指定分区号。它将从kafka中的所有分区读取消息,而不是特定的分区号。以下是示例代码: 请建议任何更好的选择来获得并行性。
-
Flink在《Kafka》中克服坏消息:“毒药消息”
我第一次试着让它工作,所以请容忍我。我正在尝试学习Kafka的检查点设置和处理“错误”消息,在不丢失状态的情况下重新启动。 用例:使用检查点。从Kafka那里读取一个整数流,保持一个连续的和。如果读到“坏”Kafka消息,请重新启动应用程序,跳过“坏”消息,保持状态。我的流看起来像这样: set1,5 set1,7 set1,foobar set1,6 我希望我的应用程序保留它看到的整数的运行总和
-
Flink如何使用具有多个分区的Kafka主题中的消息,而不会产生扭曲?
假设一个主题有3个kafka分区,我希望我的事件按小时窗口,使用事件时间。 当某个分区位于当前窗口之外时,kafka使用者是否会停止读取该分区?还是打开一个新窗口?如果它正在打开新的窗口,那么,如果一个分区的事件时间与其他分区相比会非常倾斜,那么从理论上讲,它不可能打开无限数量的窗口,从而耗尽内存吗?当我们重播一些历史时,这种情况尤其可能发生。 我一直试图从阅读留档中得到这个答案,但是在分区上找不
-
使用Apache Flink执行计划任务
我在parallelism 5上有一份flink的工作(目前!!)。其中一个richFlatMap流在打开(配置参数)方法中打开一个文件。在flatMap操作中,没有任何打开操作,它只是读取文件来搜索某些内容。(有一个实用程序类,它的方法类似于utilityClass.searchText(“abc”))。以下是样板代码: python脚本每天都会在特定时间更新此文件。因此,我还应该在flatMa