《聚类》专题
-
Python实现Kmeans聚类算法
本文向大家介绍Python实现Kmeans聚类算法,包括了Python实现Kmeans聚类算法的使用技巧和注意事项,需要的朋友参考一下 本节内容:本节内容是根据上学期所上的模式识别课程的作业整理而来,第一道题目是Kmeans聚类算法,数据集是Iris(鸢尾花的数据集),分类数k是3,数据维数是4。 关于聚类 聚类算法是这样的一种算法:给定样本数据Sample,要求将样本Sample中相似的
-
cassandra划分和聚类密钥
是否可以将列作为分区和聚类键?例如, 创建表citylist2(城市varchar,loc list,pop int,zip varchar,state varchar,primary key(city,city,zip)),使用集群顺序BY(城市ASC,zip DESC);
-
机器学习:聚类分析
监督学习使用标记数据对 (x,y) 学习函数:X\rightarrow Y 。但是,如果我们没有标签呢?这类没有标签的学习方式被称为无监督学习。 无监督学习:如果训练样本全部无标签,则是无监督学习。例如聚类算法,就是根据样本间的相似性对样本集进行聚类试图使类内差距最小化,类间差距最大化。 主要用途: 自动组织数据。 理解某些数据中的隐藏结构。 在低维空间中表示高维数据。
-
8.3.2 OpenCV中的K-Means聚类
目标 学习在 OpenCV 中使用 cv2.kmeans() 函数进行数据聚类 了解参数 输入参数 samples:应该是 np.float32 数据类型,每个特征应放在一个单独的列中。 nclusters(K):结束时所需的集群数量 criteria:这是迭代终止标准。当满足这个标准时,算法迭代停止。其实它应该是一个3个参数的元组。他们是(type,max_iter,epsilon): type
-
用 scikit-learn 做聚类分析
K-means k是一个超参数,表示要聚类成多少类。K-means计算方法是重复移动类的重心,以实现成本函数最小化,成本函数为: 其中μk是第k类的重心位置 试验 构造一些样本用户试验,如下: # coding:utf-8 import sys reload(sys) sys.setdefaultencoding( "utf-8" ) import matplotlib.pyplot as pl
-
Chameleon 两阶段聚类算法
参考文献:http://www.cnblogs.com/zhangchaoyang/articles/2182752.html(用了很多的图和思想) 博客园(华夏35度) 作者:Orisun 数据挖掘算法-Chameleon算法.百度文库 我的算法库:https://github.com/linyiqun/lyq-algorithms-lib(里面可能有你正想要的算法) 算法介绍 本篇文章讲述的还
-
8.5 理解K均值聚类
目标 在本章中,我们将了解K-Means聚类的概念,其工作原理等。 理论 我们将用一个常用的例子来处理这个问题。 T-shirt尺寸问题 考虑一家公司,该公司将向市场发布新型号的T恤。显然,他们将不得不制造不同尺寸的模型,以满足各种规模的人们的需求。因此,该公司会记录人们的身高和体重数据,并将其绘制到图形上,如下所示: 公司无法制作所有尺寸的T恤。取而代之的是,他们将人划分为小,中和大,并仅制造这
-
ElasticSearch聚合:每个聚合排除一个过滤器
问题内容: 我想过滤出字段“ A”等于“ a”的文档,并且我想同时考虑字段“ A”,当然不包括先前的过滤器。我知道您可以将过滤器“置于查询之外”,以便在不应用该过滤器的情况下获得构面,例如: elasticsearch 单反 这非常好,但是如果我有多个滤镜和构面,每个滤镜和构面应该互相排斥,会发生什么?例: 也就是说,对于方面AI,希望保留除A:a以外的所有过滤器,对于方面B希望保留除B:b以外的
-
ElasticSearch在另一个聚合结果上使用聚合
问题内容: 有一个对话列表,每个对话都有一个消息列表。每个消息都有一个不同的字段和一个字段。我们需要考虑的是,在对话的第一条消息中使用了动作,在几条消息中使用了动作之后,过了一会儿,依此类推(有一个聊天机器人意图列表)。 将对话的消息动作分组将类似于: 问题: 我需要使用ElasticSearch创建一个报告,该报告将返回每次会话的;接下来,我需要对类似的东西进行分组并添加一个计数;最终将导致as
-
Apache Flink-每小时聚合数据的每日聚合
我有一个窗口化的每小时聚合的数据流。 Datastreamds=.....
-
ElasticSearch聚合:每个聚合排除一个筛选器
我想过滤掉字段'a'等于'a'的文档,同时我想对字段'a'进行刻面处理,当然不包括前面的过滤器。我知道您可以将筛选器放在查询的“外部”,以便在不应用该筛选器的情况下获得方面,例如: 弹性搜索 索尔尔 也就是说,对于方面A,我希望保留除A:A以外的所有过滤器,对于方面B,我希望保留除B:B以外的所有过滤器,以此类推。最明显的方法是执行n个查询(n个方面中的每一个),但我不想这样做。
-
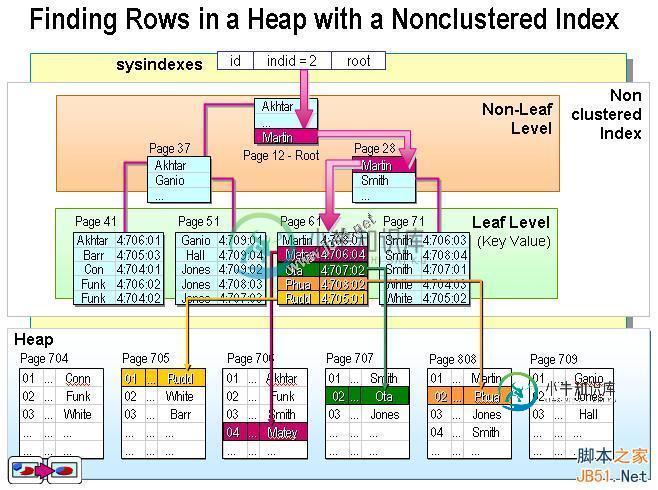 sql 聚集索引和非聚集索引(详细整理)
sql 聚集索引和非聚集索引(详细整理)本文向大家介绍sql 聚集索引和非聚集索引(详细整理),包括了sql 聚集索引和非聚集索引(详细整理)的使用技巧和注意事项,需要的朋友参考一下 聚集索引 一种索引,该索引中键值的逻辑顺序决定了表中相应行的物理顺序。 聚集索引确定表中数据的物理顺序。聚集索引类似于电话簿,后者按姓氏排列数据。由于聚集索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚集索引。但该索引可以包含多个列(组合索
-
应用聚合后过滤elasticsearch中的术语聚合桶
以下是数据集的快照: 我想获得员工名单以及employeeStatus和employeeAddr。 所以我在employeeId上使用术语聚合,然后使用employeeStatus和employeeAddr的子聚合来获得这些详细信息。下面的查询正确返回结果。 现在我只想要永久身份的员工。所以我正在应用过滤器聚合。 现在的问题是雇员地址聚合没有为雇员地址返回存储桶,因为记录2在聚合完成之前就被过滤掉
-
获取最大术语桶聚合(使用管道聚合)
我想知道如何在Elasticsearch中使用聚合时获得具有最高doc_count的存储桶。我正在使用Kibana示例数据kibana_sample_data_flights: 如果有一个存储桶具有最大文档计数,我可以将术语聚合的大小设置为1,但是如果有两个存储桶具有相同的最大文档计数,则这不起作用。 自从我涉足管道聚合以来,我觉得应该有一种简单的方法来实现这一点。最大桶聚合似乎能够处理多个最大桶
-
什么是K-means聚类算法
主要内容:聚类和分类的区别,找相似,簇是什么,理解K的含义,如何量化“相似”,总结机器学习算法主要分为两大类:有监督学习和无监督学习,它们在算法思想上存在本质的区别。 有监督学习,主要对有标签的数据集(即有“参考答案”)去构建机器学习模型,但在实际的生产环境中,其实大量数据是处于没有被标注的状态,这时因为“贴标签”的工作需要耗费大量的人力,如果数据量巨大,或者调研难度大的话,生产出一份有标签的数据集是非常困难的。再者就算是使用人工来标注,标注的速度也会比数据生产的速度慢的多。因