《聚类》专题
-
ElasticSearch-按嵌套字段上的嵌套聚合排序聚合
在这里,我得到了错误: “无效的术语聚合顺序路径[price>price>price.max]。术语桶只能在子聚合器路径上排序,该路径由路径中的零个或多个单桶聚合和路径末尾的最终单桶或度量聚合组成。子路径[price]指向非单桶聚合” 如果我按持续时间聚合排序,查询可以正常工作,如 那么,有什么方法可以通过嵌套字段上的嵌套聚合来排序聚合吗?
-
Apache Camel拆分和聚合丢失聚合交换的结果
我试图在使用RESTendpoint的骆驼路由中构建一个分割/聚合模式。它需要一个包含请求详细信息列表的请求对象。我想并行处理请求详细信息,然后将聚合结果返回给调用方。我希望这是一个同步调用。 这是我的路线中的代码。 我希望调用的结果是聚合调用(我的响应对象)的输出。但我实际上得到的是REST调用返回的请求对象?? 当我放入更多的日志语句时,我可以看到Split调用正在触发多个线程,这很好。我可以
-
深度嵌套类型的Elasticsearch聚合
问题内容: 示例文档中有一个简化的文档。这对我理解非嵌套类型与嵌套类型的聚合差异很有帮助。但是,这种简化掩盖了进一步的复杂性,因此我不得不在这里扩展这个问题。 所以我的实际文件更接近以下内容: 因此,我保留了,和的关键属性,但隐藏了许多其他使情况复杂化的内容。首先,请注意,与引用的问题相比,有很多额外的嵌套:在根和“项目”之间,以及在“项目”和“ item_property_1”之间。此外,还请注
-
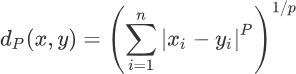 K-means聚类算法原理解析
K-means聚类算法原理解析主要内容:度量最小距离,总结通过《 什么是Kmeans聚类算法》一节的学习,我们了解了 K-means 聚类算法的聚类过程,其实就是不断寻找簇的质心的过程,该过程从随机设定 K 个质心开始,直到找到 K 个最合适的质心为止。本节我们透过算法流程直击算法的本质,帮助您彻底理解 K-means 算法。 度量最小距离 对于 K-means 聚类算法而言,找到质心是一项既核心又重要的任务,找到质心才可以划分出距离质心最近样本点。从数
-
数组的Java类图组合/聚合
请考虑以下情况: 我如何在类图上表示< code>A和< code>B之间的关系?如果< code>B只保存一个< code>A(而不是一个数组),我会使用组合/聚合,但是在这种情况下,我不确定应该做什么。非常感谢你的帮助!
-
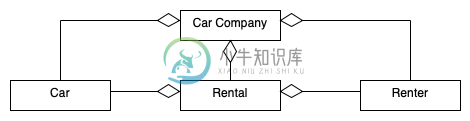 在类图中过度使用聚合?
在类图中过度使用聚合?我试图解决这个问题: 为汽车租赁公司绘制面向对象模型的UML类图,该模型跟踪汽车、租车人和租车人。创建一个UML类图来表示这些信息。显示正确的类和关系就足够了。不要向类添加属性或方法。 我在想租房者和汽车公司应该是协会,汽车公司和租房者应该是组合。然而,所提出的解决方案(此处简化)并不符合我的期望: 该解决方案将所有关系显示为聚合。有人能帮我理解为什么它们都是聚合的,而不是我认为的联想和组合吗?
-
同一类的Java组合和聚合?
假设我们有两个名为Point和Line的类。Line类有两个构造函数。这是Point类的代码。 这是Line类的代码。 如您所见,Line类有两个构造函数。第一个构造函数是组合的例子,而第二个构造函数是集合的例子。现在,关于这个案子我们能说些什么?一个类可以同时有聚合和合成吗?谢谢你的回答。
-
分类值上的elasticsearch排序聚合
在elasticsearch中,我可以在第二个聚合的数字字段上聚合和排序聚合。 例如。 但是,我想根据分类字段值对聚合进行排序。也就是说,字段2的值是(“a”、“b”、“c”)中的一个值——我想首先按所有文档对a1进行排序,字段2为:“a”,然后字段2为“b”,最后字段2为“c”。 在我的例子中,每个字段1都有一个唯一的字段2。所以我真的只想找到一种方法,按字段2对a1结果进行排序。
-
如何为聚类nifi设计模板
我们在设计nifi模板时是否需要考虑底层集群? 除了远程集群之外,负载均衡器的用例是什么?我可以使用负载均衡器将流量分割到几个处理器中以加速操作吗?
-
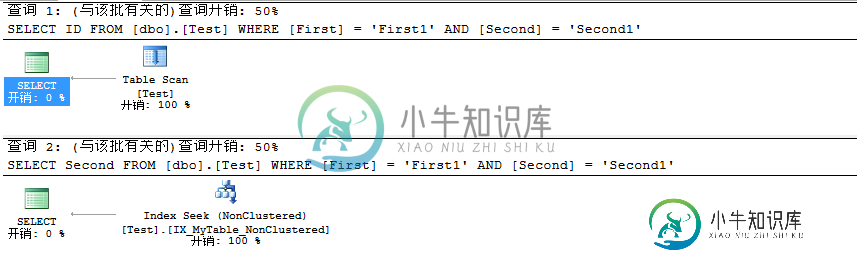 浅析SQL Server 聚焦索引对非聚集索引的影响
浅析SQL Server 聚焦索引对非聚集索引的影响本文向大家介绍浅析SQL Server 聚焦索引对非聚集索引的影响,包括了浅析SQL Server 聚焦索引对非聚集索引的影响的使用技巧和注意事项,需要的朋友参考一下 前言 在学习SQL 2012基础教程过程中会时不时穿插其他内容来进行讲解,相信看过SQL Server 2012 T-SQL基础教程的童鞋知道前面写的所有内容并非都是摘抄书上内容,如若是这样那将没有任何意义,学习的过程必须同时也是一
-
为什么XGrabKey会生成额外的聚焦和聚焦事件?
问题内容: 有谁知道xlib函数可以在不失去原始焦点的情况下捕获按键事件?如何摆脱它? (或“使用XGrabKey()而不生成Grab样式的聚焦”?) (或“如何在系统级别摆脱NotifyGrab和NotifyUngrab焦点事件?) XGrabKey将失去对按键的关注,而将精力恢复于释放的键。 而且我想捕获按键而不泄漏到原始窗口(就像XGrabKey可以做到的一样)。 参考文献: … XGrab
-
具有并行流的散点聚集(聚合器中的超时)
我一直在尝试在聚集中添加超时,以避免等待每个流都完成。但是当我添加超时时,它不起作用,因为聚合器等待每个流完成。 E、 在我的流中,其中一个有2秒的延迟,另一个有4秒的延迟 我使用遗嘱执行人。newCachedThreadPool()以并行运行。我想释放包含的每条消息,直到超时完成 我一直在测试的另一种方法是使用默认的gatherer,并在scatterGather中设置GathereTimeou
-
在“类内聚”或“类内聚”代码度量的上下文中,“抽象”是什么意思?
我在这个网站上讨论Eclipse中的代码度量时遇到了这个短语,特别是在讨论“缺乏内聚”的概念时: 内聚是面向对象编程中的一个重要概念。它指示类是表示单个抽象还是表示多个抽象。其思想是,如果一个类表示多个抽象,那么应该将其重构为多个类,每个类表示一个抽象。 在这种情况下,“单一抽象”是什么? 从封装和抽象的区别中,我得到抽象通常只是向用户展示必要的细节(通过使用接口和抽象类)。这里:什么是抽象?,我
-
对top_hits聚合的总和
问题内容: 简短的问题:如果我有每个存储区的top_hits的汇总,如何在结果结构中求和特定值? 细节: 我有许多记录,每个商店包含一定数量。我想获取每个商店的所有最新记录的总和。 为了获得每个商店的最新记录,我创建以下聚合: 假设我有两个商店,每个商店有两个数量用于两个不同的时间戳。这是该聚合的结果: 我现在想在ElasticSearch中进行汇总,以汇总这些存储桶中的总和。在示例数据中,总和超
-
分页Elasticsearch聚合结果
问题内容: 想象一下,我有两种记录:一个存储桶和一个项目,其中存储在存储桶中的项目,而存储桶中的项目可能相对较少(通常不超过4个,从不超过10个)。这些记录被压缩为一个(具有更多存储桶信息的项目),并放置在Elasticsearch中。我要解决的任务是通过依赖项属性的过滤查询一次找到500个存储桶(最大),其中包含所有相关项,而我受困于限制/抵消聚合。我该如何执行此类任务?我看到聚合使我可以控制相