
在类图中过度使用聚合?

我试图解决这个问题:
为汽车租赁公司绘制面向对象模型的UML类图,该模型跟踪汽车、租车人和租车人。创建一个UML类图来表示这些信息。显示正确的类和关系就足够了。不要向类添加属性或方法。
我在想租房者和汽车公司应该是协会,汽车公司和租房者应该是组合。然而,所提出的解决方案(此处简化)并不符合我的期望:
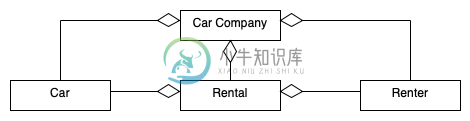
该解决方案将所有关系显示为聚合。有人能帮我理解为什么它们都是聚合的,而不是我认为的联想和组合吗?
共有1个答案

我在想,租车者和汽车公司应该是联合体
是的,这是有道理的:一个租车人可能是一家汽车公司的客户,反过来,一家汽车公司可以为几个租车人提供服务。租车人不是汽车公司所有,而是互惠的。
而租车公司和租车人应该是由租车人组成的。
否:组合意味着独占所有权,并且组合对象原则上不会在组合中生存。但在这里,如果一家汽车公司被摧毁,租车人可能会留下来,直接去其他汽车公司。所以没有作文。
解显示所有的关系是聚合的。
您描述的关系似乎与UML关联相对应。发布的解决方案使用聚合的事实不一定是错误的,但不建议使用:
>
从UML规范的角度来看,语义学没有明确定义。所以在设计模型中使用聚合没有真正的好处。请参见UML 2.5 p.110:
有时,一个属性用于建模环境,其中一个实例用于将一组实例组合在一起;这称为聚合
(…)共享聚合的精确语义因应用程序区域和建模者而异。
从设计者的角度来看,聚合是一种纯粹的概念符号,不会从根本上改变图的含义。为此,UML的创始人之一詹姆斯·伦巴夫曾将聚合称为“建模安慰剂”。我在《统一建模语言参考手册》第14章找到了引用:
请记住,聚合是关联。聚合传达了一种思想,即聚合本质上是其各部分的总和。事实上,它为关联添加的唯一真正语义是聚合链接链可能不会形成循环(…)的约束尽管聚合的语义很少,但每个人都认为它是必要的(出于不同的原因)。把它想象成一种模型安慰剂。
在实现方面,对象组合是OOP的基础之一。一些实践者和学者倾向于用UML聚合来表示对象组合,以表明聚合的元素是整个聚合的一部分(UML组合过于严格,尤其是对于类具有参考语义学的语言,如Java或C#)。然而,这个论点是可以讨论的,因为设计不应该由实现技术驱动。此外,现代UML的点符号更准确地表达了这些语义学。
在解决方案图上做出了一些真正可以讨论的选择:如果我们以承租人和出租人为例,从承租人的设计角度来看,他们有一些租赁合同,可能需要找到它们。毕竟,租金是租客业务角色的一部分。相反,从合同的角度来看,承租人是合同的一方。因此,可以在两个方向上保护聚合,但不能同时在两侧都有聚合。任意选择只显示真相的一面可能会令人困惑。在相反的方向上添加两个聚合并不能恰当地表明它实际上是相同的关系。另一个参数是尽可能避免聚合。
结论:由于没有客观标准来决定何时使用聚合,并且考虑到使用聚合或关联不会产生其他重大影响,请保持简单:当您在图表中阅读聚合时忽略聚合,并且您自己,避免在您自己的图表中使用聚合,而是选择关联。
-
我需要汇总以下记录中的所有标记: https://gist.github.com/sbassi/5642925 (这个片段中有2个样本记录)并按大小对它们进行排序(首先是出现频率更高的标记)。但是我不想考虑具有特定“user_id”的数据(比方说,2,3,6和12)。 以下是我的尝试(只是聚合,没有过滤和排序): db。用户库。聚合({$unwind:“$annotations.data.tags
-
有没有办法将弹性搜索GeoHash转换为具有适当缩放级别的bing地图图钉? https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-geohashgrid-aggregation.html
-
我有一个2节点的HA服务器。节点1处于活动状态,节点2处于备用状态。 我已经做了一个应用程序,并使用quartz api做集群。我已经把数据库里的所有桌子都做好了。 现在,我是否需要同时在节点或jst节点1中运行该模块,以便当节点1关闭时,应用程序自动在节点2中启动。 在两个节点中运行模块时,触发器和作业名应该相同还是不同? ThreadPool.ThreadCount=10 ThreadPool
-
DBSCAN是一种基于密度的聚类算法,这类密度聚类算法一般假定类别可以通过样本分布的紧密程度决定。同一类别的样本,他们之间的紧密相连的,也就是说,在该类别任意样本周围不远处一定有同类别的样本存在。 通过将紧密相连的样本划为一类,这样就得到了一个聚类类别。通过将所有各组紧密相连的样本划为各个不同的类别,则我们就得到了最终的所有聚类类别结果。 2. DBSCAN密度定义 在上一节我们定性描述了密度聚类
-
不知道如何表达这个问题。我正在使用Elasticsearch 2.2。 让我们从数据集的一个示例开始,该数据集由5个文档组成: 被调用的\u实体始终具有uuid。coverage\u实体可以为空,也可以具有uuid。 我使用脚本在任何一个被调用的\实体上进行聚合。uuid或coverage\u实体。uuid: 现在,聚合已经从任一头生成了术语。调用了\u实体。uuid或标头。coverage\u实
-
我有mongodb聚合查询,它在shell中工作得很好。如何重写此查询以便与morphia一起使用? 只接受一个字段名,但我需要向该集合添加对象。