《集群》专题
-
Cassandra 3.3-集群节点-不规则行为
我有一个符合节点 {192.168.120.57,192.168.120.58,192.168.120.59}的Cassandra集群,复制因子为2。 我检测到节点192.168.120.59行为异常 但是- 我查看了这个节点(192.168.120.59)的日志,显示: 在其他节点中,日志多次显示: 这些是我做过的事情,但没有成功:< br> 1)重新启动机器。< br> 2)节点工具修复。 3
-
Hazelcast:无法加入群集。现在关闭
我们正在尝试创建一个带有两个Docker容器的Hazelcast集群,并从客户端应用程序访问它,但我们可以启动一个Hazelcast容器,而启动另一个容器时,getting无法加入集群。现在关机。例外 我们使用以下命令启动docker容器。
-
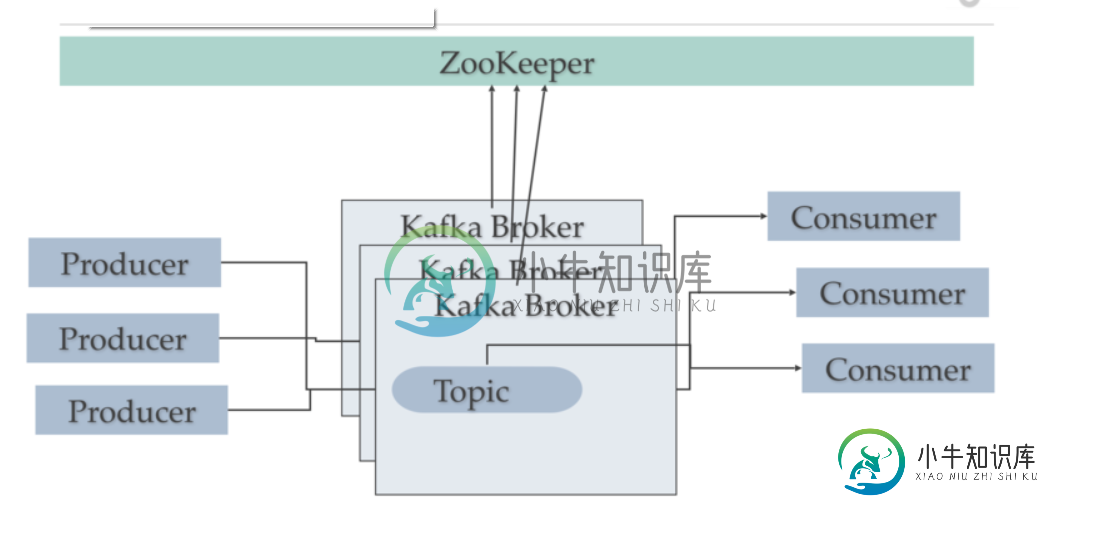 集群中的Kafka机器与Kafka通信
集群中的Kafka机器与Kafka通信我们有kafka集群,包含3个kafka代理节点和3个zookeepers服务器 Kafka版本- 10.1 ( hortonworks) 根据我的理解,因为所有的元数据都位于zookeeper服务器上,kafka代理正在使用这些数据(kafka通过端口2181与zookeeper服务器对话) 我只是想知道是否每台kafka机器都与集群中的其他kafka交谈,或者kafka可能只在动物园管理员服务
-
如何在Kafka中为集群配置server.properties
我一直在关注Kafka Quickstart在一台机器上“设置多代理集群”。(只是为了测试目的)。 用三个属性文件运行Kafka效果良好。(我在一台机器上运行它们进行测试) 1)我是为三台机器运行三个Zookeeper?使用相同的端口(2181)?还是只在一台机器上运行一个Zookeeper? 2)当我使用server.properties运行Kafka时,我知道每台机器应该有不同的broker.
-
zookeeper重启后Kafka集群丢失消息
我正在使用Docker启动一个kafka代理集群(例如,5个代理,每个容器一个代理)。Kafka版本2.12-0.11.0.0,动物园管理员3.4.10。 场景: null > 在独立模式下启动Zookeeper,然后启动kafka 创建主题 null 检查邮件 消息被累犯 null null server.properties(broker.id唯一,broker_ip:broker_port对
-
JBoss集群中的节点特定配置
我在一个集群中有两个节点;我允许用户有节点特定的配置,如日志级别,本地缓存设置等;有时,管理这些设置变得非常困难,因为用户必须知道或记住应用在特定节点上的配置--在找到该特定节点之前移动一个又一个节点;是否有任何标准或已知的方法可以从单个地方管理这些节点?比如,从httpd服务器本身还是将一个节点作为主节点并记住其他节点?
-
检查kubernetes集群中的存储容量
此外,根据kubernetes文档,节点的容量是不同的,pvc分配绑定到pv上,而pv就像节点一样是一个完全独立的集群资源。 在这种情况下,我需要检查什么存储来查找是否有任何可用空间,比如说一个x gb动态PVC?还有,我怎么检查?
-
使用SpringKafka连接到多个Kafka集群
我有一个Spring启动应用程序,它使用来自 Kafka 集群中某个主题(例如 topic1)的消息。这就是我的代码目前的样子。 现在我想从另一个Kafka集群中的不同主题开始消费。一种方法是为此创建另一个bean。但是有更好的方法吗?
-
无法访问 kubernetes 集群的仪表板
当我执行时 kubectl代理 它为我提供了o/p:开始在虚拟机上的127.0.0.1:8001上提供服务 我想在主机上看到仪表板,这给我带来了问题。 192 168 113 8001 api命名空间库贝系统服务https kubernetes仪表板代理 有什么问题,我没明白。我是库伯内特斯的新手。谢谢
-
库伯内特斯没有音调集群
我正在尝试让cadence在kubernetes集群上运行。然而,我注意到Cadence服务器初始化中有一个bug,它阻止Cassandra脚本正确初始化模式。https://github.com/uber/cadence/issues/1713:所以我想我会手动完成这一步。我执行了以下步骤- < li >在docker compose上从https://raw . githubuserconte
-
Hadoop copyToLocalFile在Yarn集群模式下失败
我试图从我的Spark2应用程序中使用Hadoop的copyToLocalFile函数将一个文件从HDFS复制到本地。
-
nosuchmethoderror:在yarn集群上进行spark-submit时
我有一个spark应用程序在本地模式下正确运行。在yarn集群上运行spark-submit时,会出现以下错误: 似乎找不到httpclient依赖项。这是我的构造 你知道吗?
-
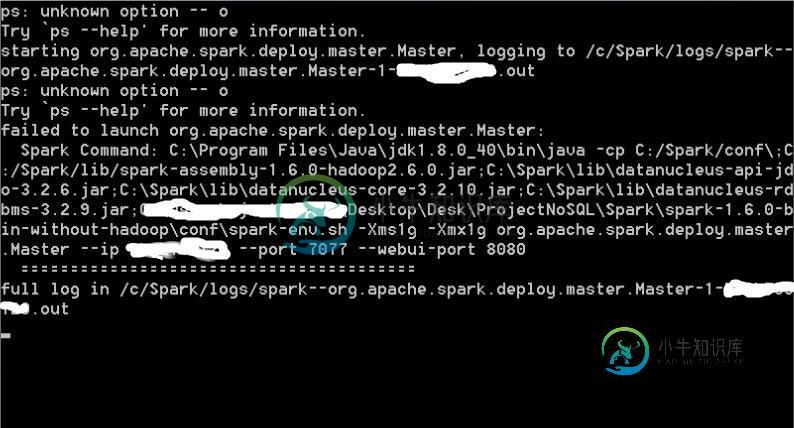 在Spark中手动启动群集失败
在Spark中手动启动群集失败来自log的信息(c:\spark\logs\spark--org.apache.spark.deploy.master.master-1-xxxxxx.out: Spark命令:C:\program files\java\jdk1.8.0_72\bin\java-cp C:\Spark/conf\;C:\spark/lib/spark-assembly-1.6.0-Hadoop2.6.0.jar
-
使用JAR文件作为DataRicks集群库
我需要安装一个JAR文件作为库,同时设置数据库群集作为Azure发布管道的一部分。到目前为止,我已经完成了以下工作- 使用Azure CLI任务创建群集定义 使用curl命令将JAR文件从Maven仓库下载到管道代理文件夹 在管道代理上设置数据库CLI 使用将JAR文件从本地(管道代理)目录复制到dbfs:/FileStore/jars文件夹 我正在尝试创建一个集群范围的init脚本(bash)脚
-
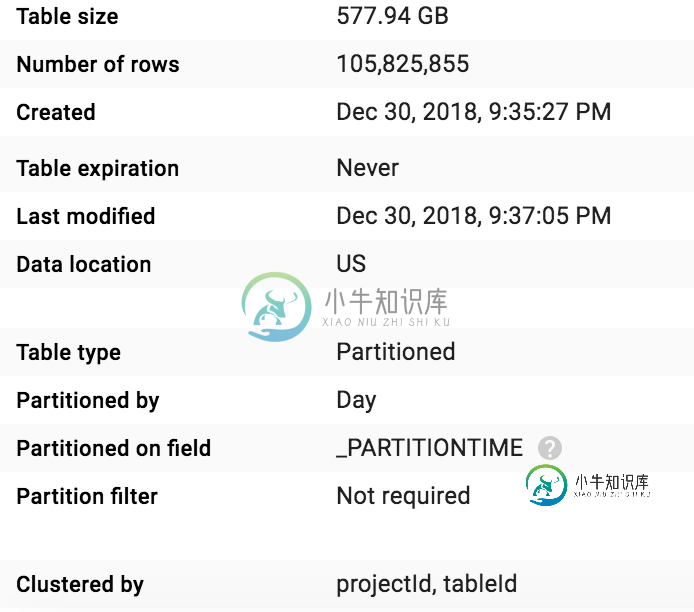 BigQuery群集字段用法/值不清楚
BigQuery群集字段用法/值不清楚我创建了一个包含集群字段的表,但我没有看到任何节省或任何性能改进,这就是我所做的: 我使用以下SQL创建了一个包含3列的目标表:projectId、tableId和schema: 分区字段:默认分区时间群集字段:projectId,tableId 此sql的原始成本为:$2.82 现在,当从新表中进行选择时,我希望 < li >降低成本 < li >获得更好的性能 我正在使用这个SQL 从我的基准