
在Spark中手动启动群集失败

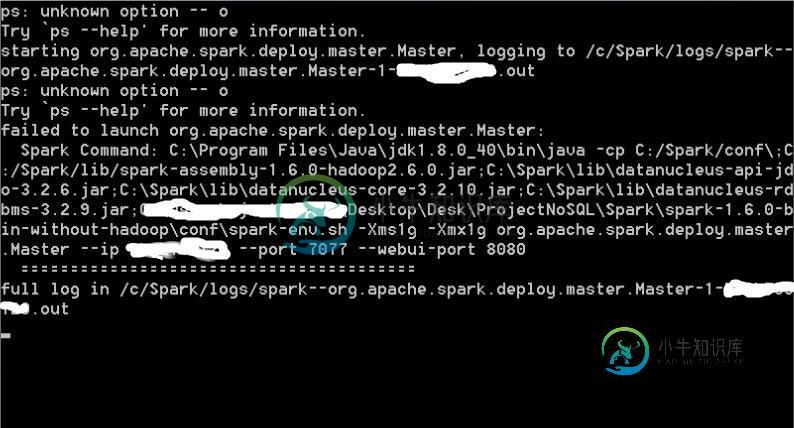
来自log的信息(c:\spark\logs\spark--org.apache.spark.deploy.master.master-1-xxxxxx.out:
Spark命令:C:\program files\java\jdk1.8.0_72\bin\java-cp C:\Spark/conf\;C:\spark/lib/spark-assembly-1.6.0-Hadoop2.6.0.jar;C:\spark\lib\datanucleus-api-jdo-3.2.6.jar;C:\spark\lib\datanucleus-core-3.2.10.jar;C:\spark\lib\datanucleus-rdbms-3.2.9.jar-xms1g-xmx1g org.apache.spark.deploy.master.master--IP xxxxxx--端口7077--WebUI-port 8080
我使用以下源代码解决了这个问题,但没有成功:
Spark独立模式
如何设置本地独立Spark节点
在单个独立计算机中设置Apache Spark集群
谢谢你的任何反馈。
共有1个答案

我想你有点搞混了。在Windows机器上运行Spark时--使用远程主机或在本地运行都是有意义的。在这两种情况下-使用bin\spark-shell.cmd(或另一个bin/*.cmd)。在Windows计算机上,只应执行以.cmd结尾的命令。当您运行start-master.sh时,您所说的是-我希望将此机器用作spark集群的资源管理器,以便其他spark客户机可以连接到它并执行查询。这可能不是你想要的。当您执行local[*]时,您已经使用了所有的本地资源,没有必要开始“master”。如果您需要更多的资源--启动一个远程集群(例如EMR),然后用bin\spark-shell.cmd--master amazon.ip:7077连接到它
-
启动Apache Spark集群通常是通过代码库提供的spark-submit shell脚本完成的。但问题是,每次集群关闭并重新启动时,您都需要执行那些shell脚本来启动spark集群。 我也对其他解决方案持开放态度。
-
在我最开始写作本书的时候,kubernetes刚发布1.6.0版本,而kubernetes基本按照每三个月发布一个大版本的速度迭代,为了使用新特性和只支持新版本kubernetes的配套软件,升级kubernetes就迫在眉睫,在此我们使用替换kubernets的旧的二进制文件这种暴力的方式来升级测试集群,若升级生产集群还望三思。 另外,自kubernetes1.6版本之后发布的1.7和1.8版本
-
我的问题是:如果有,比方说20个节点,这是相当乏味和耗时的。有没有一种方法可以像Hadoop那样从某个本地化位置启动Spark?当您从主节点运行Hadoop时,它会远程启动所有从节点。我正在寻找一个这样的解决方案,或者一个可以SSH到节点并启动它们的python脚本。
-
我有一个3节点Hadoop集群(Apache Hadoop-2.8.0)设置。我已经部署了2个使用QJM在HA模式下配置的名称代码。在安装namenode的同一台计算机上配置了2个数据阳极。第三个节点仅用于仲裁目的。 需要帮助..
-
每当我启动Hadoop集群时,系统都会询问密码。 我已经在.ssh文件夹中添加了密钥。 开始-dfs.sh 19/01/22 20:38:56警告util.nativeCodeLoader:无法为您的平台加载本机Hadoop库...使用内置Java类(如果适用)在[localhost]xxxx@localhost's password上启动namenode:localhost:启动namenode