
BigQuery群集字段用法/值不清楚

我创建了一个包含集群字段的表,但我没有看到任何节省或任何性能改进,这就是我所做的:
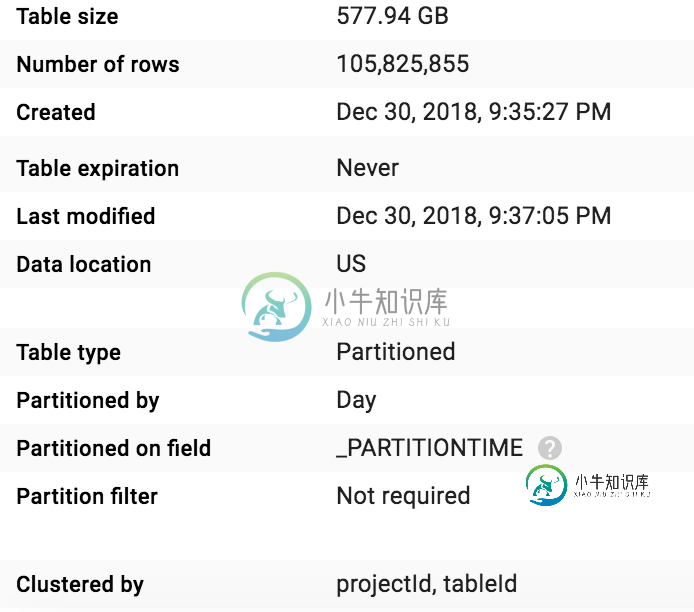
我使用以下SQL创建了一个包含3列的目标表:projectId、tableId和schema:
SELECT projectId, tableId, schema
FROM `project.dataset.tables`
WHERE _partitionTime >= '2018-12-27 00:00:00'
分区字段:默认分区时间群集字段:projectId,tableId
此sql的原始成本为:$2.82
现在,当从新表中进行选择时,我希望
-
< li >降低成本 < li >获得更好的性能
我正在使用这个SQL
SELECT * FROM `project.table.testCluster`
WHERE projectId = 'xxx' and tableId = 'yyy'
AND _PARTITIONTIME >= TIMESTAMP("2018-12-30") LIMIT 1000
从我的基准测试和BigQuery控制台执行报告中,我都看不到
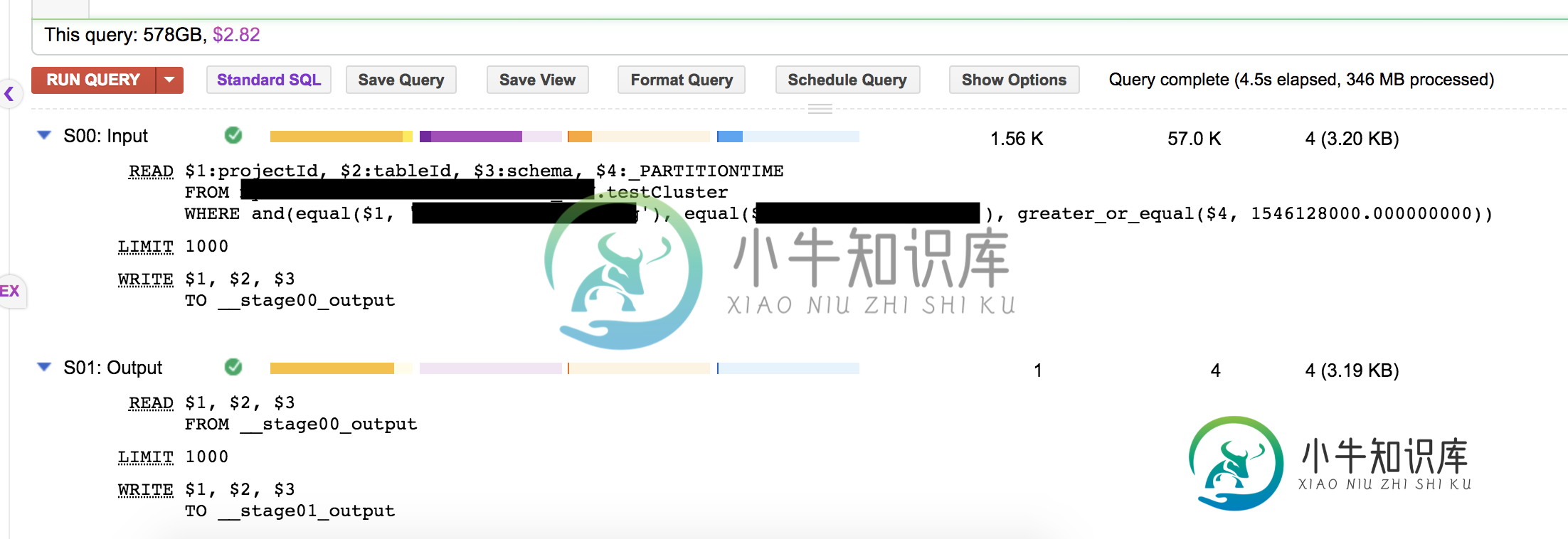
知道为什么吗?
共有1个答案

BigQuery根据集群列中的值对集群表中的数据进行排序,并将它们组织成块。当您提交一个包含聚集列上的筛选器的查询时,BigQuery使用聚集信息有效地确定块是否包含与查询相关的任何数据。
这允许BigQuery只扫描相关的块-这个过程称为块修剪。
这里有个小问题。BigQuery提供了在运行查询之前每个查询将查询多少数据的估计。在没有聚类的情况下,所述估计是精确的。通过聚类,估计值是一个上限,查询可能会减少查询次数或保持不变。这取决于聚集列的结构。聚集列中的唯一值越高,优化程度越低。
-
清理 Node 节点 停相关进程: $ sudo systemctl stop kubelet kube-proxy flanneld docker $ 清理文件: $ # umount kubelet 挂载的目录 $ mount | grep '/var/lib/kubelet'| awk '{print $3}'|xargs sudo umount $ # 删除 kubelet 工作目录 $
-
阅读此repo:Google Cloud Storage和BigQuery connectors下的说明,我按照以下初始化操作创建了一个新的Dataproc集群,其中安装了特定版本的Google Cloud Storage和BigQuery connector: --properties=core:fs。gs。含蓄的迪尔。修理启用=错误 正如您应该能够看到的,我必须将外部依赖项添加到我自己的桶中:
-
问题内容: 我正在对在特定时间范围内联合在一起的多个表运行查询。 过去,“模式”中不存在特定字段,但是在该时间范围的一半左右,该字段开始存在并开始填充数据。 有没有办法有条件地选择它(如果存在),否则用一个值任意填充一个命名字段? 像这样: 问题答案: 下面应该给你方向 假设原始表()中有a,b和c作为字段-如果您需要将缺失值从NULL更改为0,则可以使用上面的内容(见下文):
-
问题内容: 我想出了一些可行的方法,但并非完全符合我的期望。这是我的解决方案: attribute_category_map是一个具有两列的表,我在其中查找第1列中的对应值,并用第2列中的值替换目标表中的数据。我实现的最佳结果- 用相同的值更新了一行中的所有嵌套字段,这仅适用于第一个嵌套字段,而不是使用特定值更新每个嵌套字段。 主表的简化架构: 会话行中通常有多个匹配项,一个匹配项中通常包含多个产
-
如果和具有相同的值,则方法返回。但当我通过执行以下操作检查它们是否相同时: 然后在上向我显示错误,表示值无法解析或不是字段。 类平铺:
-
如果我使用带有2个读取副本的AWS Aurora MYSQL数据库,我需要使用不同的连接字符串进行读写,还是由集群endpoint为我路由流量?如果是这样的话,对于一个写得更少的应用程序来说,让读副本成为比主副本更大的实例(更强大)是否明智,因为它几乎不会被使用? 提前道谢。