《集群》专题
-
从Kubernetes吊舱访问另一个集群
我在GKE负责詹金斯。构建的一个步骤是使用< code>kubectl部署另一个集群。我在jenkins容器中安装了gcloud-sdk。正在讨论的构建步骤是这样做的: 然而,我得到了这个错误(虽然它在本地正常工作): 注意:我注意到,在没有配置的情况下(~/.kube为空),我可以使用kubectl并访问pod当前运行的集群。我不知道它是如何做到的,它是否使用/var/run/secrets/k
-
Storm群集安装在本地-未执行
我试图在同一台机器上运行zookeeper、nimbus和supervisor来模拟storm集群(我知道storm是作为分布式系统设计的,但为了学习,我想模拟单机中的工作方式)。
-
维护 TiDB 集群所在的 Kubernetes 节点
TiDB 是高可用数据库,可以在部分数据库节点下线的情况下正常运行,因此,我们可以安全地对底层 Kubernetes 节点进行停机维护。在具体操作时,针对 PD、TiKV 和 TiDB 实例的不同特性,我们需要采取不同的操作策略。 本文档将详细介绍如何对 Kubernetes 节点进行临时或长期的维护操作。 环境准备: kubectl tkctl jq 注意: 长期维护节点前,需要保证 Kuber
-
vertx集群:组织。vertx。Java语言果心json。解码异常:解码失败:意外字符(群集)
一切都很好,这是一款多功能Vertx应用程序。但是,当使用集群时,在使用Hazelcast集群时,在事件总线中获取上述异常(不会将错误传递给处理程序)。由于JSON传递的一些数据很大,我假设数据被截断并导致这种情况。此后,如果您没有将接收/发送缓冲区的大小设置得足够大,那么HTTP中也会发生相同的错误,我认为在Hazelcast中这样设置它们: 会修复它不能修复的东西。错误如下所示: at[来源:
-
集合根据集合的内容引发或不引发ConcurrentModificationException
问题内容: 以下Java代码按预期抛出: 但是以下示例仅在的内容上有所不同,执行时没有任何例外: 打印输出“ [lalala]”。为什么在第一个示例执行时第二个示例却不抛出? 问题答案: 简短答案 因为不能保证迭代器的快速失败行为。 长答案 之所以会出现此异常,是因为除非通过迭代器,否则无法在迭代集合时操作集合。 坏: 好: 现在转到“为什么”:在上面的代码中,请注意如何执行修改检查- 删除操作将
-
将基于Eclipse / cdt的构建集成到持续集成中
问题内容: 我必须使用CDT,mingw和cdt管理的构建功能(没有外部makefiles或构建环境)来重用当前在eclipse中开发的主要C ++项目。该项目本身由许多子项目组成。 我想将该构建集成到一个连续集成服务器(即jenkins)中,因此必须能够自动化无头构建。 到目前为止,我设法签出了该项目(从jenkins轻松完成),并使用以下命令使用eclipse以无头模式构建它: 但是还不够:
-
 阿里巴巴集成数据采集前端社招面经
阿里巴巴集成数据采集前端社招面经(全程30分钟) 问我做过的项目,并介绍做过的项目 问如何封装一个表单项(暴露value和onChange,其他的就是一些设计细节什么的) hook和高阶组件各解决了什么问题,有什么优势 JS如何判断一个实例是数组实例(我说了instanceof和prototype.construct) JS数组元素去重(new Set,Object key) 如何遍历Object(Object.keys, fo
-
如何将数据随机分为训练集和测试集?
问题内容: 我有一个很大的数据集,想将其分为训练(50%)和测试集(50%)。 假设我有100个示例存储了输入文件,每一行包含一个示例。我需要选择50条线作为训练集和50条线测试集。 我的想法是首先生成一个长度为100(值范围从1到100)的随机列表,然后将前50个元素用作50个训练示例的行号。与测试集相同。 这可以在Matlab中轻松实现 但是如何在Python中完成此功能?我是Python的新
-
是否可以检查集合或子集合是否存在?
问题内容: 有没有一种方法可以检查nodestore的firestore中是否存在子集合? 目前,我正在使用文档,但是我需要检查文档中是否存在子类以便写入一些数据。 问题答案: 就在这里。您可以使用docs.length来知道子集合是否存在。 我制作了一个样本来指导您,希望对您有所帮助。
-
Java中传统集合与并行集合之间的区别
本文向大家介绍Java中传统集合与并行集合之间的区别,包括了Java中传统集合与并行集合之间的区别的使用技巧和注意事项,需要的朋友参考一下 众所周知,在Java中,集合是最重要的概念之一,它使Java本身成为一种强大的语言。它仅支持Java中的集合,这使得它可以方便,有效地支持任何类型的数据以及可能对它们进行的CRUD操作。 但是在同一阶段,当集合暴露于多线程环境时,由于某些地方集合缺乏对多线程环
-
JAVA集合框架工具类自定义Collections集合方法
本文向大家介绍JAVA集合框架工具类自定义Collections集合方法,包括了JAVA集合框架工具类自定义Collections集合方法的使用技巧和注意事项,需要的朋友参考一下 项目中有需要多次统计 某些集合中 的某个属性值,所以考虑封装一个方法,让其其定义实现计算方式。 话不多说,看代码: 1、封装的自定义集合工具类:CollectionsCustom 2、测试类TestCollections
-
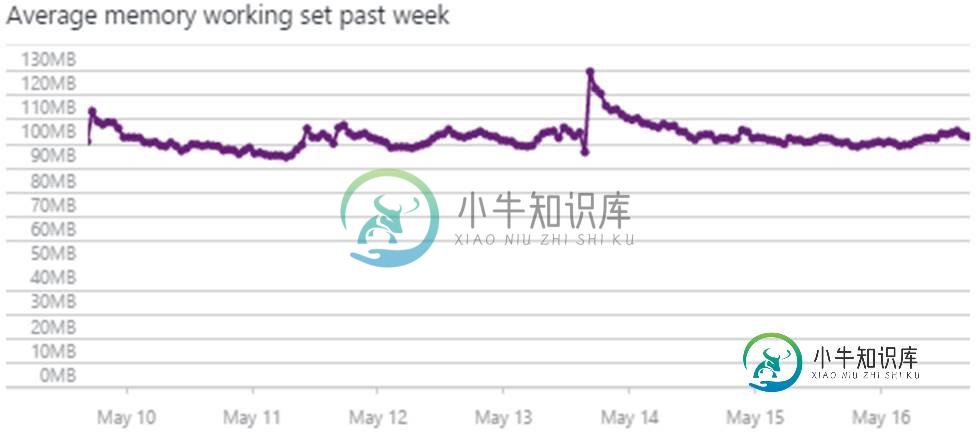 Azure中的平均内存工作集和内存工作集
Azure中的平均内存工作集和内存工作集我在Azure中有一个应用程序服务。它显示了两个称为“平均内存工作集”(Average Memory Working Set)和“内存工作集”(Memory Working Set)的度量。现在,内存工作集被定义为进程中线程最近接触到的内存页集。门户中显示的这两个图形如下所示: 现在,我有三个问题: > 如何找出我的服务的专用最大内存是多少?一旦达到限制会发生什么? 内存工作集是进程中的线程最近接
-
如何有效查询数据集中的连续日期集?
问题内容: 我有一个表,每个月的每月(一年中的每个月)包含1条记录。我需要确定给定月份的站点是否至少有15个连续记录,并且我需要知道该连续天数的开始和结束日期。我可以在存储过程中执行此操作,但我希望可以在单个查询中完成此操作。我正在处理一个相当大的数据集,每月至少有3000万条记录。 结果示例: 感谢您的帮助! 问题答案: 这是有关如何执行此查询的示例: 然后查询: 结果: 问候,罗布。
-
 非常漂亮的相册集 使用jquery制作相册集
非常漂亮的相册集 使用jquery制作相册集本文向大家介绍非常漂亮的相册集 使用jquery制作相册集,包括了非常漂亮的相册集 使用jquery制作相册集的使用技巧和注意事项,需要的朋友参考一下 一、简单的图像翻滚 image-rollover常被用在交互式导航栏上,当我们的鼠标移动到导航栏时,按钮的外观改变。例如我们以如下几幅黑白缩略图作为导航图表,当鼠标移动到指定图标时,图标变为明亮的彩色图片。预览如下: 该页面的代码十分简单,我们以此
-
如何为SpringBoot中的集成测试创建liquibase变更集?
我想用liquibase变更集进行模拟数据的集成测试,如何使其不影响真实数据库?我从这里找到了部分想法,但我使用的是springboot,我希望有更简单的解决方案。