
Azure中的平均内存工作集和内存工作集

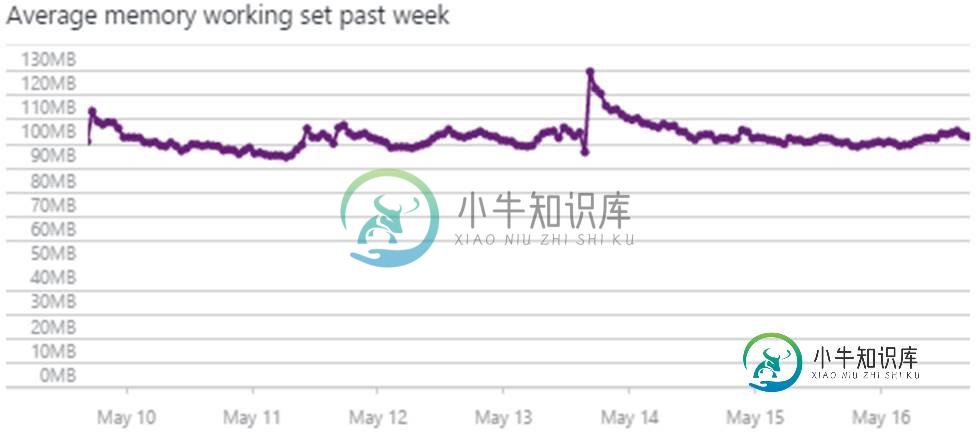
我在Azure中有一个应用程序服务。它显示了两个称为“平均内存工作集”(Average Memory Working Set)和“内存工作集”(Memory Working Set)的度量。现在,内存工作集被定义为进程中线程最近接触到的内存页集。门户中显示的这两个图形如下所示:
现在,我有三个问题:
>
内存工作集是进程中的线程最近接触的内存页数。我认为这意味着内存工作集只会在我的代码有一些内存泄漏、导致其他页面加载到内存等情况下增加。我的问题是是否有任何外部因素,如请求数量对内存工作集有任何影响,即如果请求从200增加到500,内存工作集会增加吗?如果是,为什么?
如何计算平均内存工作集?是否随时间计算?查看图表,我发现平均内存工作集和内存工作集的值几乎相似。
共有1个答案

让我尽量回答:
要知道专用最大内存,您应该检查进程的“专用工作集”。我想您可以在task manager中或在KUDU(Azure)的帮助下找到此信息。用谷歌搜索一下,你会很容易找到的。
1.b一旦达到限制,进程将访问共享工作集。
2、内存工作集是“应用程序在MiBs中使用的当前内存量”。
2.b如果请求增加了2.5倍,那么内存工作集很可能会随着新对象的创建而增加,前提是可以分配可共享的物理内存。
3. a平均工作内存集是“应用程序使用的MiB中的平均内存量”
-
我正在对Azure应用程序服务中托管的API进行性能测试。每当工作内存集图中出现峰值时,我的API响应时间就会增加。但我的应用程序服务计划显示,只有一个实例在运行,内存就占到了50-55%。 你能向我澄清一下,为什么每次“工作内存集”出现峰值时,API响应时间都在增加,即使我的应用程序服务计划内存只有50%左右? 响应时间图 工作记忆集图
-
通过查看shmget()的手动页面,我了解到shmget()调用在内存中分配了#个页面,这些页面可以在进程之间共享。 它是否要创建内核内存页,并将其映射到进程的本地地址空间?还是为该段保留了相同的进程内存页,并将为其他附加进程共享相同的内存页? 调用shmget()时,内核将保留一定数量的段/页。 调用shmat()时,保留的段映射到进程的地址空间/页。 当一个新进程附加到同一段时,前面创建的内核
-
问题内容: 据我所知,当我们创建一个时: JVM为此保留了内存的连续部分。当我们将新元素添加到列表中时,当元素数量达到75%时,它将保留新的连续内存部分并复制所有元素。 我们的名单越来越大。我们正在添加新对象,并且必须再次重建列表。 现在会发生什么? JVM正在寻找连续的内存段,但是找不到足够的空间。 垃圾收集器可以尝试删除一些未使用的引用和碎片整理内存。如果JVM在此过程之后无法为列表的新实例保
-
5个节点各有4个内核和32GB内存,其中一个节点(节点4)有8个内核和32GB内存。 所以我总共有6个节点-28个核,192GB RAM。(我想使用一半的内存,但要使用所有的内核) 计划在集群上运行5个spark应用程序。 我的spark\u默认值。配置如下: 我想在每个节点上使用16GB max,并通过设置以下配置在每台机器上运行4个工作实例。所以,我希望(4个实例*6个节点=24个)集群上的工
-
我想了解cadence-client如何为长期运行的工作流管理内存。假设一个工作流运行了6个月,但它在整个持续时间内都不处于活动状态。当客户端接收到与此工作流相关的信号,执行一些活动,然后再次变为空闲时,它将变为活动状态。我正在使用java库提供的< code>Workflow.await方法来实现这一点。 我的问题是,节奏如何管理这些空闲工作流(以及此工作流创建的所有状态变量)?由于工作流尚未完