《雪花算法》专题
-
 同花顺
同花顺投的Java开发,上周hr打电话问我说java人太多,能转安卓开发,寻思同意去面一下,周五面试官约的今天。 没录音,内容有些忘记了。 1.首先自我介绍 2.问自己的项目,项目跟我聊的倒挺多 3.设计模式,用过哪些,知道哪些,我给自己挖坑了,说分三种,说了一些,结果问我按照什么分类,我说集体的忘了 4.chatgpi了解过没用过没,看过openai代码没 5.平时爱好,八股好像没咋问我很奇怪,估计是
-
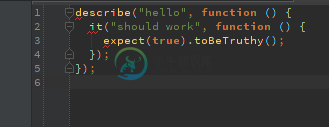 WebStorm茉莉花集成-JSHint无法识别茉莉花
WebStorm茉莉花集成-JSHint无法识别茉莉花我使用文件在 Webstorm 8.0.4 中设置了茉莉花集成 这与语法突出显示的工作方式一样,我可以跳转到声明,文档显示正确。所以连接看起来很好。然而,JSHint仍然为每个关键字抱怨它没有被定义,例如 另请参见以下屏幕截图。正如您所看到的,语法突出显示很好,但我仍然收到一个错误。
-
火花SQL:选择与算术列值和类型转换?
我将Spark SQL用于数据帧。有没有一种方法可以像在SQL中一样,使用一些算术来执行select语句? 例如,我有以下表格: 现在,我想用SELECT语句创建一个新列,并对现有列执行一些算术运算。例如,我想计算比率。我需要先把价值(或年数)转换成双倍。我试过这句话,但无法解析: 我在“如何在Spark SQL的DataFrame中更改列类型?”中看到了类似的问题,但这不是我想要的。
-
如何在具有所有者权限的过程中运行雪花副作用功能,例如SYSTEM $ GENERATE_SCIM_ACCESS_TOKEN?
问题内容: 基本上我想在雪花中进行SCIM集成。为此,我必须使用此命令来获取将传递给Azure AD的令牌: 该命令只能与AccountAdmin一起运行。并使用AccountAdmin运行它,我可以获取令牌,但是以后我将不再具有AccountAdmin的权限,因此,为此,我使用AccountAdmin创建了一个过程并将其作为所有者执行。这样,当拥有该过程使用权限的任何其他角色调用此过程时,它将以
-
火花拼花地板大小不均
由于,我检查了一个spark作业的输出拼花文件,该作业总是会发出声音。我在Cloudera 5.13.1上使用了 我注意到拼花地板排的大小是不均匀的。第一排和最后一排的人很多。剩下的真的很小。。。 拼花地板工具的缩短输出,: 这是已知的臭虫吗?如何在Spark中设置拼花地板块大小(行组大小)? 编辑: Spark应用程序的作用是:它读取一个大的AVRO文件,然后通过两个分区键(使用
-
火花:多个火花-并行提交
一些脚本在工作时什么也不做,当我手动运行它们时,其中一个失败了,出现了以下消息: 错误SparkUI:未能绑定SparkUI java.net.bindexception:地址已在使用:服务“SparkUI”在重试16次后失败! 所以我想知道是否有一种特定的方法来并行运行脚本?
-
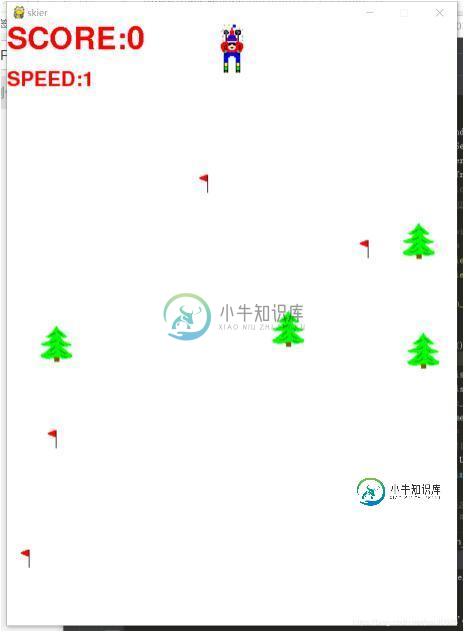 python实现滑雪者小游戏
python实现滑雪者小游戏本文向大家介绍python实现滑雪者小游戏,包括了python实现滑雪者小游戏的使用技巧和注意事项,需要的朋友参考一下 引言 这是一个用pygame写的滑雪者的游戏。 skier从上向下滑,途中会遇到树和旗子,捡起一个旗子得10分,碰到一颗树扣100分,可以用左右箭头控制skier方向。 安装pygame 用pip或设置界面安装,可自行百度 以下是主界面代码,每一个类都是一个py文件,需要导包 以
-
 8. 奈雪的茶面试复盘
8. 奈雪的茶面试复盘结果: 挂了 时间 2023.3.8 心得 当时面下来感觉回答的还可以,第一次面试下来回答的这么好,两个面试官,结束后面试官说主管在开会来不了,让我先回去等消息,我以为过了。 但后面复盘下来发现,基础回答的还行,但项目经历一般,线程池这块没回答好,而且细细想来,当时就应该是挂了,主管在开会只是个借口罢了。 注: ----- 以下答案不再更新(考虑删除),统一在面试宝典中更新 为什么要用分布式锁?
-
libGdx:有舞台时不画雪碧
我肯定我错过了一些非常明显的东西,但我是初学者,所以请不要压碎我。我的问题是我有一个视口比屏幕小的舞台。现在我也想直接用Sprite.draw(SpriteBatch)在屏幕上画一个雪碧。雪碧和舞台的位置不重叠。舞台画得很好,但是雪碧看不见。当我注释掉渲染方法中的stage.draw()部分时,雪碧是可见的。 代码:这是我的渲染方法: 在这里,我初始化相机和舞台(StalleHeight是一个in
-
 廖雪峰 Python 2.7 中文教程
廖雪峰 Python 2.7 中文教程这是小白的 Python 新手教程。Python 是一种计算机程序设计语言。你可能已经听说过很多种流行的编程语言,比如非常难学的 C 语言,非常流行的 Java 语言,适合初学者的 Basic 语言,适合网页编程的 JavaScript 语言等等。
-
保存为拼花文件在火花java
我是Spark的新手。我尝试在本地模式(windows)下使用spark java将csv文件保存为parquet。我得到了这个错误。 原因:org.apache.spark.Spark异常:写入行时任务失败 我引用了其他线程并禁用了spark推测 set("spark.speculation "," false ") 我还是会出错。我在csv中只使用了两个专栏进行测试。 输入: 我的代码: 请帮
-
花纹轮胎
概述 花纹轮胎通常与同步带轮90T一起使用。 参数 材质:硅胶 直径:68.5mm 宽度:22mm 搭建案例
-
为什么RDD计算计数需要花费这么多时间
(英语不是我的第一语言,所以请原谅任何错误) 我使用SparkSQL从hive表中读取4.7TB的数据,并执行计数操作。做那件事大约需要1.6小时。而直接从HDFS txt文件读取和执行计数,只需要10分钟。这两个作业使用相同的资源和并行性。为什么RDD计数需要这么多时间? 配置单元表大约有30万列,序列化可能代价高昂。我检查了spark UI,每个任务读取大约240MB的数据,执行大约需要3.6
-
雪碧与物体相撞不掉落?
我正在用LibGDX做一个游戏,还有LibGDX,它附带的Box2D包装器。具体来说,我的游戏是2D侧滚。 我的问题是我的玩家雪碧。我需要玩家非常精确的移动,所以我决定设置它,当玩家按下箭头键时,它会调用,然后当他们停止按键时,它会将他们的线速度重置为0。 在我的游戏中,我有重力。为了确保玩家在左右移动时摔倒,我创建了方法: 当我的球员自由落体时,这很好用。然而,当我的玩家碰到任何静止的物体(包括
-
Cesium 应用篇 添加雨雪天气
作为一个三维地球,在场景中来点雨雪效果,貌似可以增加一点真实感。Cesium 官网 Demo 中有天气系统的实例,用的是Cesium中的粒子系统做的。效果如下图所示,粒子系统的本质是向场景中添加了很多物体,用 BillBoard 技术展现。这种实现方式有一个麻烦的地方就是当视角变化(拉近、拉远、平移、旋转)时,粒子就会变化,甚至会消失,影响体验。考虑用shader的方式直接模拟雨雪效果,恰好发现了