《雪花算法》专题
-
用数组和对象从多个值插入雪花表
我试图通过SQL语句将多行数组和结构插入到Snowflake中。要在列中插入值数组,我使用函数,要插入结构/字典/对象,我使用函数。 这将导致异常: SQL编译错误:VALUES子句中的表达式[Array_Construct(0,1,2)]无效 使用以下语法插入一行可以工作:
-
无法识别雪花时间戳'23-Jan-2015 23:02:39'中的DateTime
所以我有一个varchar,我正在将它转换为一个DateTime,我使用下面的语法,但我在雪花中得到了以下错误“timestamp'23-jan-2015 23:02:39'不被识别”。既然我将以这种格式获得我的数据,你有什么建议?
-
 同花顺图像算法面经
同花顺图像算法面经6.28 笔试 7.13 一面 一小时15分钟 1. 一个M*M的图像,用大小为K*K的卷积核做卷积,通道,步长为1,padding为0,计算卷积过程中乘法操作的次数 2. 什么是图像的直方图特征 3. 边缘检测的原理,流程 4. 分类问题和回归问题的区别 5. 什么是卷积的平移不变形,卷积是否具有旋转不变性 6. 反向传播如何实现的 7. CNN的流程及各个部分的作用 8. 设计或选择激活
-
雪花存储过程中的最大JavaScript字符串大小
Snowflake文档指出,VARCHAR列仅限于16 MB未压缩的https://docs.Snowflake.net/manuals/sql-reference/data-types-text.html#data-types-for-text-strings Snowflake文档指出,VARCHAR数据会自动转换为JavaScript字符串数据类型。 https://docs.Snowfla
-
我们可以在程序中使用雪花表函数吗?
专家们, 我正在尝试使用tables函数内的雪花程序。然而,它给我带来了一个错误。
-
使用Jmeter连接雪花JDBC连接器时收到错误
我对雪花+JMeter是新手。当我尝试使用以下配置来配置和运行Jmeter时,我收到以下错误。 null 我不确定,我在这里遗漏了什么。请帮帮我。 *来自Jemter结果视图的错误信息**响应消息:java.sql.sqlException:无法创建PoolableConnectionFactory(JDBC驱动程序遇到通信错误。消息:HTTP请求遇到异常:连接到
-
无法解析雪花SQL查询中的“数值”-“无法识别”错误
我正在将下面的sql查询转换为Snowflake,并得到错误“numeric Value”-“未识别”,但它没有行号。我假设它在整个查询中引用了各种“-1”实例,但没有引用任何行,所以不清楚是什么导致了这个问题。如果是对“-1”的各种引用--雪花中的替代方案是什么?Try_To_Number在这种情况下不起作用,所以希望社区有建议
-
 无法使用pandas to_sql()方法将数据插入雪花数据库表
无法使用pandas to_sql()方法将数据插入雪花数据库表我的雪花实例上有一个数据库。数据库有两个模式和。 模式使用SQLAlchemy- 我有一个列的dataframe,如下所述,需要插入到上面创建的表中- 因此,为了插入数据帧,我使用了方法,如下所示- 数据帧。to_sql(table_name,self.engine,index=False,method=pd_writer,if_exists=“append”) 这会给我一个错误- 这个错误是因为
-
 同花顺 AIGC算法实习 一面
同花顺 AIGC算法实习 一面共40分钟 1.自我介绍 2.拷打第一个项目,先让我详细介绍,然后开始提问,主要提问了强化学习里面奖励函数、ppo算法、KL散度相关的; 3.拷打第二个项目,先让我详细介绍,然后问我向量数据库怎么构建的、数据预处理相关的、向量数据库数据量、lora微调的数据量、对比解码减少幻觉的原理、比赛相关的; 4.反问,问了做什么业务和部门氛围 面试官人很好,这次没算法题,整体感觉还是挺好的,八股还是没有单独
-
遇到SQL错误:net。雪花。客户jdbc。SnowflakeSQLException:语句已关闭
我正在使用snowflake jdbc驱动程序(版本:3.12.9)以编程方式执行查询。在snowflake客户端中执行查询正在工作。如果以编程方式执行相同的查询,则会出现以下异常, 谷歌了这个例外,没有找到一个链接。 我也得到了这些错误代码:[0A00020024] 这是我的连接url:jdbc:snowflake://account.xxx.azure.snowflakecomputing.c
-
将雪花表卸载到镶木地板s3时保留模式
我的Snowflake表包含一个创建为的字段,默认为作为Snowflake数据类型。 当我用COPY命令将这个表以parquet格式卸载到s3时,我希望保留整个模式,包括这个字段的精度。但是,生成的parquet具有。 是否可以强制保持雪花数据类型精度不变?
-
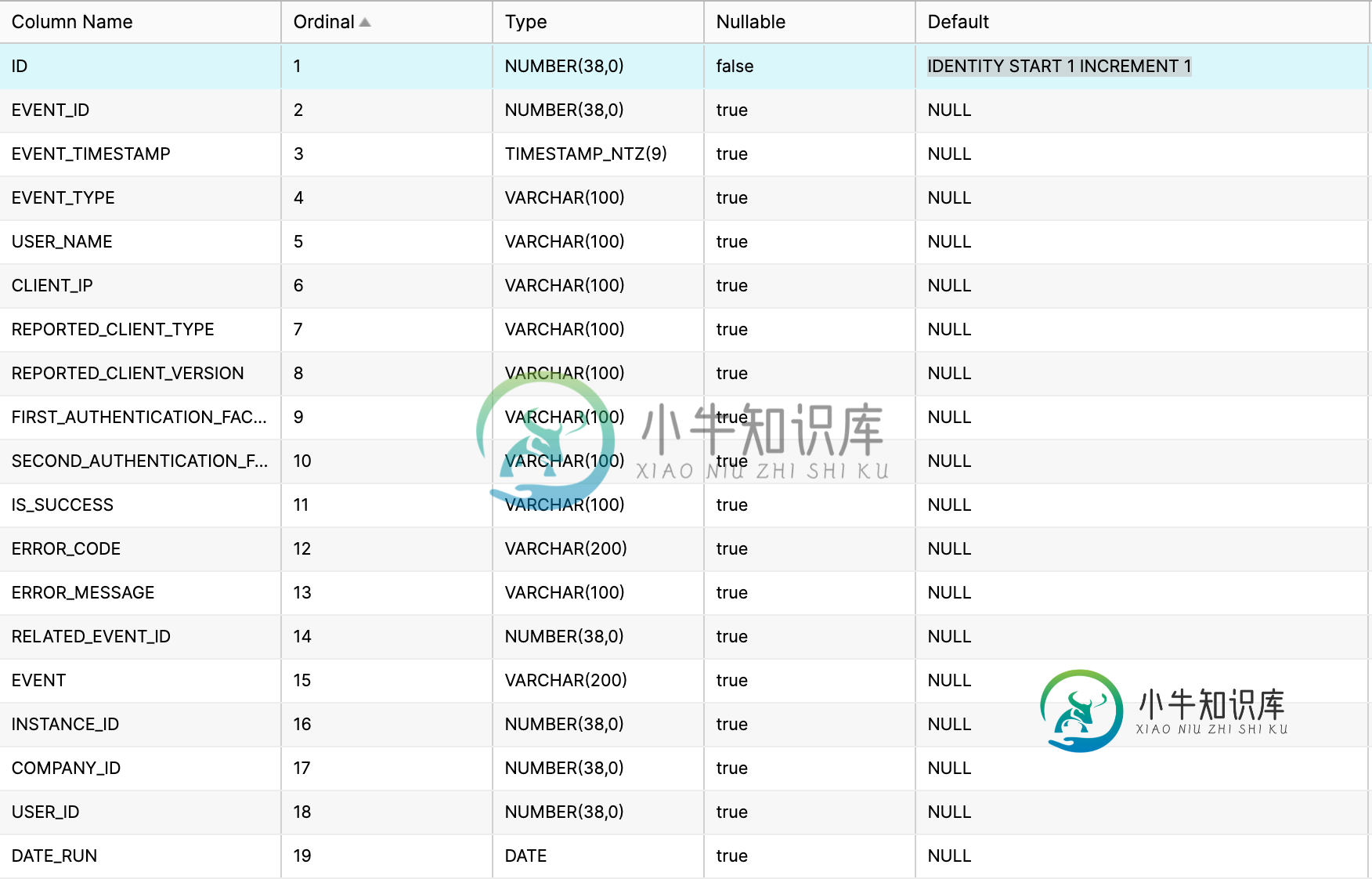
获取插入到雪花数据仓库中的行的标识
如果我有一个具有自动递增ID列的表,我希望能够在该表中插入一行,并获得我刚刚创建的行的ID。我知道,一般来说,StackOverflow问题需要一些尝试过的代码或研究成果,但我不确定从雪花开始。我翻了他们的文件,什么也没找到。 编辑:为了这里有代码: 我想为我刚刚插入的这一行找到自动递增的。
-
 我们可以将外部JSON文件复制到雪花中吗?
我们可以将外部JSON文件复制到雪花中吗?我正在尝试将外部JSON文件从Azure Blob存储加载到Snowflake。我创建了表LOCATION_DETAILS,所有列都作为variant。当我试图加载到表中时,我得到以下错误: 有人能帮我吗?
-
大写SQL语句在雪花存储过程中不起作用
在下面的示例中,存储过程工作,而不工作。两者之间唯一的区别是SQL语句的字母大小写。
-
底层的雪花驱动程序在这里共享连接吗?
使用此代码: 连接是池连接吗?我使用的是基本的java DriverManager,但在Mark的世界中,它得到的是一个雪花驱动程序,它将连接池化。所以 正在获取池连接。对吧?