《雪花算法》专题
-
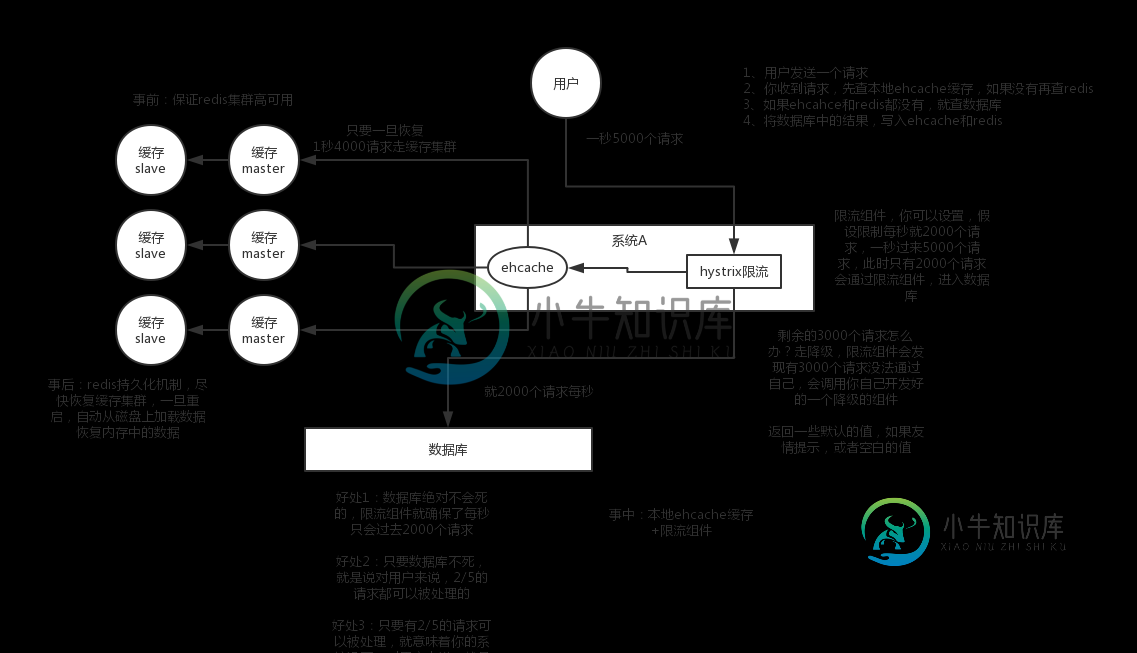 什么是缓存雪崩?有哪些解决办法?
什么是缓存雪崩?有哪些解决办法?本文向大家介绍什么是缓存雪崩?有哪些解决办法?相关面试题,主要包含被问及什么是缓存雪崩?有哪些解决办法?时的应答技巧和注意事项,需要的朋友参考一下 什么是缓存雪崩? 简介:缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。 有哪些解决办法? (中华石杉老师在他的视频中提到过,视频地址在最后一个问题中有提到): 事前:尽量保证整个 redis 集群的高
-
如何在使用火花数据帧写入时自动计算 numRepartition
当我尝试将数据帧写入Hive Parket分区表时 它将在HDFS中创建大量块,每个块只有少量数据。 我了解它是如何进行的,因为每个 spark 子任务将创建一个块,然后将数据写入其中。 我也理解,块数会提高Hadoop的性能,但达到阈值后也会降低性能。 如果我想自动设置数字分区,有人有一个好主意吗?
-
使用scala的布尔运算在火花数据帧中折叠列
我们如何使用scala使用OR操作将布尔列折叠成一行? 第1部分: 期望输出 我能想到的一个解决方案是按第一列条目对它们进行分组,filter true 这个解决方案相当混乱。此外,不知道这是否适用于所有边缘情况。有什么聪明的方法可以做到这一点吗? 编辑:给定的答案适用于上述给定的场景,但不适用于此场景。有什么方法可以实现所需的输出? 第2部分: 期望输出 我试图通过col1和col2分组,然后用
-
将Avro中存储为整数(1970年1月1日以来的天数)的“日期”转换为雪花“日期”类型
我需要将数据从一些内部数据库迁移到云中。表中的一些数据以YYYY-MM-DD格式存储为“日期”。 谢了!
-
Eclipse和花括号
问题内容: 有没有一种快速的方法可以使Eclipse将花括号放在代码块的下一行上(本身)? 问题答案: 对于预先编写的代码块,请先按照Don的建议进行设置,然后选择该代码段,然后右键单击SourceCode->Format,然后按照首选项中的设置进行格式化。
-
RDD火花质疑
我想了解以下关于火花概念的RDD的事情。 > RDD仅仅是从HDFS存储中复制某个节点RAM中的所需数据以加快执行的概念吗? 如果一个文件在集群中被拆分,那么对于单个flie来说,RDD从其他节点带来所有所需的数据? 如果第二点是正确的,那么它如何决定它必须执行哪个节点的JVM?数据局部性在这里是如何工作的?
-
 同花顺面经
同花顺面经同花顺(Java开发) 一面 面向对象特性 多态 抽象类和接口(1.8新特性) 有哪些设计模式? 单例模式属于面向对象三大特性中的哪一种 OOM GC 有哪些类加载器,怎么加载类 哪些集合是线程安全的 ConcurrentHashMap HashMap 原理 线程创建方式 线程间的通信方式 https有哪些方法实现安全 算法:实现 LRU 缓存 #同花顺##同花顺Java工程师面经#
-
 同花顺一面
同花顺一面单点登录实现 mycat实现 HttpClient连接池 Synchronized 线程池核心参数 设计模式 项目的jvm调优 服务器配置 进程线程的区别 进程的通信方式 线程的通信方式 Ioc与AOP Mysql 索引 leecode19 删除倒数第n个节点 没写过链表的输入,尬住 写的最满意的一段代码(继续尬住,打开编译器乱翻) 项目中遇到的困难 有没有过在有压力的环境下工作 #同花顺校招##
-
 同花顺二面
同花顺二面问财集群 Java 二面 项目介绍 MySQL 的基本数据类型 MySQL 的索引 MySQL 的事务,事务失效的场景 SQL 优化的思路 场景:每天上百万的数据插入一个表,如何处理 Redis 的基本数据类型 Redis 的持久化方式 Redis 主从复制原理 TCP 和 UDP 粘包和拆包的原因,解决方法 Netty 的核心组成 Spring AOP 的原理,通知类型 MyBatis ,# 和
-
 同花顺一面
同花顺一面1. 项目以及难点 2. 登录功能的实现 3. es6用过哪些api 4. 箭头函数有没有变量提升,为什么没有? 5. set和map 6. vue3和vue2的区别 7. 为什么vue2不能深度监听,是缺陷还是基于什么考量 8. 一般数组和对象是使用哪些方法实现响应式 9. computed和watch的区别 10. vue的生命周期以及this的指向 11. vue的数据流是单向还是双向的 1
-
 同花顺二面
同花顺二面10.13面的,蛮碎的,记得的一些内容 自我介绍 项目音乐滚动条和歌词浮动怎么实现的 了解过函数式编程吗 知道面向对象吗 怎么看待Vue的学习难度 实习期间主要干什么 实习时写过组件吗,有什么收获 有做过可视化相关的吗 CSS3了解吗,flex和grid了解多少 ES6最喜欢的部分 了解过V8引擎吗 偏向PC端还是移动端 说说webpack,现在最火的打包工具是啥 编程题,开始说出正则题,我说不熟
-
火花行到JSON
我想从Spark v.1.6(使用scala)数据帧创建一个JSON。我知道有一个简单的解决方案,就是做。 但是,我的问题看起来有点不同。例如,考虑具有以下列的数据帧: 我想在最后有一个数据帧 其中C是包含、、的JSON。不幸的是,我在编译时不知道数据框是什么样子的(除了始终“固定”的列和)。 至于我需要这个的原因:我使用Protobuf发送结果。不幸的是,我的数据帧有时有比预期更多的列,我仍然会
-
聚合火花流
我试图从聚合原理的角度来理解火花流。Spark DF 基于迷你批次,计算在特定时间窗口内出现的迷你批次上完成。 假设我们有数据作为- 然后首先对Window_period_1进行计算,然后对Window_period_2进行计算。如果我需要将新的传入数据与历史数据一起使用,比如说Window_priod_new与Window_pperid_1和Window_perid_2的数据之间的分组函数,我该
-
火花UDF过载
我有一个要求,火花UDF必须超载,我知道UDF超载是不支持火花。因此,为了克服spark的这一限制,我尝试创建一个接受任何类型的UDF,它在UDF中找到实际的数据类型,并调用相应的方法进行计算并相应地返回值。这样做时,我得到一个错误 以下是示例代码: 有可能使上述要求成为可能吗?如果没有,请建议我一个更好的方法。 注:Spark版本-2.4.0
-
JDBC火花连接
我正在研究建立一个JDBC Spark连接,以便从r/Python使用。我知道和都是可用的,但它们似乎更适合交互式分析,特别是因为它们为用户保留了集群资源。我在考虑一些更类似于Tableau ODBC Spark connection的东西--一些更轻量级的东西(据我所知),用于支持简单的随机访问。虽然这似乎是可能的,而且有一些文档,但(对我来说)JDBC驱动程序的需求是什么并不清楚。 既然Hiv