《pandas》专题
-
对Pandas DataFrame进行分组,计算一列的均值和标准差,并使用reset_index将std添加为新列
问题内容: 我有一个Pandas DataFrame,如下所示: 我想按“ a”列对行进行分组,同时将“ c”列中的值替换为分组行中的平均值,并添加另一列,其中“ c”列中的值的std偏差已计算出平均值。对于分组的所有行,列“ b”或“ d”中的值是恒定的。因此,所需的输出将是: 实现此目标的最佳方法是什么? 问题答案: 您可以使用以下操作: 然后重命名各列并对其重新排序: 熊猫默认情况下会计算样
-
如何使用带有gzip压缩选项的pandas read_csv读取tar.gz文件?
问题内容: 我有一个非常简单的csv,其中包含以下数据,压缩在tar.gz文件中。我需要使用pandas.read_csv在数据框中读取该内容。 但是,我得到了错误: 以下是一组read_csv命令以及我收到的不同错误: 这是怎么了 我怎样才能解决这个问题? 问题答案: 注意:将忽略有问题的行。
-
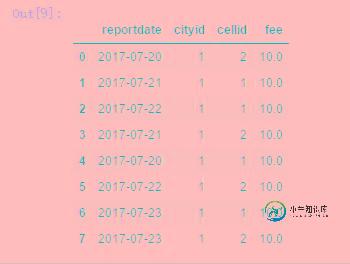 pandas实现to_sql将DataFrame保存到数据库中
pandas实现to_sql将DataFrame保存到数据库中本文向大家介绍pandas实现to_sql将DataFrame保存到数据库中,包括了pandas实现to_sql将DataFrame保存到数据库中的使用技巧和注意事项,需要的朋友参考一下 目的 在数据分析时,我们有中间结果,或者最终的结果,需要保存到数据库中;或者我们有一个中间的结果,如果放到数据库中通过sql操作会更加的直观,处理后再将结果读取到DataFrame中。这两个场景,就需要用到Dat
-
python pandas时序处理相关功能详解
本文向大家介绍python pandas时序处理相关功能详解,包括了python pandas时序处理相关功能详解的使用技巧和注意事项,需要的朋友参考一下 创建时间序列 函数pd.date_range() 根据指定的范围,生成时间序列DatetimeIndex,每隔元素的类型为Timestamp。该函数应用较多。 输出为: 主要的入参解析: start: 开始时刻,可以是字符串或者datetime
-
从Pandas DataFrame构造NetworkX图
问题内容: 我想从一个简单的Pandas DataFrame创建一些NetworkX图: 哪里是指数,并以是列。但是转换为Numpy矩阵或Recarray似乎无法为生成输入。是否有实现这一目标的标准策略?我不反对在Pandas中重新格式化数据->转储到CSV->导入到NetworkX,但是似乎我应该能够从索引生成边缘,并从值生成节点。 问题答案: NetworkX期望一个(节点和边的)方阵,也许*
-
如何在Pandas中用一个值填充一列?
问题内容: 我在Pandas DataFrame中有一列具有连续数字的列。 我想将所有这些值更改为一个简单的字符串,例如“ foo”,导致 问题答案: 只需选择该列并像往常一样分配: 分配标量值会将所有行设置为相同的标量值
-
Python:基于某些行appers的pandas数据框中的两列(变量)获得频率计数
问题内容: 您好,我有以下数据框。 我想计算同一行出现在数据框中的次数。 问题答案: 您可以使用groupby的:
-
将pandas.Series从dtype对象转换为float,将错误转换为nans
问题内容: 请考虑以下情况: 我本来希望有一个允许将错误值(例如that )转换为s的转换的选项。有没有办法做到这一点? 问题答案: 使用[](http://pandas.pydata.org/pandas- docs/stable/generated/pandas.to_numeric.html)与 如果需要填写,请使用。 注意,在可能的情况下,将尝试将浮点型转换为整数。如果不需要,请删除该参数
-
 pandas数据分组groupby()和统计函数agg()的使用
pandas数据分组groupby()和统计函数agg()的使用本文向大家介绍pandas数据分组groupby()和统计函数agg()的使用,包括了pandas数据分组groupby()和统计函数agg()的使用的使用技巧和注意事项,需要的朋友参考一下 数据分组 使用 groupby() 方法进行分组 group.size()查看分组后每组的数量 group.groups 查看分组情况 group.get_group('名字') 根据分组后的名字选择分组数据
-
快速将JSON列转换为Pandas数据框
问题内容: 我正在从一列存储为JSON的数据库(超过5万行)中读取数据。我想将其提取到pandas数据框中。下面的代码片段可以正常工作,但是效率很低,并且在对整个数据库运行时会花费很多时间。请注意,并非所有项目都具有相同的属性,并且JSON具有一些嵌套的属性。 我怎样才能使它更快? 问题答案: json_normalize接受一个已经处理过的json字符串或一系列这样的字符串。 设定
-
创建大型Pandas DataFrame:预分配vs追加vs concat
问题内容: 逐块构建大型数据帧时,Pandas的性能令我感到困惑。在Numpy中,通过预分配一个大的空数组然后填充值,我们(几乎)总是可以看到更好的性能。据我了解,这是由于Numpy立即获取其所需的所有内存,而不是每次操作都必须重新分配内存。 在Pandas中,通过使用该模式,我似乎获得了更好的性能。 这是一个带有计时的例子。该类的定义如下。如您所见,我发现预分配比使用!慢大约10倍。使用适当的d
-
Pandas:对数据透视表进行排序
问题内容: 第一次尝试熊猫,我试图先按照索引对数据透视表进行排序,然后再对一系列值进行排序。 到目前为止,我已经尝试过: 按索引然后按值对数据透视表进行排序的正确方法是什么? 问题答案: 这是一个可以做您想要的解决方案: 结果将如下所示: 将其作为API方法内置到熊猫中会很好。虽然不确定应该是什么样。
-
Pandas,过滤其中哪一列包含另一列的行
问题内容: 如何过滤包含另一列的行?例如,如果我们有两列A,B的DT,是否可以使用B.contains(A)过滤行?不仅B是否包含来自DT的所有A中的一些A值,而且还只是一行。 问题答案: 您可以使用由和(如果需要)过滤器列和每行创建的掩码: 解决方案的差异 -输入已更改:
-
将具有多个nan值的pandas系列化为一组可得出多个nan值
问题内容: 我期望得到,但我得到: 问题答案: 并非所有的Nan都是相同的: 因此, 包含,它们是相同的,所以 但包含不相同的: 因此set不会将它们视为相等: 如果您有熊猫系列,请使用它的方法而不是查找唯一值:
-
使用sort_values()独立对pandas DataFrame的所有列进行排序
问题内容: 我有一个数据框,并希望按降序或升序对所有列进行独立排序。 当我为此使用sort_values()时,它无法按预期运行(对我而言),仅对一列进行排序: 如果我使用此答案中的应用lambda函数的解决方案,则可以获得期望的结果: 但是,这对我来说似乎有些沉重。 上面的sort_values()示例中实际上发生了什么,如何在没有lambda函数的情况下以熊猫方式对数据框中的所有列进行排序?