
pandas实现to_sql将DataFrame保存到数据库中

目的
在数据分析时,我们有中间结果,或者最终的结果,需要保存到数据库中;或者我们有一个中间的结果,如果放到数据库中通过sql操作会更加的直观,处理后再将结果读取到DataFrame中。这两个场景,就需要用到DataFrame的to_sql操作。
具体的操作
连接数据库代码
import pandas as pd
from sqlalchemy import create_engine
# default
engine = create_engine('mysql+pymysql://ledao:ledao123@localhost/pandas_learn')
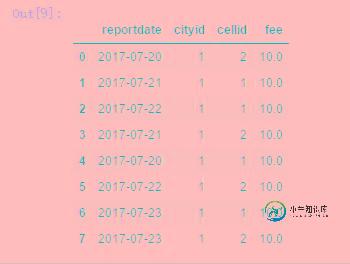
original_data = pd.read_sql_table('cellfee', engine)
original_data
结果如下所示。
对数据进行汇总,每个小区的电费进行求和放到Series中,然后将所有小区的总电费放到DataFrame中,最后将DataFrame保存到数据库中,代码如下所示。
all_cells = [] for k, v in original_data.groupby(by=['cityid', 'cellid']): onecell = pd.Series(data=[k[0], k[1], v['fee'].sum()], index=['cityid', 'cellid', 'fee_sum']) all_cells.append(onecell) all_cells = pd.DataFrame(all_cells) all_cells.to_sql(name='cells_fee', con=engine, chunksize=1000, if_exists='replace', index=None)
对于DataFrame的to_sql函数,需要注意的参数在代码中已经写出来,其中比较重要的是chunksize、if_exists和index。
chunksize可以设置一次入库的大小;if_exists设置如果数据库中存在同名表怎么办,‘replace'表示将表原来数据删除放入当前数据;‘append'表示追加;‘fail'则表示将抛出异常,结束操作,默认是‘fail';index=接受boolean值,表示是否将DataFrame的index也作为表的列存储。
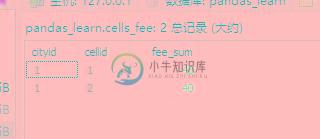
最终存表的结果如下图所示。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
我正试着在一个熊猫数据目录中加载一个SQLAlchemy。 当我尝试: 我得到一个属性错误: 和 上一个问题SQLAlchemy ORM到pandas DataFrame的转换解决了我的问题,但是解决方案:使用不是我的解决方案。我使用db.session.add()和db.session.commit()打开/关闭会话,但是当我使用时,就会得到一个属性错误:
-
我在使用JPA时遇到了一些困难。我没有得到任何异常,但我不能保存任何东西到数据库。我从Hibernate到Jpa,在那里一切都工作得很好。下面是我的文件 Application.Properties: 存储库: 服务: 我在提交表单时得到了200的响应,但在数据库中找不到数据
-
我有一个使用JPA的Spring Boot应用程序,它有两个数据源,一个用于DB2,一个用于SQL Server。 当我尝试将实体保存到SQL Server时,不会抛出任何错误,但该实体不会持久化到数据库。我看不到日志中正在生成插入。 提前感谢 下面是我尝试保存实体所执行的代码@组成部分 下面是sql Server配置。 这是SQL Server存储库 公共接口BeercupMessageLogR
-
我是拉威尔的新手,需要帮助。当我点击
-
问题内容: 我有一个具有表的应用程序,当您单击表中的项目时,它会使用其数据(FieldGroup)填充一组文本字段,然后您可以选择保存更改, 我想知道如何保存更改用户对我的postgres数据库进行的更改 。我正在为此应用程序使用vaadin和hibernate模式。到目前为止,我已经尝试做 我努力了 而且我也尝试过 最后两个给我以下错误 问题答案: 我已经弄清楚了如何对数据库进行更改,下面是一些
-
我的雪花实例上有一个数据库。数据库有两个模式和。 模式使用SQLAlchemy- 我有一个列的dataframe,如下所述,需要插入到上面创建的表中- 因此,为了插入数据帧,我使用了方法,如下所示- 数据帧。to_sql(table_name,self.engine,index=False,method=pd_writer,if_exists=“append”) 这会给我一个错误- 这个错误是因为