《pandas》专题
-
将`pandas.get_dummies`转换为新数据的简单方法?
问题内容: 假设我有一个包含要转换为指标的字符串的数据框。我用来将其转换为现在可用于构建模型的数据集。 现在,我有一个新的观察值,我想遍历我的模型。显然,我无法使用它,因为它不包含所有类,并且不会创建相同的指标矩阵。有什么好方法吗? 问题答案: 您可以从单个新观察值创建虚拟对象,然后使用原始指标矩阵中的列重新索引此框架列: 返回:
-
带有Pandas的PyInstaller创建了500 MB以上的exe
问题内容: 我尝试使用PyInstaller 3.2.1创建exe文件,出于测试目的,我尝试为以下代码制作exe文件: 经过相当长的时间(15分钟以上)后,我完成了620 MB的dist文件夹并构建了150 MB。我在Windows上使用Python 3.5.2 | Anaconda自定义(64位)。可能值得注意的是,在dist文件夹中,mkl文件负责将近300 MB。我使用’pyinstalle
-
Python(Pandas)在多索引数据框的每个lvl上添加小计
问题内容: 假设我有以下数据框: 我想创建一个MultiIndex,它将包含每个lvl的总和。输出将如下所示: 目前,我正在使用循环在每个级别上创建三个不同的数据框,然后在excel上对其进行操作,如下所示。因此,如果可能的话,我想在python中进行此计算。 提前谢谢了。 问题答案: 一些自由使用 我可以完全按照您的要求 至于如何!我将其留给读者练习。
-
通过主键将Pandas数据框追加到sqlite表
问题内容: 我想将Pandas数据框附加到名为“ NewTable”的sqlite数据库中的现有表上。NewTable具有三个字段(ID,名称,年龄),ID是主键。我的数据库连接: 我要附加的数据框: 如上所述,ID是NewTable中的主键。键“ L1”已在NewTable中,但键“ L11”不在中。我尝试将数据框追加到NewTable。 这将引发错误: 该错误很可能是因为键“ L1”已经在
-
如何使用python中的pandas获取所有重复项的列表?
问题内容: 我列出了可能存在一些出口问题的物品。我想获得重复项的列表,以便可以手动比较它们。当我尝试使用pandas重复方法时,它仅返回第一个重复。有没有办法获取所有重复项,而不仅仅是第一个? 我的数据集的一小部分看起来像这样: 我的代码当前如下所示: 那里有几个重复的物品。但是,当我使用上面的代码时,我只会得到第一项。在API参考中,我看到了如何获得最后一个项目,但是我希望拥有所有这些项目,因此
-
python pandas删除重复的列
问题内容: 从数据框中删除重复列的最简单方法是什么? 我正在通过以下方式读取具有重复列的文本文件: 列名是: 所有“时间”和“相对时间”列均包含相同的数据。我想要: 我所有的删除,删除等尝试,例如: 导致唯一值索引错误: 很抱歉成为熊猫的菜鸟。任何建议,将不胜感激。 额外细节 熊猫版本:0.9.0 Python版本:2.7.3 Windows 7 (通过Pythonxy 2.7.3.0安装) 数据
-
python pandas:如何避免链接分配
问题内容: 我有一个带有两列的pandas数据框:x和value。我想查找x == 10的所有行,并为所有这些行设置值= 1,000。我尝试了下面的代码,但收到警告 我知道我可以通过使用.loc或.ix来避免这种情况,但是我首先需要找到满足x == 10的条件的所有行的位置或索引。有没有更直接的方法? 谢谢! 问题答案: 您应该使用以确保您正在使用视图,在您的示例中以下内容将起作用并且不会发出警告
-
 尝试访问索引时,Python Pandas键错误
尝试访问索引时,Python Pandas键错误问题内容: 我在列中有以下股票数据集,在行的日期下方(使用彭博(Bloomberg)的Python API下载-请忽略以下事实:它们全都是“ NaN”-仅用于数据的这一部分): 我正在尝试从索引中提取月份和年份,以便稍后进行调整: 其中values是上述DataFrame的名称。 但这会产生错误:’KeyError’date’ 运行: 看起来不错: 所以我只是想知道问题出在哪里,为什么我似乎无法在
-
如何在Pandas中的特定列索引处插入列?
问题内容: 我可以在熊猫的特定列索引处插入列吗? 这会将列作为的最后一列,但是没有办法告诉它放在开始处吗? 问题答案: 参见文档:http : //pandas.pydata.org/pandas- docs/stable/genic/pandas.DataFrame.insert.html 使用loc = 0将在开头插入
-
如何在Pandas DataFrame中获取第二大行值的列名
问题内容: 我有一个非常简单的问题-我想-但似乎我无法解决这个问题。我是Python和Pandas的初学者。我在论坛上进行了搜索,但没有得到符合我需要的(最新)答案。 我有一个这样的数据框: 这使: 我的问题很简单:我想添加一列,以给出 每一行 第二个 最大值的列名。 我编写了一个简单的函数,该函数返回每一行的第二个最大值 这使: 但是我找不到如何在“值”列中显示列名,而不是值…我正在考虑布尔索引
-
将Pandas Dataframe列转换为一个热门标签
问题内容: 我有一个类似的熊猫数据框: 通过使用ABC列上的pandas函数,我可以得到: 虽然我需要类似的内容,但ABC列的数据类型为: 我尝试使用该函数,然后将所有列组合到所需的列中。我找到了很多答案,解释了如何将多个列组合为字符串,如下所示:在pandas / python中的dataframe中合并两列文本 。但是我想不出一种将它们组合为列表的方法。 这个问题介绍了使用sklearn’s的
-
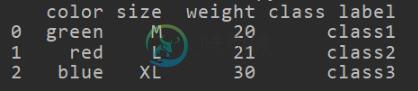 pandas 中对特征进行硬编码和onehot编码的实现
pandas 中对特征进行硬编码和onehot编码的实现本文向大家介绍pandas 中对特征进行硬编码和onehot编码的实现,包括了pandas 中对特征进行硬编码和onehot编码的实现的使用技巧和注意事项,需要的朋友参考一下 首先介绍两种编码方式硬编码和onehot编码,在模型训练所需要数据中,特征要么为连续,要么为离散特征,对于那些值为非数字的离散特征,我们要么对他们进行硬编码,要么进行onehot编码,转化为模型可以用于训练的特征 初始化一个
-
Python Pandas-为什么“ in”运算符只处理索引而不处理数据?
问题内容: 我发现了Pandas运算符应用于索引而不是实际数据的困难方式: 我的直觉是该系列包含数字1而不是索引10,这显然是错误的。此行为背后的原因是什么?以下方法是最好的替代方法吗? 更新 我对建议做了一些安排。看来是最好的方法: 问题答案: 将a视为类似于字典的字典可能会有所帮助,其中的值等于。比较: 与: 但是,请注意,对系列进行迭代将对进行迭代,而不是对进行迭代,因此将得出not 。 确
-
来自字符串或包数据的pandas.read_csv
问题内容: 我要使用read_csv读取的软件包中包含一些csv文本数据。我是这样做的 但是,StringIO.StringIO在Python 3中消失了,并且io.StringIO仅接受Unicode。有没有简单的方法可以做到这一点? 编辑 :以下似乎无效 失败于 问题答案: 以下内容在3.3中为我工作: 注意:我必须手动将其放置在该位置,所以我不能保证我已正确复制了它,并且没有终端空格,因为我
-
如何在pandas数据框列中选择一个值范围?
问题内容: 我想为某个列(例如column)选择一个范围。我想选择-0.5到+0.5之间的所有值。如何做到这一点? 我希望使用 但这(自然)给出了ValueError: 我试过了 但这全部输出了。 正确的输出应该是 在pandas数据框列中查找值范围的正确方法是什么? 编辑:问题 使用与 将是之间的区别 和不平等之类的 ? 问题答案: 使用有严格的不平等: 该参数确定是否包括端点(:,:)。这适用