《架构思维》专题
-
Swager模型架构不包括主体参数的变量名
在我的应用程序的 Swagger UI 中,我有 POST 和 PUT 方法,它们都将 POJO 作为 REST 调用中的主体参数。当我查看 UI 并单击模型架构以自动填充参数框(只是为了节省键入整个 JSON 的时间)时,它不包含参数的名称,因此请求失败。例: 模型架构: 但是,要发出请求,我需要包含参数名称,如下所示: 虽然在发出请求之前自己做这件事并不太不方便,但它给其他使用Swagger
-
在新架构中添加第二个飞行路线实例
我有一个现有的应用程序,其中包含一个现有的飞行路线迁移脚本。它使用它连接到的数据库架构。 我正在开发第二个应用程序,用于数据库目的,它将访问和schema,并具有对 的读访问权限和对 的写访问权限。我希望第二个应用程序能够为模式<code>ABC</code>处理自己的飞行路线迁移脚本。这个应用程序的flyway实例可以完全忽略公共模式。 当我运行该应用程序时,我在日志中收到以下内容 这是我。 我
-
如何在android上结合架构组件和数据绑定?
我已经开发了基于android数据绑定库的应用程序:https://developer.android.com/topic/libraries/data-binding/index.html 现在我想从新的库中使用ViewModelProviders:https://developer.android.com/topic/libraries/architecture/guide.html 它是如何
-
在Database ricks上的Delta Live Table上指定列名和架构
我正在使用sqlapi玩弄databricks delta活动表特性。这是我迄今为止的声明: 我的数据,它的读数没有标题,但我想让它使用选项推断数据类型。但我需要以某种方式至少为它提供列名称。有一个选项可以为它提供一个显式架构,但是由于这是一个登陆表,我希望将这种开销的负担降到最低。spark文档非常稀疏,数据砖文档甚至更糟。有谁知道我是否可以做到这一点?
-
如何在Swagger ui SpringDoc open ui上对架构进行排序
我想将为实体类生成的排序到中的类 我能够通过文件中的以下配置对和进行排序,但我的架构没有按排序顺序排序。 我如何排序我的模式。 谢谢。
-
Facebook代理Web应用程序-它的架构/设计好吗?
我试图建立一个java web应用程序,这是一个facebook应用程序。假设这个应用程序是facebook上的“测试应用程序”,它由“xyz.com”托管和提供服务。现在,我想让这个java应用程序在xyz.com运行——有点普通——想法是创建N个应用程序“测试应用程序1”(托管在abc.com)、“测试应用程序2”(托管在efg.com),等等(有点像服务),只使用xyz.com的这个web应
-
解析服务器-架构API配置新的解析实例
opensource解析服务器是否包含用于配置新解析实例的模式API?我试图消除手动创建应用程序的需要。 这是通过parse.com http://blog.parse.com/announcements/create-parse-apps-with-the-new-apps-api/提供的模式API
-
从XJC中导入的架构解析类型定义失败
这个API使用JAXB来方便地使用对象模型,对象模型是由XJC(XML-to-Java)编译器通过命名引用从XML模式生成的。它抽象了JAXB上下文的创建,并通过各种背景魔法和反射找到ObjectFactory方法。它的基本要旨是,您总是定义一个通用模式,然后任何数量(也可能是0)的模式“扩展”该通用模式,每个模式产生自己的数据模型。通用模式携带可重用的定义,扩展它的定义使用这些定义组成自己的模型
-
BigQuery在架构中插入(而不是追加)一个新列
是否有一种方便的方法(Python、Web UI或CLI)可以将新列插入现有BigQuery表(已经有100列左右)并相应地更新架构? 假设我想在第 49 列之后插入它。如果我通过查询执行此操作,我将不得不键入每个列名称,不是吗? 更新:建议的答案没有清楚地说明这如何适用于BigQuery。此外,文件似乎不包括 语法。测试确认 标识符不适用于 BigQuery。
-
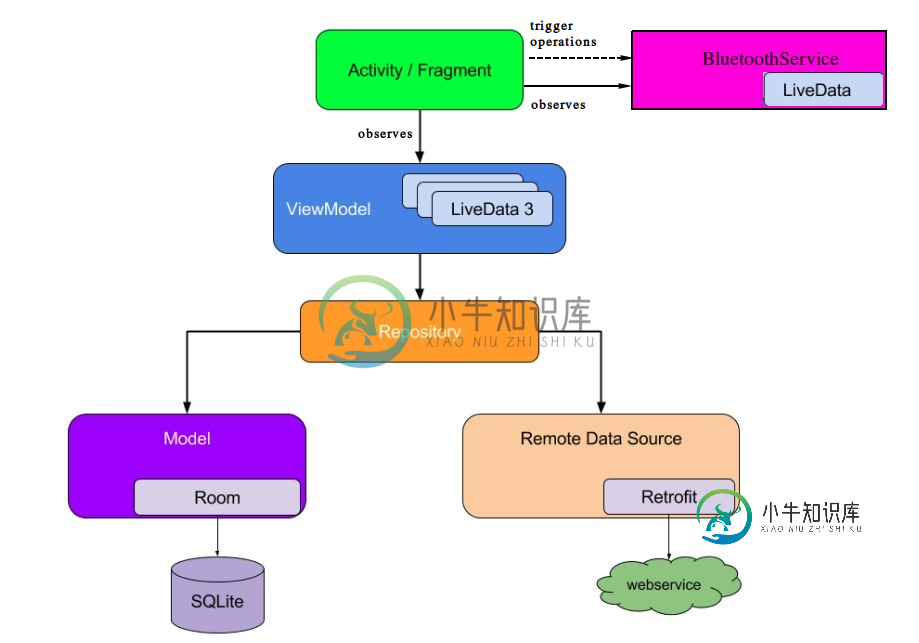 BoundService LiveData ViewModel在新Android推荐架构中的最佳实践
BoundService LiveData ViewModel在新Android推荐架构中的最佳实践我一直在苦苦思考,在新的Android推荐架构中,Android服务应该放在哪里。我想出了许多可能的解决方案,但我无法决定哪一个是最好的方法。 我做了很多研究,但我找不到任何有用的指南或教程。关于在我的应用架构中放置服务的唯一提示是这个,来自@JoseAlcerreca Media的帖子 理想情况下,ViewModels不应该了解Android。这提高了可测试性、泄漏安全性和模块化。一般的经验法则
-
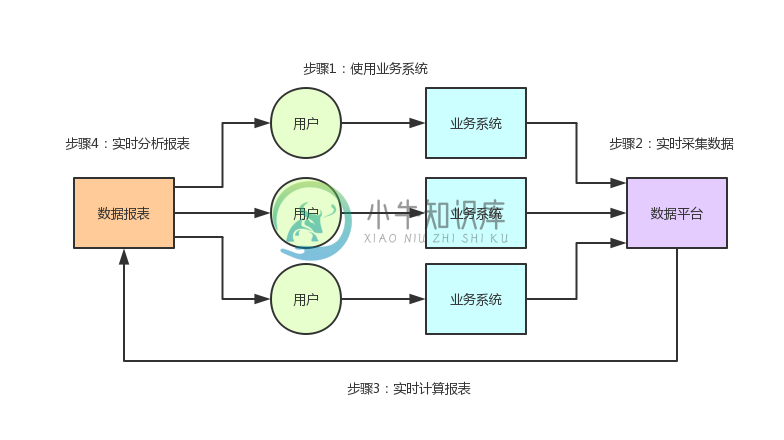 参考NB的Github开源项目,设计自己的架构
参考NB的Github开源项目,设计自己的架构主要内容:一、背景引入,二、商家数据平台的业务流程,三、从0到1的过程中上线的最low版本,四、海量数据存储和计算的技术挑战,五、离线计算与实时计算的拆分,六、持续增长的数据量和计算压力,七、大数据领域的实时计算技术的缺陷,八、分库分表解决数据扩容问题,九、读写分离降低数据库服务器的负载,十、自研的滑动窗口动态计算引擎,十一、离线计算链路的性能优化,十二、阶段性总结,十三、下一阶段的展望,十四、上篇文章的答疑一、背景引入 首先简单介绍一下项目背景,公司对合作商家提供一个付费级产品,这个商业产品背
-
1. 云原生的崛起 - 1.2 云原生架构的定义
现在我们将探索云原生应用架构的几个主要特征,和这些特征是如何解决我们前面提到的使用云原生应用架构的动机。 12因素应用 12因素应用是一系列云原生应用架构的模式集合,最初由Heroku提出。这些模式可以用来说明什么样的应用才是云原生应用。它们关注速度、安全、通过声明式配置扩展、可横向扩展的无状态/无共享进程以及部署环境的整体松耦合。如Cloud Foundry、Heroku和Amazon Elas
-
 百度搜索架构、百度云数据库研发面经
百度搜索架构、百度云数据库研发面经11.17 -----云数据库研发实习生(1小时) 全部是项目相关的提问,体验非常好 1、了解Etcd吗,介绍一下Etcd的存储结构和它的数据一致性如何保证(Raft算法) 2、你知道哪些负载均衡策略 3、知道哪些心跳包检测算法 4、介绍一下你的心跳包检测算法 5、为什么你IM系统的计时器不使用Go原生的计时器 6、聊聊时间轮算法和它环形数据结构实现 7、你IM系统中为什么需要大key删除(从业务
-
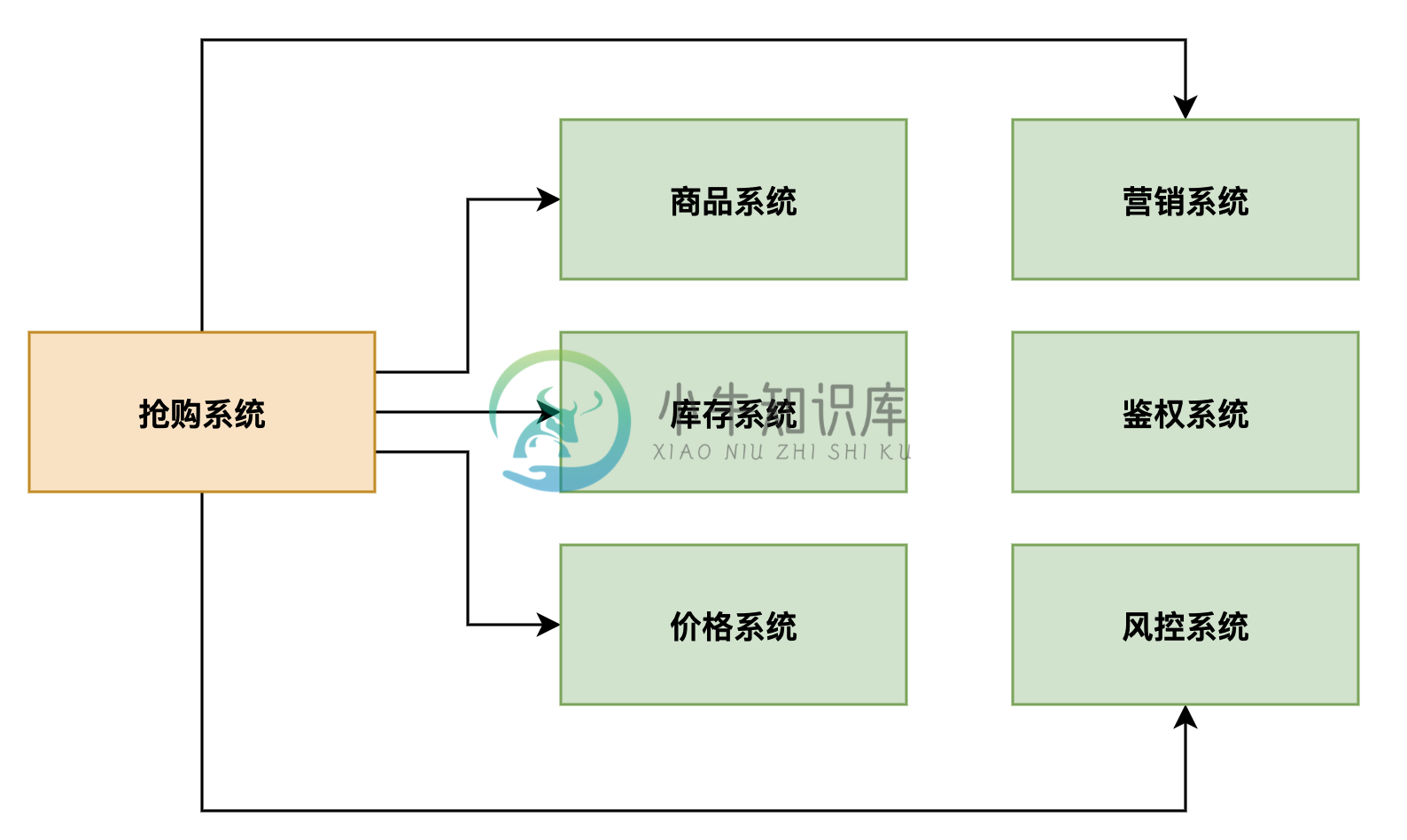 互联网大厂高并发抢购系统架构设计
互联网大厂高并发抢购系统架构设计主要内容:背景,业务架构设计,网络拓扑架构设计,秒杀业务流量洪峰,架构设计优化背景 大家好,这篇文章给大家介绍一个非常经典的去大厂面试经常被问的一个问题,就是瞬时 高并发抢购问题,通常来说,大厂开发的系统经常会遇到一些类似电商秒杀抢购、景点门票高并发抢购、特殊商品(比如口罩)高并发抢购、类似12306的高并发抢票类的系统。 所以经常会问这一类高并发抢购类的问题,这个时候,小伙伴们如果不能有理有据的给出一整套高并发场景下系统可能遇到的各种问题,以及你对应的架构设计和解决方案,
-
 字节跳动 视频架构后端日常实习一面
字节跳动 视频架构后端日常实习一面全程60min 自我介绍 上一段实习拷打(重点) dns流程 dns是使用udp还是tcp协议(都有) 项目主要用了redis来实现了什么功能 redis线程模型 场景题: 如何设计一个直播审核系统(实习相关) 如何设计一个一对多的消息广播系统 算法: 环形链表查找入口 其他问题: 期望的实习时间,能够接受来北京实习吗,离职原因 总结:第一次面大厂,主要围绕实习经历来问,面试官很好一直在引导