《架构思维》专题
-
Swift框架不包含从扩展到通用结构的符号
问题内容: 我在将我的框架与利用该框架的代码链接时遇到麻烦。具体来说,链接器无法找到泛型结构扩展的符号。 这是Optional的扩展之一: 如果代码是在应用程序的主要部分内编译的,则此方法在游乐场或应用程序中非常有用。但是,当我尝试将其编译到框架中时,应用程序(甚至框架的测试)会产生以下链接器错误: 架构i386的未定义符号:“ __ TFSq2orU__fGSqQ__FQQ”,引用自:Optio
-
在PostgreSQL中使用架构的休眠和多租户数据库
问题内容: 我正在开发将来的多租户Web应用程序,它将需要支持数千个用户。该应用程序是在基于Java的Play之上构建的!使用JPA / Hibernate和postgreSQL的MVC框架。 我看了盖伊·纳尔(Guy Naor)关于在Rails中编写多租户应用程序的演讲,其中他谈到了几种多租户方法(数据隔离度随着列表的增加而降低): 每个客户都有一个单独的数据库 一个为每个客户提供单独的架构和表
-
如何使用Struts框架构造自定义错误json响应
问题内容: 我正在使用Struts创建Web应用程序。当请求网址格式不正确时,我想发出如下错误的JSON响应 我已经在使用struts2-json插件来使用JSON序列化响应对象。我应该如何发送JSON错误响应。我可以想到下面的方法。 在操作类中使用错误响应对象,并显式设置所有名称必需的名称值对 然后,我可以只处理序列化在我的。 我是Struts的新手,想知道是否有确定的方法来做到这一点?也许可以
-
jQuery EasyUI框架中的Datagrid数据表格组件结构详解
本文向大家介绍jQuery EasyUI框架中的Datagrid数据表格组件结构详解,包括了jQuery EasyUI框架中的Datagrid数据表格组件结构详解的使用技巧和注意事项,需要的朋友参考一下 基础DOM结构 什么叫“完整的基础DOM结构”,这里“基础”的意思是指这个结构不依赖具体数据,不依赖Datagrid的view属性,只要存在Datagrid实例就会存在这样的基础DOM结构;而“完
-
C/S和B/S两种架构的概念、区别和联系
本文向大家介绍C/S和B/S两种架构的概念、区别和联系,包括了C/S和B/S两种架构的概念、区别和联系的使用技巧和注意事项,需要的朋友参考一下 C/S和B/S,是再普通不过的两种软件架构方式,都可以进行同样的业务处理,甚至也可以用相同的方式实现共同的逻辑。既然如此,为何还要区分彼此呢?那我们就来看看二者的区别和联系。 一、C/S 架构 1、 概念 C/S 架构是一种典型的两层架构,其全程是
-
SOAP肥皂水和可怕的架构类型未找到错误
问题内容: 我第一次使用最新版本的suds(https://fedorahosted.org/suds/),而我却步入了第一步。 现在,我知道这在suds世界中已广为报道(https://fedorahosted.org/suds/wiki/TipsAndTricks#Schema- TypeNotFound 和Python /Suds:未找到类型:’xs:complexType’],但这似乎略有
-
目录,架构,用户和数据库实例之间的关系
问题内容: 为了比较不同供应商(Oracle,SQL Server,DB2,MySQL和PostgreSQL)的数据库,我如何唯一地标识任何对象,我是否需要目录?例如,在Java的DatabaseMetadata中,我至少应指定目录和模式fooPattern。 目录仅仅是数据存储的抽象吗? 问题答案: 在Oracle中: 服务器实例==数据库==目录==所有数据均由同一执行引擎管理 模式==数据库
-
如何快速重命名MySQL数据库(更改架构名称)?
问题内容: 在MySQL手册的MySQL涵盖这一点。 通常,我只是转储数据库,然后使用新名称重新导入它。对于大型数据库,这不是一个选择。显然 做不好的事情,仅存在于少数几个版本中,并且总体而言是个坏主意。 这需要与InnoDB一起使用,后者存储的内容与MyISAM完全不同。 问题答案: 对于 InnoDB ,以下方法似乎有效:创建新的空数据库,然后将每个表依次重命名为新数据库: 之后,您将需要调整
-
“GraphQlError:在合并架构后的类型'query_root'中找不到字段
我已经使用graphql-tools缝合了两个graphqlendpoint。对于一个endpoint模式,它工作得很好,但对于另一个模式,它抛出了这个错误“GraphQlError:field not found in type:'query_root'”。即使我可以在自省的时候看到所有的模式。
-
JPA-EclipseLink-如何在运行时配置数据库架构名称
问题内容: 我实现了一个使用Oracle DB的Web应用程序(JEE6,EJB WebProfile)。我的问题是,我需要更改使用的数据库架构(名称),而无需重新编译/重新打包应用程序。因此,我想要的(这只是一个主意,也许有人有更好的主意),是在服务器内进行一些配置(JNDI),具体说明架构名称。但是,如何配置Eclipse Link在运行时使用其他模式名称? 细节: 目前,我使用该文件指定架构
-
为什么要用flume导入hdfs,hdfs的构架是怎样的
本文向大家介绍为什么要用flume导入hdfs,hdfs的构架是怎样的相关面试题,主要包含被问及为什么要用flume导入hdfs,hdfs的构架是怎样的时的应答技巧和注意事项,需要的朋友参考一下 flume可以实时的导入数据到hdfs中,当hdfs上的文件达到一个指定大小的时候会形成一个文件,或者超过指定时间的话也形成一个文件 文件都是存储在datanode上面的,namenode记录着datan
-
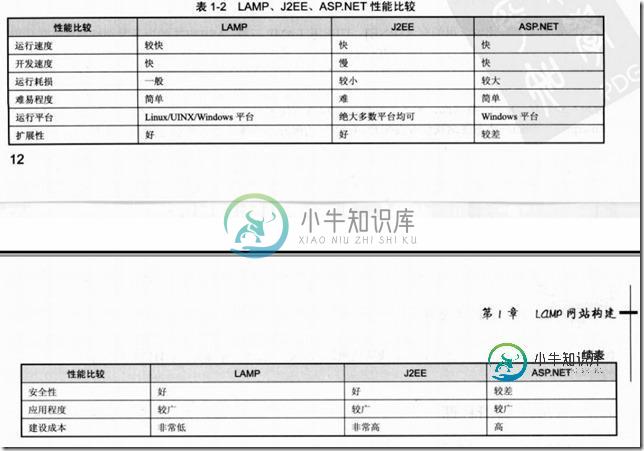 C/S和B/S两种架构区别与优缺点分析
C/S和B/S两种架构区别与优缺点分析本文向大家介绍C/S和B/S两种架构区别与优缺点分析,包括了C/S和B/S两种架构区别与优缺点分析的使用技巧和注意事项,需要的朋友参考一下 一、C/S 架构 1、 概念 C/S 架构是一种典型的两层架构,其全程是Client/Server,即客户端服务器端架构,其客户端包含一个或多个在用户的电脑上运行的程序,而服务器端有两种,一种是数据库服务器端,客户端通过数据库连接访问服务器端的数据;另一种是S
-
猫鼬upsert操作是否会更新/更新默认架构值?
问题内容: 猫鼬架构: Upsert操作: 当我UPSERT 或默认模式值和总是更新不管文档插入或更新。使用时是相同的(当然,我不传递日期)。 我似乎没有发现任何东西可以说明这是否是预期的行为。我希望日期仅在插入时添加,而不更新,除非明确设置。 问题答案: 如果您正在寻找预期行为的“证明”,那么除了源代码本身之外,别无所求。特别是在主要定义内: 因此,您可以看到所有的中间件处理程序都已为每个“ u
-
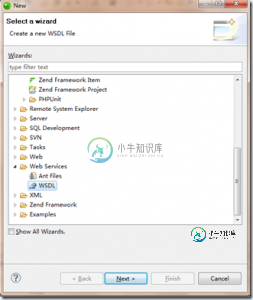 四种php中webservice实现的简单架构方法及实例
四种php中webservice实现的简单架构方法及实例本文向大家介绍四种php中webservice实现的简单架构方法及实例,包括了四种php中webservice实现的简单架构方法及实例的使用技巧和注意事项,需要的朋友参考一下 一:PHP本身的SOAP 所有的webservice都包括服务端(server)和客户端(client)。 要使用php本身的soap首先要把该拓展安装好并且启用。下面看具体的code 首先这是服务端实现: 然后是客户端 就
-
来自Avro架构的Quarkus类自动生成机制不工作
我根据这两个指南创建了一个基于Quarkus 2.1.2的新Kafka Stream项目: https://quarkus.io/guides/kafka-streams https://quarkus.io/guides/kafka-schema-registry-avro 我将一些Avro模式放在文件夹中,并使用Maven构建了项目。构建成功,但在目录中没有任何Java类。 正如新版Quark